

近年来,在证券服务逐渐互联网化,以及券商牌照红利逐渐消退的行业背景下,中信建投不断加大对数字化的投入,尤其重视数据基础设施的建设,期望在客户服务、经营管理等多方面由经验依赖向数据驱动转变,从而提高服务水平和决策效率。
因此,在公司总部和各分支机构,包括经纪、资管、投行等业务部门,以及稽核、审计、财务、法务等职能部门,对自助分析、多维分析、固定报表和 API 数据服务等形式的用数需求一直在不断增长。
#01
需求背景
为了推动整体数字化建设和数据治理工作,中信建投已经在2019年搭建了基于 Apache Hadoop (以下简称 Hadoop)体系的数据湖,将大量历史数据迁移到 Hadoop 上,用 Apache Hive (以下简称 Hive)对数据进行加工处理,所有的查询计算都通过 Presto 执行。但是,该方案在最近两年数据量快速增长、业务场景多样化发展的趋势下逐渐无法适用。具体而言,中信建投目前在数据查询分析中主要存在以下痛点和需求:
1)数据加工链路复杂
在数据分析的流程上,数据部门通常是首先用 Presto 做即席查询,再通过 Hive 进行数据加工,最后将加工过后的数据下发到各部门的 Oracle 或 MySQL 事务型数据库,业务人员在事务数据库里对下发数据进行查询和分析。整个过程需要在三套系统之间进行数据交换,且三套系统使用的 SQL 语法也不一致,需要不同人员进行开发维护,从而产生了多种问题:
-
数据开发和维护成本高
-
数据口径可能不一致,导致数据应用结果不准确
-
用数需求难以得到及时满足,通常要“T+1”才能给到数据报表
2)大数据量下性能不足,查询响应慢
中信建投目前大部分的数据都存储在 Hive 中,业务部门在进行自助分析时通常涉及的相关数据量较大,而 Presto 在大数据量、多表关联查询时会出现响应比较慢,甚至无法获得查询结果的问题,无法满足单表及多表复杂查询场景下响应的及时性。此外, Presto 因为资源隔离不足会出现应用抢占资源的情况,不能很好支持高并发的查询请求。
3)大量实时数据分散在各个业务系统,无法进行联合分析
由于中信建投内部存在非常多的业务系统,各业务系统相互独立且数据会不断更新,而这些实时数据无法更新到 Hive 中,导致业务数据之间不能及时打通进行联合分析。
4)缺少预计算能力加速固定查询
固定报表和 API 数据服务为各业务提供包括数据汇总结果、明细查询、数据接口在内的多项能力,而基于固定数据查询的可视化报表通常数据查询量大、计算维度较多,一个看板页面涉及大约一两百个 SQL 语句,整体运算效率低下。针对这种情况,中信建投希望通过预计算实现查询加速,并且要求开发工作轻量化且资源消耗较低。
#02
引入StarRocks 构建统一查询服务平台
通过综合对比数据库即席查询、实时分析性能、预计算能力、数据联邦技术,并且结合中信建投已经在 Hadoop 体系中有大量投入,不希望做大规模数据搬迁的具体情况,将 Hive 外表查询支持、SQL 语法及函数的兼容性等方面纳入选型考虑, 中信建投最终选择引入 StarRocks 来构建统一的查询服务平台,满足各部门的用数需求 。
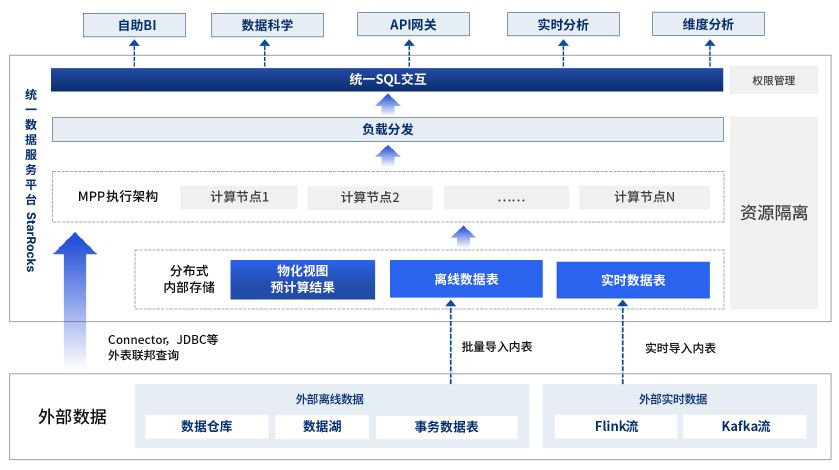
图:中信建投统一数据查询服务平台
作为一款高性能全场景的分析型数据库,StarRocks 使用 MPP 架构、可实时更新的列式存储引擎等技术实现 多维、实时、高并发 的数据分析。StarRocks 既支持从各类实时和离线的外部数据源高效导入数据,也支持不做数据转储,便可直接通过外表形式分析查询数据湖的数据,统一的 SQL 交互将数据分析结果或物化视图预计算结果分发到各个数据应用, 为中信建投实现了三套系统使用功能的整合以及数据应用流程的简化。
