

作者:大润发大数据团队
自 1998 年在上海开设第一家大型超市以来,大润发已在中国大陆地区成功开设近 500 家综合性大型超市,覆盖全国 29 个省市及自治区达 230 多个城市,年销售额过千亿。大润发优鲜、淘鲜达、饿了么、天猫超市线上平台用户达到 6900 万。活跃用户超过 1650 万,一线城市平均每店日均线上订单量突破 2000单。
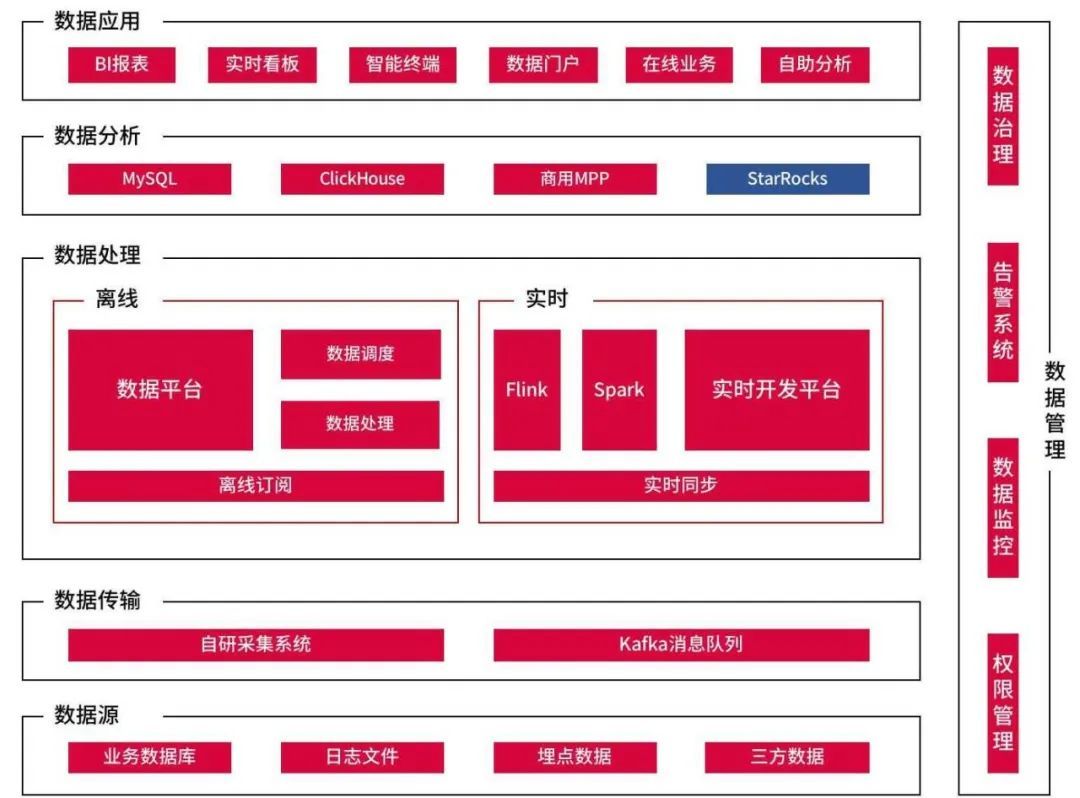
作为国内大型连锁量贩超市的先导者,大润发在物流仓储、商品管理等领域很早就引入了大数据技术进行智能决策分析,帮助优化管理精度、提高管理水平。大数据平台也跟随技术浪潮多次迭代升级,沉淀出一整套特有的数据子系统和大数据处理方案。
大润发大数据业务起步较早、数据累积和历史组件较多,同时为了保证技术的前沿性,因此逐步发展出了多分析引擎的架构。一方面可以根据各类型引擎的特点处理合适的在线数据产品,一方面也可以根据各类引擎的技术优势及使用效果调整使用场景调节使用权重。
然而,随着业务需求的多样化、复杂化以及数据系统的改造升级,原本一些下放门店库的查询需求统一收归中心化的数据中台处理,导致高并发且复杂的查询场景出现频次激增。面对此种场景,无论是能力还是效率,现有的分析引擎都显得力不从心,复杂查询性能出现明显不足。因此亟需一款能够适应高并发低延时的查询引擎,作为我们大数据框架 OLAP 分析平台的全新动力。
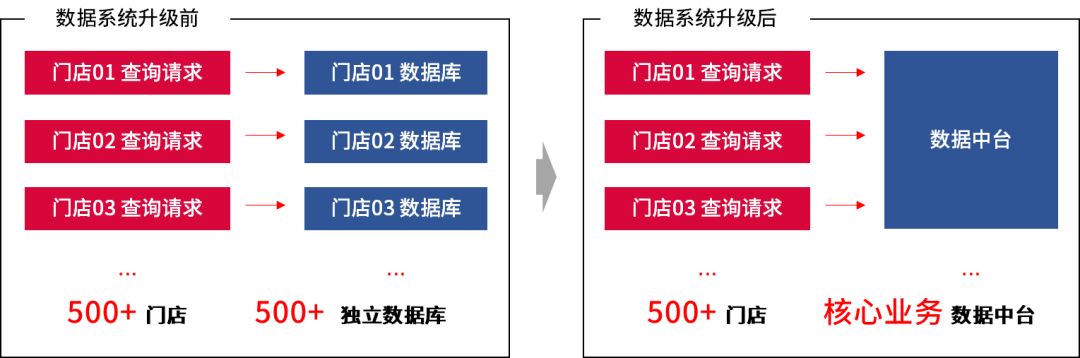
#01
OLAP组件选型
—
1. 选型要求
对于新的 OLAP 引擎,我们有如下几点期待:
