
业务背景
上海项目组做项目推广,预估流量在 1000 QPS 左右,膨胀到 Druid 在 3000 QPS 左右,在该查询条件下,Druid 平均响应时长较高,无法满足用户需求。
Druid 与 StarRocks 对比
| 功能 | Druid | StarRocks |
|---|---|---|
| 大数据量支持 | 高 | 高 |
| 高并发 | 高 | 高 |
| 实时数据更新 | 不支持 | 支持 |
| 标准SQL | 有限 | 支持,兼容Mysql协议 |
| 分布式Join | 差,推荐宽表 | 支持 |
| 系统架构 | 架构复杂,依赖ZK等外部组件 | 架构精简,不依赖其他组件 |
| 运维要求 | 高 | 低 |
通过对比可以发现,StarRocks 的适用场景相对于 Druid 来说更加广泛,且运维要求更低,集群只由 FE 和 BE 构成,FE 是 StarRocks 的前端节点,负责管理元数据,管理客户端连接,进行查询规划,查询调度等工作。BE 是 StarRocks 的后端节点,负责数据存储,计算执行,以及 compaction,副本管理等工作。同时 StarRocks 在计算层全面采用了向量化技术,充分发挥了现代 CPU 的并行计算能力,从而实现亚秒级别的多维分析能。在性能测试一节,我们会对 Druid 性能和 StarRocks 性能做更加详细的对比工作。
数据建模
数据建模流程
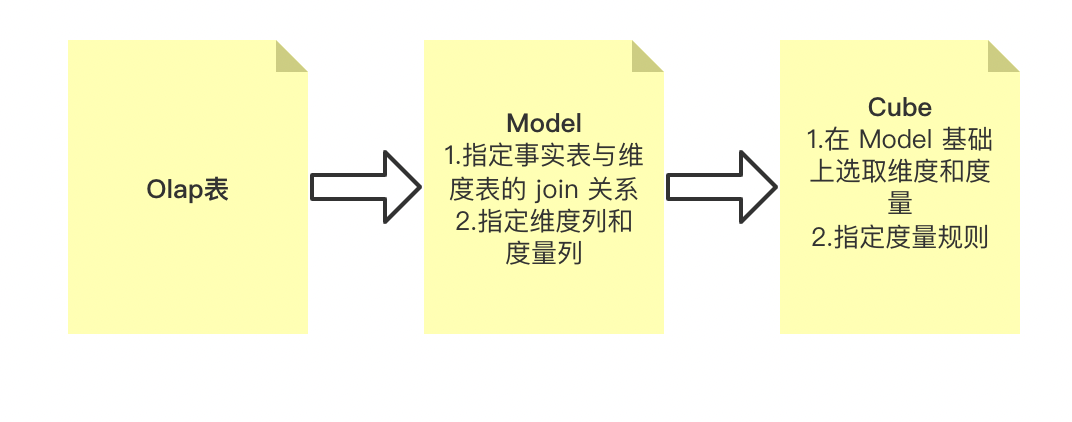
贝壳的数据建模流程是通过一站式指标平台实现的,用户首先将底层 OLAP 表的元数据信息同步到指标平台,然后选取相应的事实表和维度表指定 join 关系,同时指定维度列和度量列创建 Model;在 Model 的基础上再次选取维度和度量,同时指定度量列的度量规则创建 Cube,度量规则包括 sum/count/count distinct/max/min,用户可以通过构建任务自动创建一个 HiveToDruid/HiveToStarRocks 任务,将数据导入 Druid 或者 StarRocks,查询时会首先查询 Druid 和 StarRocks,而不是 Hive。同时根据 cube 的度量列,用户可以创建相应的指标,指定筛选规则,更方便的查看数据信息。
数据查询流程
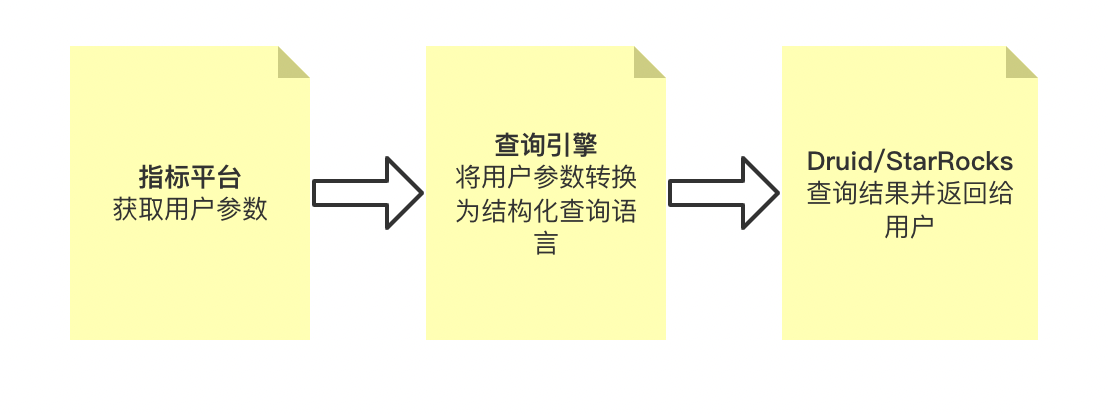
用户在查看指标数据时,指标平台会获取相应的查询参数,由查询引擎将查询参数转换为底层结构化查询语言,发送给 Druid/StarRocks,底层引擎获取结果之后会将结果一层层返回,最终由指标平台返回给用户查看。通过指标平台和QE,用户不需要关心底层使用的是哪个引擎,实现了对底层查询的封装。
用户查询参数示例:
{"startDate":"20220103","endDate":"20220131","dateType":1,"pageNo":1,"pageSize":1,"fitter":[{"dim":"now_agent_no","value":["20087808"]}],"hierarchySwitch":true}
性能测试与调优
压测数据集为线上真实查询,数据集数量为 10 万,查询 SQL 为简单查询。
请求链路为公司测试平台将查询语句发送到 QE 服务,由 QE 服务分别发送到 Druid 和 StarRocks 引擎做查询。
压测结果
TPS:
| 并发线程数量 | Druid | StarRocks |
|---|---|---|
| 10 | 95.56 | 285.49 |
| 50 | 205.8 | 670.53 |
| 100 | 448.32 | 689.41 |
| 300 | 696.28 | 610.51 |
| 500 | 1150.91 | 498.02 |
| 1000 | 1697.73 | 300.23 |
平均响应时间(ms):
| 并发线程数量 | Druid | StarRocks |
|---|---|---|
| 10 | 102.86 | 35.19 |
| 50 | 204.11 | 56.33 |
| 100 | 264.28 | 141.9 |
| 300 | 414.97 | 547.83 |
| 500 | 432.15 | 1054.52 |
| 1000 | 627.55 | 3237.9 |
由压测结果可知,在低负载情况下,StarRocks TPS 较 Druid 更高,平均响应时间较 Druid 更低,但在高负载情况下,StarRocks 平均响应时间明显提高,且 TPS 呈下降趋势。
集群负载情况
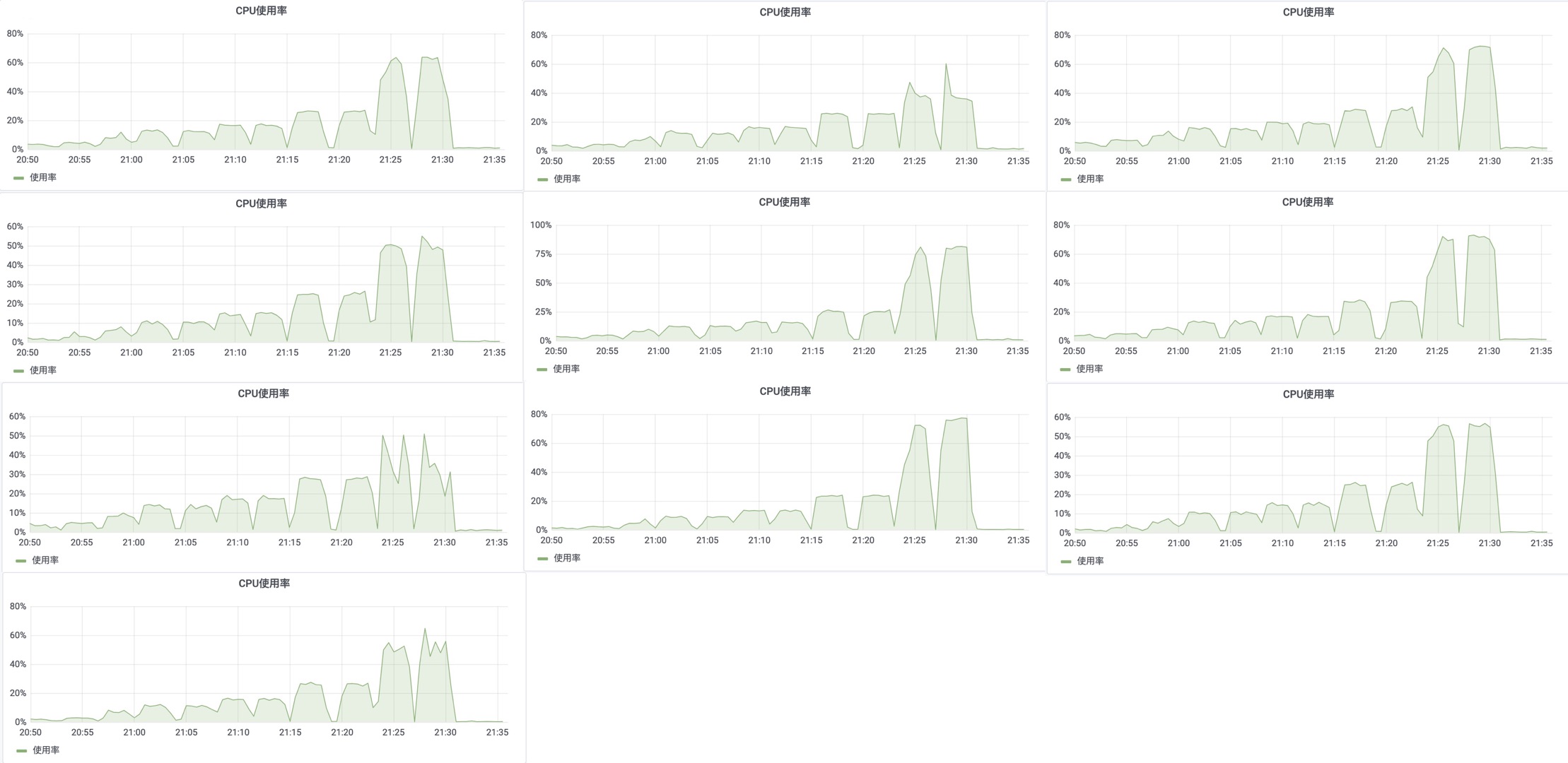
Druid 集群:
StarRocks 集群:
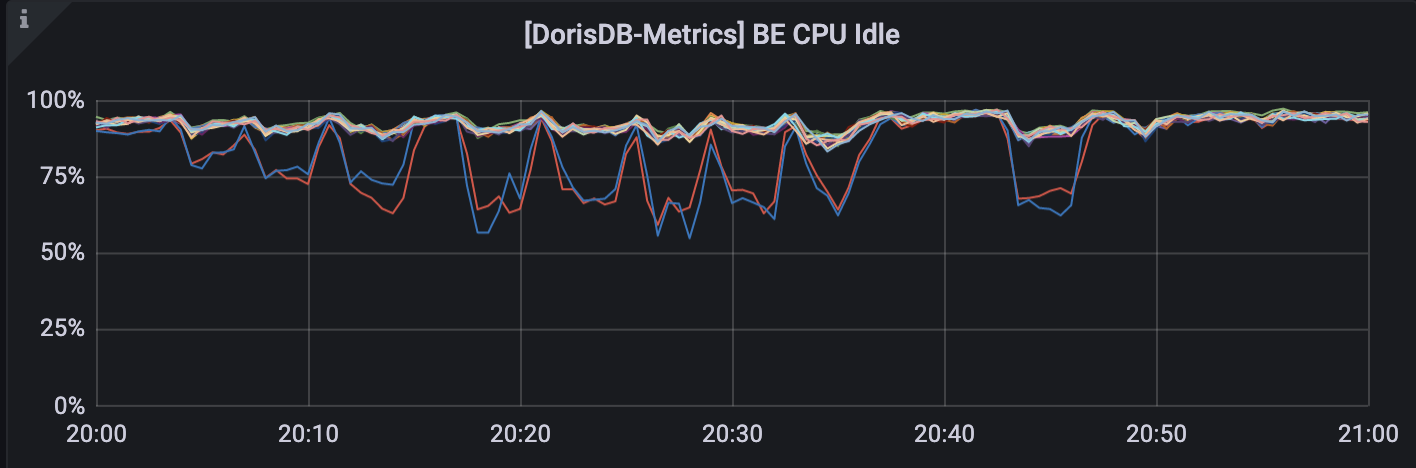
对集群资源进行分析,Druid 集群使用率在高负载下平均在 60% 左右,但 StarRocks 除两台混部了 FE 的机器压力较高外,其他 BE 基本处于低负载运行状态,并未发挥集群的计算能力,因此对 StarRocks 集群性能进行调优。
调优
StarRocks 基本的优化思路包括调整建表的 schema(调整分区、分桶),优化索引,优化 Join,还可以分析 Profile 做一些针对性的优化。
分析 Profile
SQL 语句在 StarRocks 中的生命周期可以分为查询解析(Query Parsing)、规划(Query Plan)、执行(Query Execution)三个阶段。决定 StarRocks 中查询性能的关键一般在于查询规划(Query Plan)和查询执行(Query Execution),Query Plan 负责组织算子(join/order/aggregation)之间的关系,Query Exectuion 负责执行具体算子。
