为了更快的定位您的问题,请提供以下信息,谢谢
【详述】问题详细描述
【背景】做过哪些操作?
【业务影响】
【是否存算分离】
【StarRocks版本】例如:1.18.2
【集群规模】例如:3fe(1 follower+2observer)+5be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:48C/64G/万兆
【联系方式】为了在解决问题过程中能及时联系到您获取一些日志信息,请补充下您的联系方式,例如:社区群4-小李或者邮箱,谢谢
【附件】
- Profile信息,如何获取profile
- 并行度:show variables like ‘%parallel_fragment_exec_instance_num%’;
show variables like ‘%pipeline_dop%’; - pipeline是否开启:show variables like ‘%pipeline%’;
- 执行计划:explain costs + sql
- be节点cpu和内存使用率截图
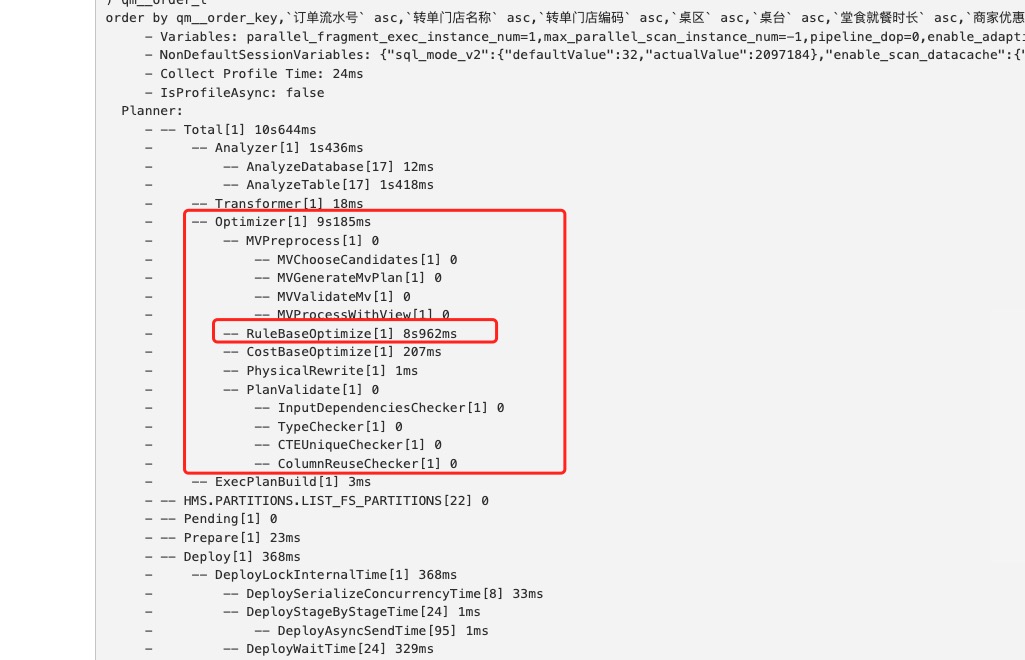
starrocks版本3.2.9。 执行查询hive_catalog的数据,sql脚本复杂,存在很多表的join操作,执行时长比较久,查看proflie是优化器那里耗时比较久
profile.txt (775.9 KB)