-
社区活跃的开源框架,运维成本不会太高;
-
能支持多类型 Join,大表 Join 性能要优秀;
-
要支持高并发处理查询,且查询延迟低,这也是我们最核心的诉求;
-
要能够支持大规模数据的导入导出,且能与现有数据平台相互兼容;
-
数据模型灵活,使用场景全面;
-
支持预计算技术。
2. 选型对比
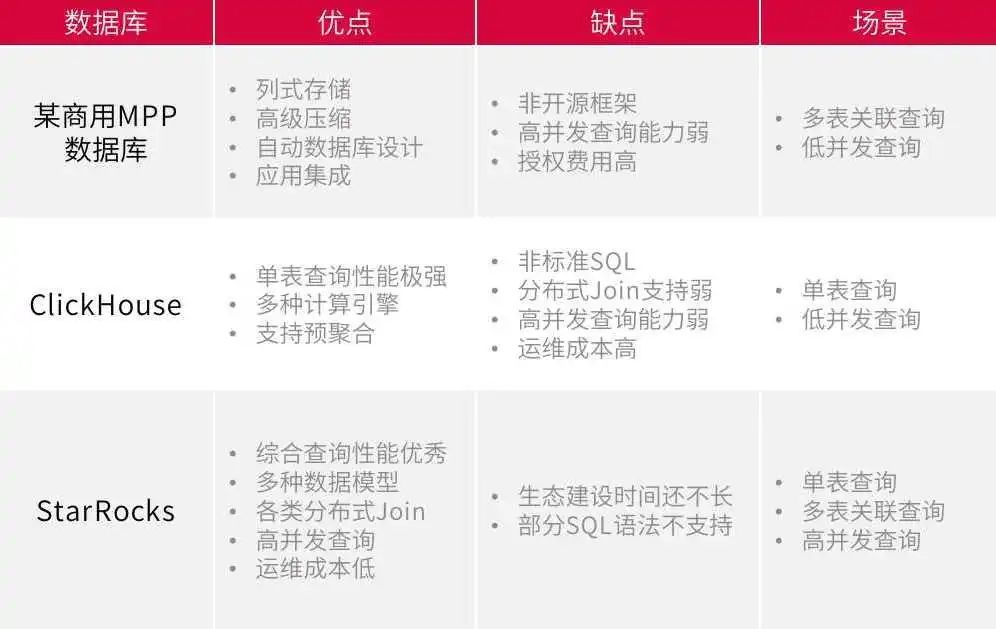
我们对时下流行的组件进行了前期调研,StarRocks 以出色的性能、良好的兼容、极简的部署吸引了我们的注意。
StarRocks 与大润发数据平台框架现有组件的特点及应用场景对比如下:
3. 组件测试
为了验证 StarRocks 实际使用性能是否能够达到预期,我们采用了学术界和工业界广泛使用的星型模型测试集 Star Schema Benchmark(简称 SSB 测试集),在本地测试集群(3FE+3BE架构)上进行了单表查询的系列测试。
单表查询的测试结果如下:系列测试结论如下:
-
在 SSB 测试集的 13 个查询中,StarRocks 的整体查询性能是 ClickHouse 的 2 倍多;
-
在 SSB 测试集的 12 个低基数查询中,StarRocks 的整体查询性能为 ClickHouse 的 1.1 倍。
4. 组件部署
从测试结果来看,StarRocks 的性能非常优秀,组件架构也非常精简。经过简单的部署改造,StarRocks 增强了我们 OLAP 分析引擎高并发场景下的处理能力。
#03
实践案例
—
1. 离线应用
1、建模