此次压测的查询全部为简单查询,没有 join 和 order,并且查询数据量不大,瓶颈不会出现在 Query Plan 阶段,所以对 Query Execution 阶段的执行结果 Profile 做了分析,Profile 包含了每一步的耗时和数据处理量等数据。Profile 部分数据如下所示:
Instance d534d8a6-5372-11ec-b355-0c42a1a5691e (host=TNetworkAddress(hostname:10.201.39.21, port:9060)):(Active: 6s525ms[6525670632ns], % non-child: 0.00%)
- AverageThreadTokens: 4607182418800017400.00
- MemoryLimit: 16.00 GB
- PeakMemoryUsage: 2.66 KB
- PeakReservation: 0.00
- PeakUsedReservation: 0.00
- RowsProduced: 0
BlockMgr:
- BlockWritesOutstanding: 0
- BlocksCreated: 0
- BlocksRecycled: 0
- BufferedPins: 0
- BytesWritten: 0.00
- MaxBlockSize: 8.00 MB
- TotalBufferWaitTime: 0ns
- TotalReadBlockTime: 0ns
DataStreamSender (dst_id=4, dst_fragments=[d534d8a6537211ec-b3550c42a1a56933]):(Active: 175.805us[175805ns], % non-child: 0.00%)
- PartType: UNPARTITIONED
- BytesSent: 0.00
- CompressTime: 0ns
- IgnoreRows: 0
- OverallThroughput: 0.0 /sec
- PeakMemoryUsage: 2.66 KB
- SendRequestTime: 31.894us
- SerializeBatchTime: 0ns
- ShuffleDispatchTime: 0ns
- ShuffleHashTime: 0ns
- UncompressedBytes: 0.00
- WaitResponseTime: 110.161us
AGGREGATION_NODE (id=3):(Active: 6s525ms[6525498153ns], % non-child: 0.00%)
