

作者:易点天下数据平台团队
易点天下 是一家技术驱动发展的企业国际化智能营销服务公司,致力于为客户提供全球营销推广服务,通过效果营销、品牌塑造、垂直行业解决方案等一体化服务,帮助企业在全球范围内高效地获取用户、提升品牌知名度、实现商业化变现。
目前,易点天下 累计服务客户超过5000家 ,其中包括华为、阿里巴巴、腾讯、网易、字节跳动、百度、快手、爱奇艺、SHEIN、Lazada 等知名企业。
易点天下始终秉持"科技使世界变得更平"的企业使命,积极采用大数据和人工智能技术来落地和推动业务的发展。
随着公司业务的扩展,我们的 数据分析工作遇到了一些痛点 :
-
数据处理需求日益增多: 每天需要处理几十T 、近千亿的数据量。
-
数据分析的复杂度提高: 如用户留存、 LTV 这一类的复杂指标,往往需要多表关联查询和实时查询,目前应用的组件不能满足业务的查询需求。
-
技术组件较多: 公司有多个数据分析平台,采用的技术组件也非常多,包括 ClickHouse、Kafka、Flink、Spark、Hive 等,运营维护成本较高。
4.当前架构基本以离线为主, 实时数据处理架构薄弱 。
经过现状分析后,我们开始设计数据仓库的标准化规范,并寻找一款 集实时离线为一体 的数仓统一解决方案 ,对数仓进行统一规划和建设。
#01
数仓建设规范
—
我们从 数据分层、业务类和数据域定义、数据指标、数据模型规范、模型衡量指标 五个方面进行了数仓的规范建设。
-
数据分层: 包括数据引入层 ODS 、明细数据层 DWD 、汇总数据层 DWS 、数据应用层 ADS 及维度层 DIM 。
-