具体而言,针对中信建投的痛点问题, StarRocks具备如下优势 :
1)在性能方面
针对大规模数据下自助 BI 敏捷高效的需求,StarRocks 向量化执行引擎,全面实现了 SIMD 指令,保证查询和向量化导入可以充分利用单机单核 CPU 的处理能力;StarRocks 自研的 Pipeline 执行引擎,使得 StarRocks 可以应对更高的并发查询,充分利用单机多核 CPU 的处理能力,与此同时可以更优雅的进行 CPU 时间分片调度从而实现资源隔离的功能;StarRocks 采用大规模并行处理(MPP)架构,可以充分利用多机多核的集群资源,保证查询性能可以线性扩展;并用基于成本的优化器 CBO、Runtime Filter、延迟物化、全局低基数字典等多种⼿段实现极致查询性能。
2)在外部表联邦查询方面
StarRocks 可通过创建外部表的⽅式,在 StarRocks 读取其他数据源,如 MySQL, Elasticsearch , Apache Hive 等外部表中的数据, 从⽽打破数据的隔离。
以 Hive 外表功能为例,中信建投可以将其 Hive 中的离线数据导⼊ StarRocks 中进⾏⾼性能分析查询。同时,StarRocks 也可以支撑湖仓一体联邦分析,将离线数据与实时数据进⾏关联,打通不同数据存储间的壁垒,从⽽⽀撑业务分析时在数据湖中进⾏数据探查和极致分析的需求。
3)在预计算方面
为了实现固定报表的加速,StarRocks 引入预计算的手段,通过创建单表物化视图,在保证明细查询的同时可以加速聚合指标查询;通过多表物化视图、外表物化视图等方式,提供更灵活的按需建模能力,复用常见查询有效优化了复杂 SQL 计算效率, 满足用户对固定维度聚合分析以及原始明细数据任意维度分析的多样需求。
#03
落地后的效果与价值
1) 大数据查询性能得到显著提升
采用 StarRocks 内部表加速明细数据关联查询,实现了上亿级别数据量大表关联秒级响应, 内表查询效率提升10倍以上 , 外表查询效率提升1倍以上 ,完全满足大数据量下查询分析及时响应的需求;
2)预计算能力降低了固定报表加工成本
采用 StarRocks 预计算能力可以将固定报表和 API 数据服务响应速度提升1倍以上。多表物化视图、外表物化视图、Query Rewrite 等高阶功能,可以有效降低数据建模成本,使得“直面分析,按需加速”成为可能。
3)降低数据迁移成本,提升数据管理和使用效率
StarRocks 基于 Hive 外表做查询,减少了底层数据的迁移成本,并实现了实时数据联通分析。同时,以 StarRocks 为统一数据服务入口,降低了整体数据查询和加工的复杂度,提升了数据管理和使用效率。
#04
项目经验总结
中信建投进行数字化转型过程中已经部署了大部分的数据基础设施,但是已有的基于 Hadoop 构建数据湖的体系在近两年来暴露出众多问题,已经无法匹配业务的发展速度。中信建投基于自身业务需求和已有技术架构情况选择以 StarRocks 构建统一数据服务入口的实践,为同类型券商企业提供了以下经验建议 :
1)分析型数据库的选型需要 充分考虑企业自身的用数需求 ,以及现有数据平台的技术架构,选择符合自身实际情况的数据库是获得较好的落地效果的关键。例如,中信建投大部分的数据都存储在 Hive 中,StarRocks 提供的类 Presto 的外表查询功能可以避免数据迁移增加的额外成本,同时也很好地满足了公司的用数需求。
2)随着企业数据库规模不断增长,以及分析场景更加复杂,分析型数据库需要不断提升数据查询分析的性能,以及针对固定报表、自助 BI 等各种应用场景,提供场景化解决方案、生态工具,才能满足用户在数据查询分析方面功能和性能的复杂需求。