
形如 select *
from a
join b
on a.secucode=b.secucode
where a.id=1316944337
的查询,a和b表都属于jdbc catalog中同一个库中的表,实际执行时,将b表的全部数据拉到了starrocks与a表的数据进行join,非常耗时。可否做到将整个join计算直接推到源库执行或者使用runtimefilter以减少b表的IO数据量
(实际场景,可能会执行a join b join c, 其中a,b在jdbc catalog同一个库中,c表为 starrocks内表)
补充下,runtimefilter部分生效,耗时是因为未将in filter等谓词转换为where条件,下推到数据库中过滤数据,导致拉取全量数据,IO耗时大。请问,是否有优化的方法?
贴个profile
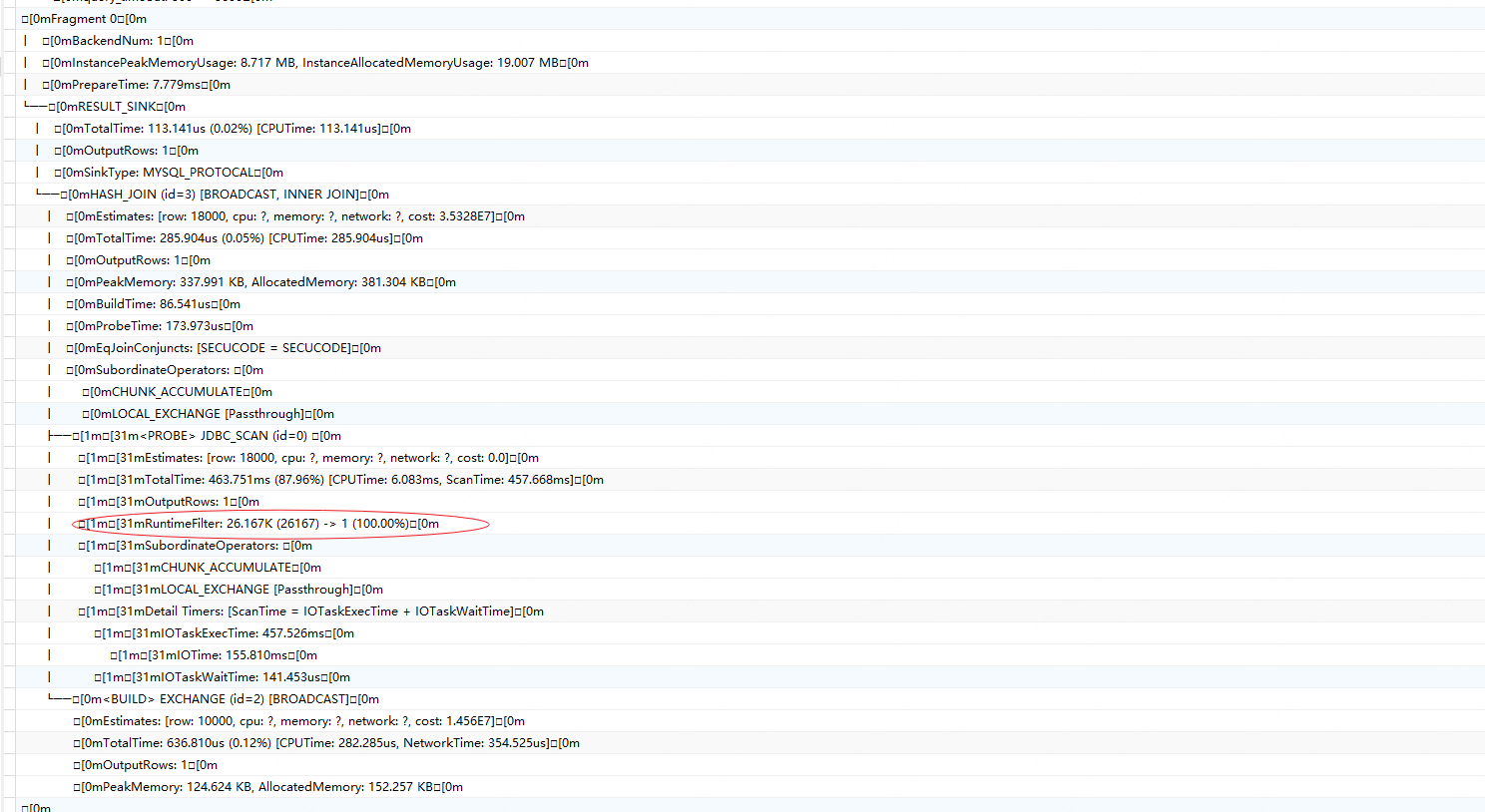
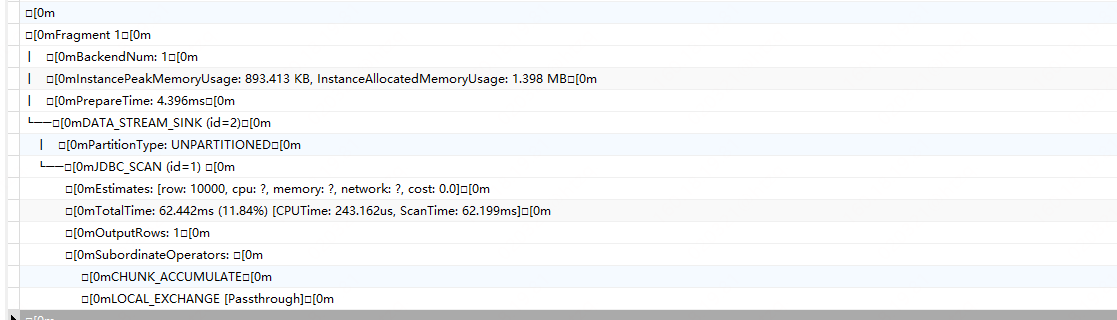
最好控制下让build side 产生的rows < 1024
build side 产生的rows只有一条,通过主键ID精确过滤的
probe 表建一个 mysql 外表试一下,我记得mysql 外表是支持改写成 runtime filter的
probe表是mysql外表的情况下,这种是可以把runtimefilter的谓词推到源库过滤的。
使用jdbc catalog的这种情况,可以也做到将谓词下推到源库过滤吗