- GroupingKeys: <slot 8> `t0`.`agent_no`, <slot 9> `t0`.`month`
- AggregateFunctions: sum(<slot 10> sum(`t0`.`paidup_coefficient_amt`))
- AggComputeTime: 0ns
- ExprComputeTime: 0ns
- ExprReleaseTime: 0ns
- GetResultsTime: 0ns
- HashTableSize: 0
- InputRowCount: 0
- PassThroughRowCount: 0
- PeakMemoryUsage: 0.00
- ResultAggAppendTime: 0ns
- ResultGroupByAppendTime: 0ns
- ResultIteratorTime: 0ns
- RowsReturned: 0
- RowsReturnedRate: 0
- StreamingTime: 0ns
EXCHANGE_NODE (id=2):(Active: 6s525ms[6525487661ns], % non-child: 99.96%)
- BytesReceived: 0.00
- ConvertRowBatchTime: 0ns
- DataArrivalWaitTime: 0ns
- DecompressRowBatchTimer: 0ns
- DeserializeChunkMetaTimer: 0ns
- DeserializeRowBatchTimer: 0ns
- FirstBatchArrivalWaitTime: 0ns
- PeakMemoryUsage: 0.00
- RequestReceived: 0.00
- RowsReturned: 0
- RowsReturnedRate: 0
- SenderTotalTime: 0ns
- SenderWaitLockTime: 0ns
- SendersBlockedTotalTimer(*): 0ns
在该 instance 中,耗时最长的阶段是在 EXCHANGE_NODE 阶段,其运行时间为 6s525ms,exchange_node 是作为接收下层节点数据的节点,该节点数量默认为 -1,即表示 exchange node 数量等于下层节点执行实例的个数,但当每个节点数据量较少时,多个 exchange 会造成额外的资源损耗,默认 exchange_node 数量为 22,尝试将相关参数 parallel_exchange_instance_num 设置为 1。修改前后部分执行计划结构如下所示:
关闭 Profile 上传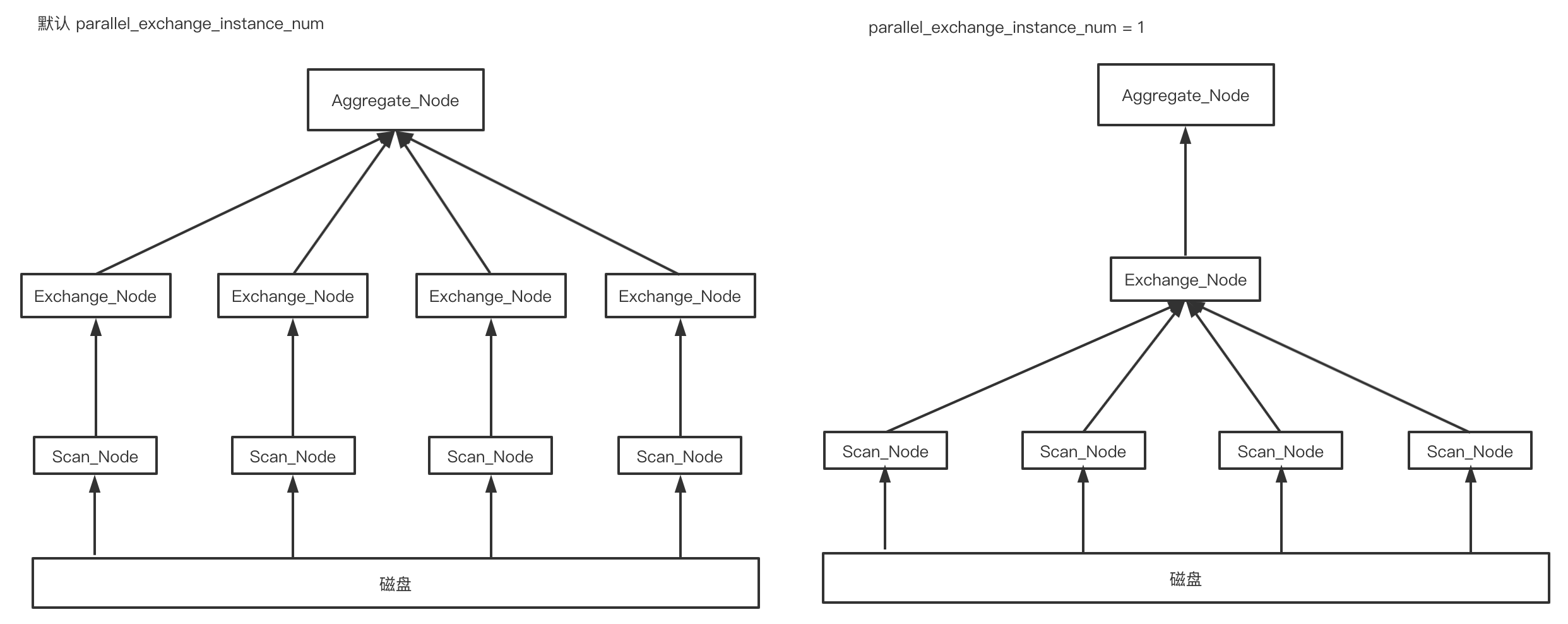