业务类和数据域定义: 此定义主要用于规范数据仓库处理数据的范围,以及处理数据的业务类型。
-
数据指标规范: 包括原子指标(如点击、访问、消费金额等)、复合指标(如点击率、跳出率、投资回报率等)、派生指标(如7天账户消费金额、去年账户余额总和等)。
-
数据模型规范: 包括命名规范、存储规范、数据规范三个方面;统一规范的数据模型能大幅提升开发维护效率,避免不必要的数据质量问题。
-
模型衡量指标: 包括命名规范性和数据完整性、 中间层表的增长比例、应用层 ADS 跨层访问(穿透)、 较多的 ADS 表共性逻辑未下沉、应用层跨集市依赖五个方面。
#02
技术选型
—
在对数仓进行了标准化规范设计后,我们需要一个 集实时离线为一体的数仓统一解决方案 ,通过数仓建设,来解决以下问题:
-
数据存储的规范性
-
数据模型的复用性
-
数据模型的耦合性
-
数据的完整性
-
数据查询效率
-
数据成本可控
基于此,我们对市面上常见的数据库产品做了选型对比:
1. 查询性能对比
我们主要对 ClickHouse 和 StarRocks 的查询性能做了对比,在 SSB 单表和用户经常碰到的低基数聚合场景下对比了 StarRocks 和 ClickHouse 的性能指标。采用一组 16core 64GB 内存的云主机,在 6 亿行的数据规模进行测试。
得益于向量化执行引擎、优秀的 CBO 优化器、物化视图、Runtime Filter 等各方面的优化,StarRocks 的查询性能表现非常优异,下面测试为各种引擎在不同 SQL 下花费的时间, ClickHouse 的整体查询时间是 StarRocks 的 2.26 倍。
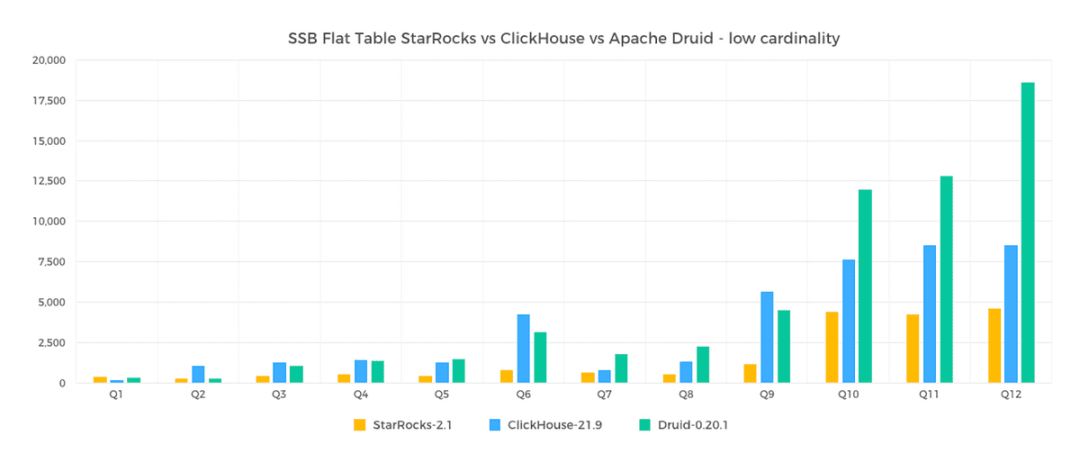
图1 各种引擎在不同SQL下花费的时间
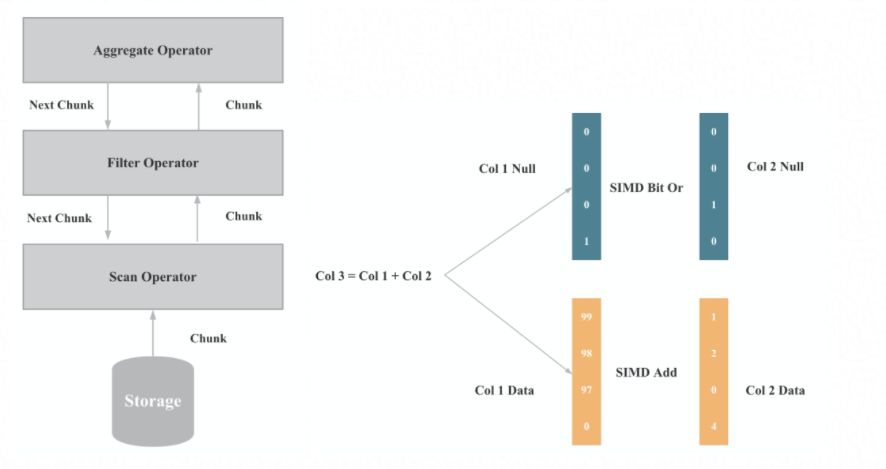
图2 StarRocks 通过实现全面向量化引擎,按照列式的方式组织和处理数据,充分发挥了 CPU 处理能力
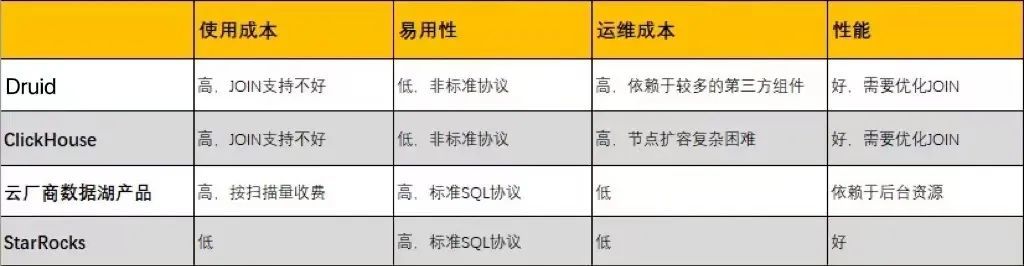
2. 使用与运维对比
除了查询性能,我们从使用成本、易用性、运维成本等方面,对比了几款比较热门的产品,最终我们计划将基于 ClickHouse 等其他数据库产品的查询迁移到基于 StarRocks 来构建数据仓库。
#03
技术架构
—
数据平台目前处理的数据涉及公司多个产品,每日处理全球增量数据几十T,近千亿条记录,跨云跨地域的数据也给数据处理带来不少挑战。
目前我们已经针对 BI 系统开展了基于 StarRocks 的数据仓库的建设,随着经验的积累,后期会推广到数据平台所有项目的数据场景中。
目前数据平台以实时流和离线处理两条方式同时向 StarRocks 数据仓库中进行数据 Load 。下图是目前数据平台在数据分析中的主要流程架构,如图所示,架构中我们自研了数据治理平台(DataPlus)用于数据监控提高数据质量, 维护元数据血缘等数据的拓扑结构,自动化建模。另外我们还自研了分布式的跨云调度系统(EasyJob),用于系统便捷的处理多云环境下的数据依赖和调度。
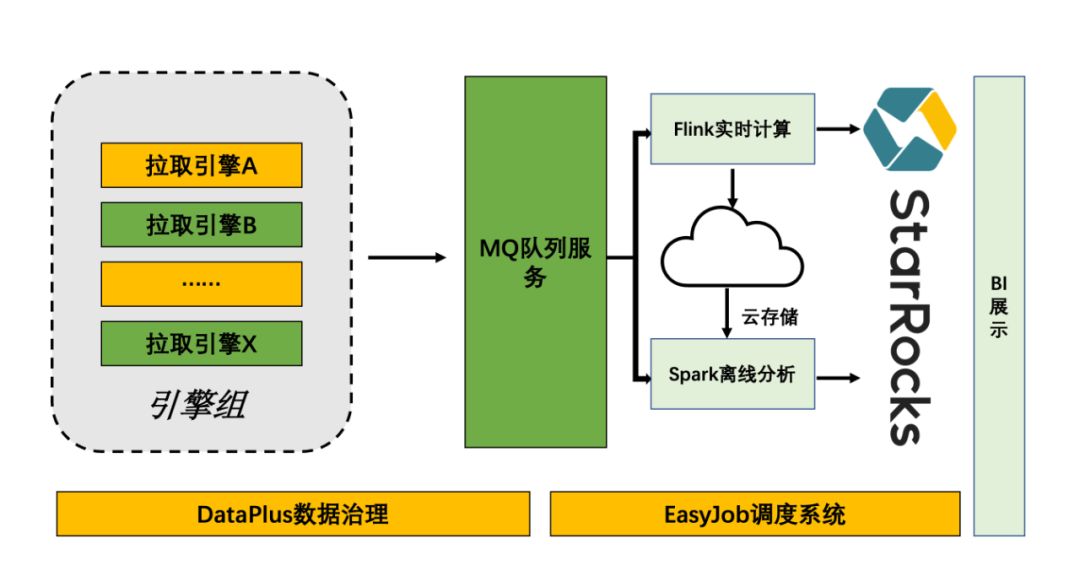