在第一次压测时,为了分析 StarRocks 的性能瓶颈,Profile 上传是处于打开状态的,即 BE 会将所有查询的执行过程发送给 FE,但发送 Profile 会产生一定的网络开销,对高并发查询场景不利,因此将 is_report_success 还原为默认情况,只有在查询发生错误时,BE 才会发送 Profile 给 FE,用于查看错误。正常结束的查询不会发送 Profile。
优化索引
StarRocks 对数据进行有序存储, 在数据有序的基础上为其建立稀疏索引,索引粒度为 block(1024行)。稀疏索引会选取 schema 中固定长度的前缀作为索引内容, 目前 StarRocks 选取 36 个字节的前缀作为索引。对数据集分析发现,大多数 SQL 查询都包含字段 agent_no,但该字段位置较为靠后,因此将该字段前置,使其能充分利用 StarRocks 索引。
优化建表 schema
查询指标全部为 SUM 类型的聚合数据,因此表类型选择聚合模型(Aggregate Key),同时对分桶数和副本数作出了调整。分桶是实际物理文件组织的单元,分区和分桶应该尽量覆盖查询语句所带的条件,这样可以有效减少扫描数据,提高并发。根据前面的分析,多数查询包含 agent_no,因此将 agent_no作为分桶字段。同样,副本数也会影响查询时的并发,我们分别对 3 副本和 20 副本做了压测实验。
调优后压测结果
| bucket | 副本数 | exchange | profile | 最高TPS | 最高TPS 时的平均响应时间(ms) | 最高TPS时的并发线程数 |
|---|---|---|---|---|---|---|
| 1 | 3 | 默认(22) | on | 3430.47 | 81.76 | 300 |
| 1 | 3 | 1 | on | 5625.47 | 90.67 | 500 |
| 1 | 3 | 1 | off | 5788.47 | 51.29 | 300 |
| 1 | 20 | 1 | off | 9203.26 | 32.69 | 300 |
| 8 | 3 | 1 | off | 11999.33 | 25.21 | 300 |
| 8 | 20 | 1 | off | 9918.49 | 30.63 | 300 |
| 16 | 3 | 1 | off | 19375.81 | 16.19 | 300 |
| 16 | 20 | 1 | off | 9956.13 | 29.84 | 300 |
PS:由于 profile 和 exchange_num 变更需要重启 QE,会影响线上服务,因此调优后的压测选择通过 JDBC 压测,StarRocks 支持 Session 级别的参数修改,在查询 SQL 中加入参数控制即可。测试 SQL 示例:
SELECT /*+ SET_VAR(parallel_exchange_instance_num = 1) */ t0.agent_no AS agent_no, t0.month AS MONTH, SUM(t0.xxx) AS shishouxishuyeji FROM olap.olap_xxx AS t0 WHERE (t0.date BETWEEN 20201130 AND 20211130) AND t0.agent_no = '22228xxx' AND t0.corp_code NOT IN ('SH8888') AND t0.business_code = '0101' AND t0.role_name = '房源方' GROUP BY t0.agent_no,t0.MONTH LIMIT 0, 100000
结论
通过对 Profile 的分析,针对性的将 parallel_exchange_instance_num由默认修改为 1,最高 TPS 由 3430 提高到了 5625,提高了近 2000 左右。将 Profile 上传功能关闭后,虽然最高 TPS 变化不大,但平均响应时间降低了接近一半,这也表明 Profile 上传功能确实会占用一部分性能开销。
之后我们对 1 bucket 3 副本、1 bucket 20 副本、8 bucket 3 副本、8 bucket 20 副本、16 bucket 3 副本和 16 bucket 20 副本分别做了对比测试,结果表明 16 bucket 3 副本时的性能是最好的,最高 TPS 能够达到 19375,而此时的平均响应时间只有 16.19。
通过压测数据我们可以发现,在 3 副本条件下,bucket 数量越多,性能是越好的;但在 20 副本条件下,增大 bucket 数量却并不能带来性能的提升,基本都在 9000 TPS 左右。之后我们又在 8 bucket 1 副本的情况下做了一次压测,结果如下:
| 并发数 | TPS | 平均响应时间 |
|---|---|---|
| 100 | 8946.44 | 11.83 |
| 300 | 18988.42 | 16.82 |
| 500 | 23223.84 | 24.21 |
| 1000 | 23778.09 | 38.2 |
压测结果表明:8 bucket 1 副本下的压测性能比之前所有情况都要好,表明在查询数据量较小的前提下,副本数量越少,性能是越高的,但在实践中,应该优先保证数据的可用行,因此在该业务条件下,设置为 16 bucket 3 副本应该是最优选择。
通过压测结果可知,在该条件下,StarRocks 性能是远高于 Druid 的。
参考
https://docs.StarRocks.com/zh-cn/main/administration/Query_planning#查询分析