离线数据导入通过 EasyJob 定时调用 Broker Load 的方式导入 StarRocks 。
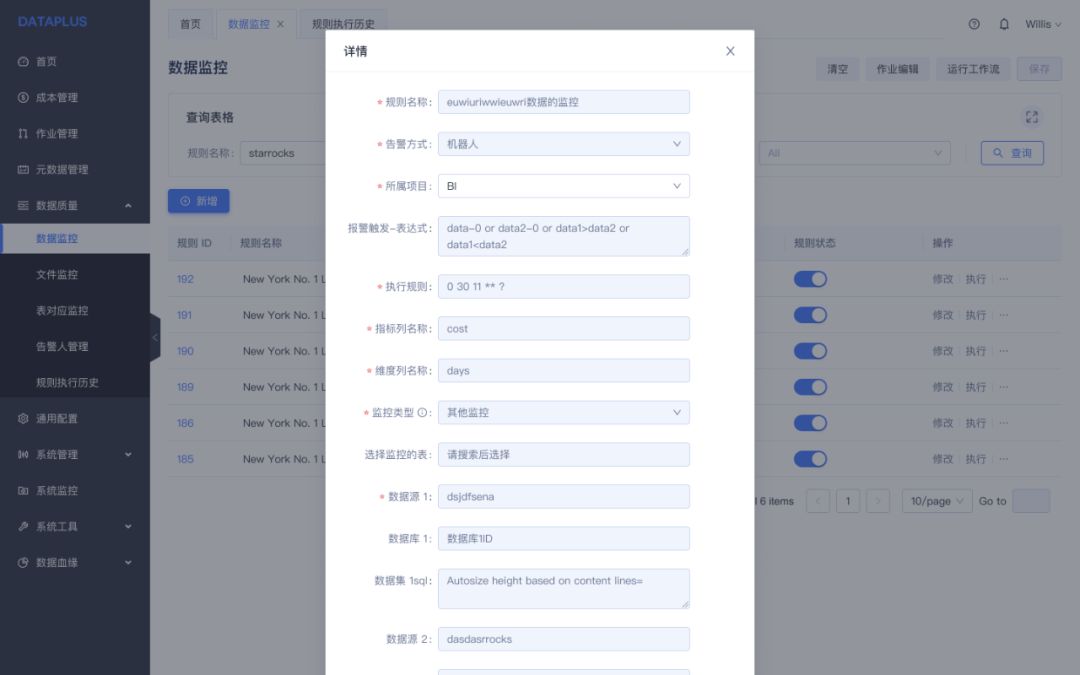
通过 DataPlus 系统,我们对 StarRocks 中的数据和云存储数据进行了定时的一致性校验,保证数据的一致性。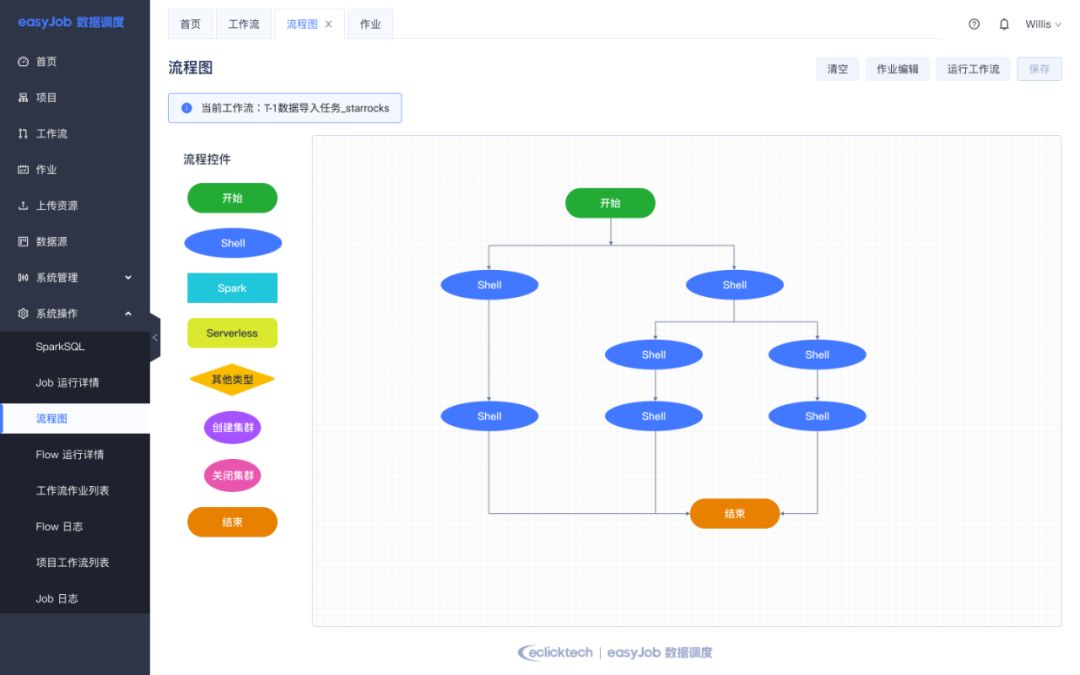
我们一直寻找一种实时和离线一体的数据处理解决方案,实时离线数据处理完后会进入 StarRocks 进行全流程建模,基于 StarRocks 进行湖仓一体结构的搭建。
最底层 ODS 基于外部数据源建立,数据存储在外部云存储上例如 OSS,S3,ODS 等,然后通过调度系统定时触发上层表的生成,另外,DWS、ADS的部分表模型,也可以借助于物化视图方式实现,提升构建和查询效率。
整体数据流动架构如下:
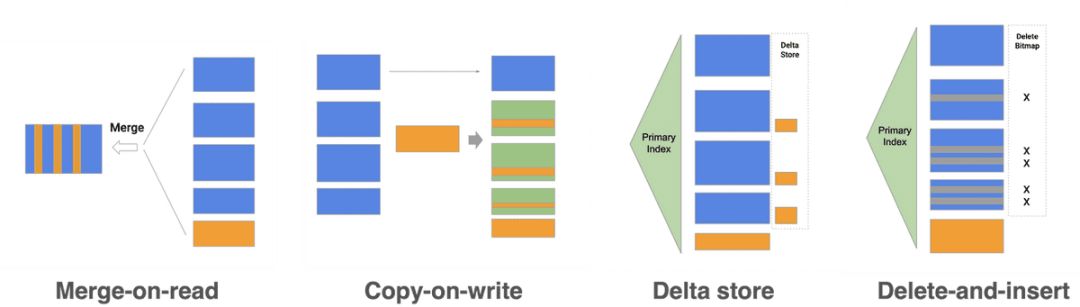
StarRocks 能够支持秒级的导入延迟,提供准实时的服务能力。StarRocks 的存储引擎在数据导入时能够保证每一次操作的 ACID。一个批次的导入数据生效是原子性的,要么全部导入成功,要么全部失败。并发进行的各个事务相互之间互不影响,可以提供Snapshot Isolation事务隔离级别。StarRocks 存储引擎不仅能够提供高效的 Append 操作,也能高效的处理 Upsert 类操作。使用 Delete-and-insert (Merge_on_write)的实现方式,通过主键索引快速过滤,消除了读取时 Sort merge 操作,同时还可以充分利用其他二级索引。在大量更新的场景下,仍然可以保证查询的极速性能。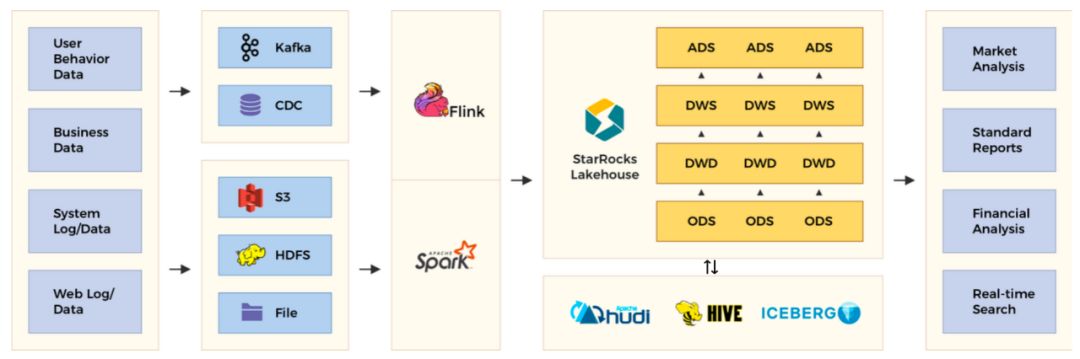
#04
智能数据建模
—
通过元数据、数据血缘体系的建立,未来我们可以通过让建模规范、建模质量等规则自动化,形成线上系统的自动化建模功能,自动化建模生成标准 SQL ,最终在 StarRocks 中定时执行生效。下图是建模过程和 DataPlus 中功能的映射。建模自动化的好处就是可以限制人为建模的不规范操作,最大程度的优化模型和成本。
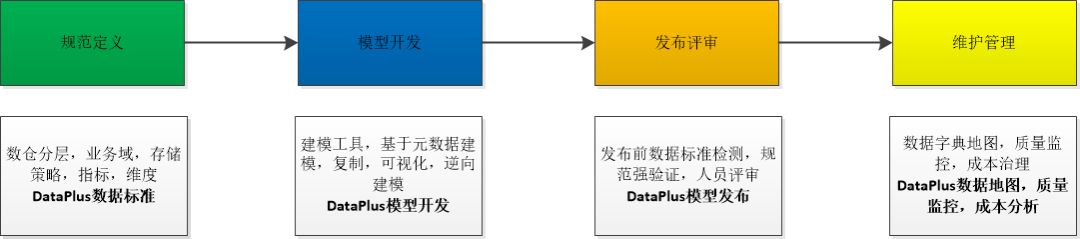
模型定义后,对模型生成效率的优化至关重要,不一样的解决方式会影响模型的查询生成效率,模型的复用度也会影响用户使用体验。
我们在建模中针对下面三个模型进行了基于 StarRocks 的重点构造,大大提高了查询效率。
物化视图
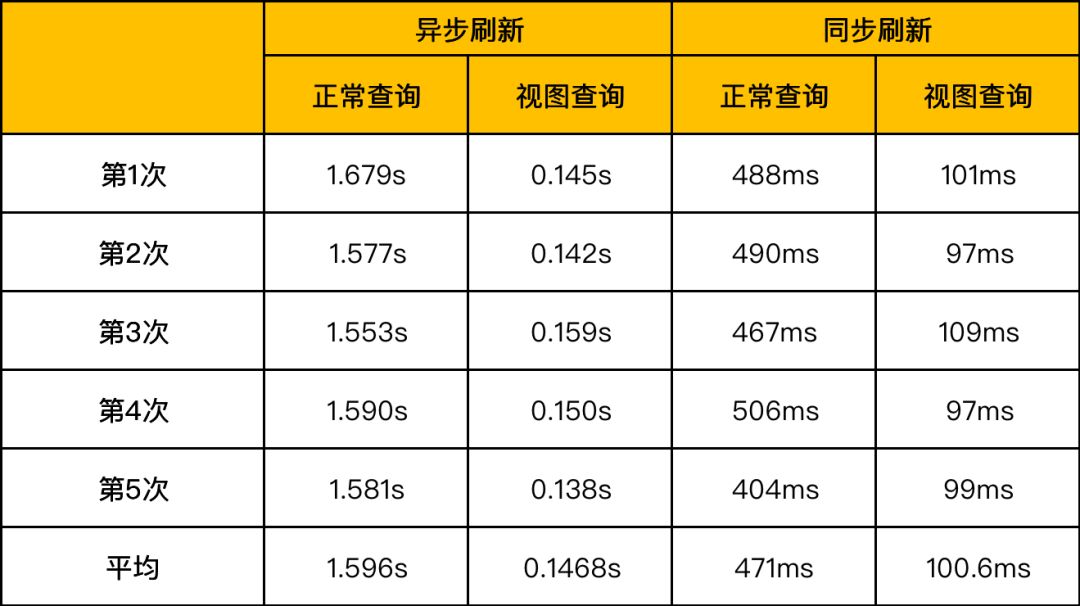
在数仓建模中我们大量采用了物化视图来加速和生成 DWS 以上数据层,StarRocks 当前支持单表同步、多表异步以及对 SQL 的透明改写能力,未来还会提供多表同步等更多能力,可以从建模和提速两个方面对业务场景提供帮助。
针对不同的刷新方式,我们进行了两组查询对比,如图所示,通过物化视图能够获得更快的查询性能体验,有了物化视图,我们可以从复杂的数据加工工作中解放出来,更加专注于数仓模型本身。
分析模型
统一的模型 SQL 设计,高阶函数的应用,可以提高查询性能50%以上。例如我们主要针对下面三种常见分析模型设计了标准建模 SQL ,未来将通过此标准自动建模,提升查询效率。
- 行为分析的应用 – 用户留存分析
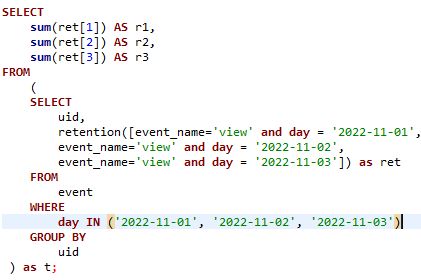
对于用户留存的分析,经常会在多个条件下获取用户的行为状态,我们采用了 retention 函数来分析,大幅提升了查询分析的效率。
例如:要清楚的了解 event=view 并且时间在2022-11-01、2022-11-02、2022-11-03条件下的用户情况;传统的方式需先进行 event=view and date=’ **- -**’ 条件判断,然后进行合并,但是 retention 函数的出现直接简化了相应的建模过程,通过 retention 函数,可以直接获取 event=view 以及三个日期条件下的行为,并且以数组的形式进行展示,之后可以通过对数组的聚合操作,进行相应的行为分析。
- 行为分析的应用 – 漏斗分析
针对用户的转化分析场景,例如需要分析在一定的时间窗口中,用户在一系列连续行为下的相关行为,可以直接采用 StarRocks 中的 window_funnel 进行建模,实现高效的漏斗分析。该函数可以从事件链中的第一个条件开始判断。如果数据中包含符合条件的事件,则向计数器加 1,并以此事件对应的时间作为滑动窗口的起始时间。如果未能找到符合第一个条件的数据,则返回为 0 。在滑动窗口内,如果事件链中的事件按顺序发生,则计数器递增;如果超出了时间窗口,则计数器不再增加。如有多条符合条件的事件链,则输出最长的事件链。
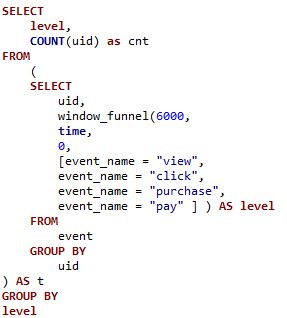
如上图 SQL ,可以计算在规定时间窗口内,用户在 view/click/purchase/pay 连续行为下的相关数据,最终返回不同的连续行为级别下对应的用户数量。
- 行为分析的应用 – 路径分析
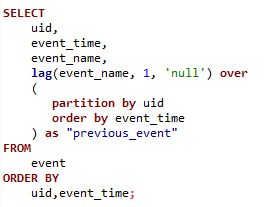
针对用户前后行为路径分析场景,例如需要针对用户前后行为进行对比分析的场景,可以综合考虑采用 StarRocks 支持的ROW_NUMBER(),LEAD(),LAG()等窗口函数进行建模分析。如下是一个针对用户前后行为分析的具体案例,可以针对用户的 event 以及前置 event 进行展示:
#05
建设成果
—
公司数仓建设过程分为四个阶段:
-
数据仓库规范建立和技术调研选型 。
-
性能压测: 经过测试,StarRocks 和之前我们应用的 ClickHouse 有2.2倍以上的提升。Join 查询更是有数倍的提升,小时级导入时间的数据量可以在1分钟完成 Load ,保证离线查询效率。
-
试点运行: 经过迁移,部分业务使用效率得到大幅提升,以往比较的复杂自主 SQL 查询、TP95 查询都可以在5s返回。支持交互式 SQL 自助分析。
-
全面部署 :在公司其他数据类产品中应用 StarRocks ,并完善监控等集群的自动化运维。
在 BI 系统中经过一段时间的使用,StarRocks 的应用已经进入第四阶段,未来公司会将更多的业务切入到StarRocks,并结合 DataPlus 的智能建模、表热度分析等数据治理,相信性能和成本会达到更理想的状态。同样我们也期待 StarRocks 在新版本中可以提供更丰富的功能。