大润发的核心业务依托于各大中小门店的进、销、存经营数据,该部分数据以业务流程型单据明细为主。通常的逻辑是,业务中台系统的门店明细数据经过自研采集系统同步到数据中台中,经过 ETL 清洗、转换、聚合处理,输出到 BI 报表进行结果展现。
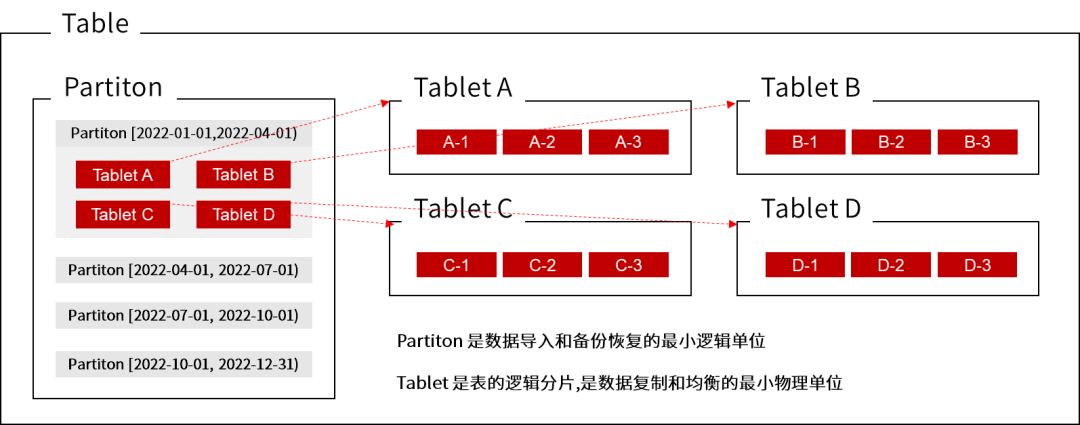
在应用外部 OLAP 分析引擎的场景中,我们会把业务维表和部分分析逻辑放到引擎库中。引入 StarRocks 改造后,我们也进行了初步探索,针对 StarRocks 的四种模型规定了使用场景,并特别对明细模型的建模细化了两种应用方式:一种是不用分区的维度表,一种是需要按同步时间分区的明细表。

建表还需要注意一些分区分桶问题,官方建议单个分桶的大小在 1-10G,此时查询性能较好。所以如果源表数据量过大或过小,可以适当调整分区或分桶数,以达到最佳的性能状态。
2、同步
得益于 StarRocks 兼容 MySQL 协议,能够与我们现有的数据平台整合,进行简单的配置就可以进行数据的同步和开发。
不同于以往的 Apache Hive 或者 MySQL 数据库,StarRocks 通过动态分区导入数据的前提是分区必须已被创建,而其本身无法根据分区字段实时动态创建分区。这里有两种方法解决:
-
可以根据建表语句 Properties 配置中的参数开启动态分区功能,让 StarRocks 调用底层常驻线程预创建分区;
-
可以关闭 StarRocks 的动态分区,通过数据平台执行预定义 SQL 语句进行分区创建操作。
在刷数的时候,对于特定历史分区的刷数操作,可以使用 StarRocks 的临时分区功能实现无感刷数。
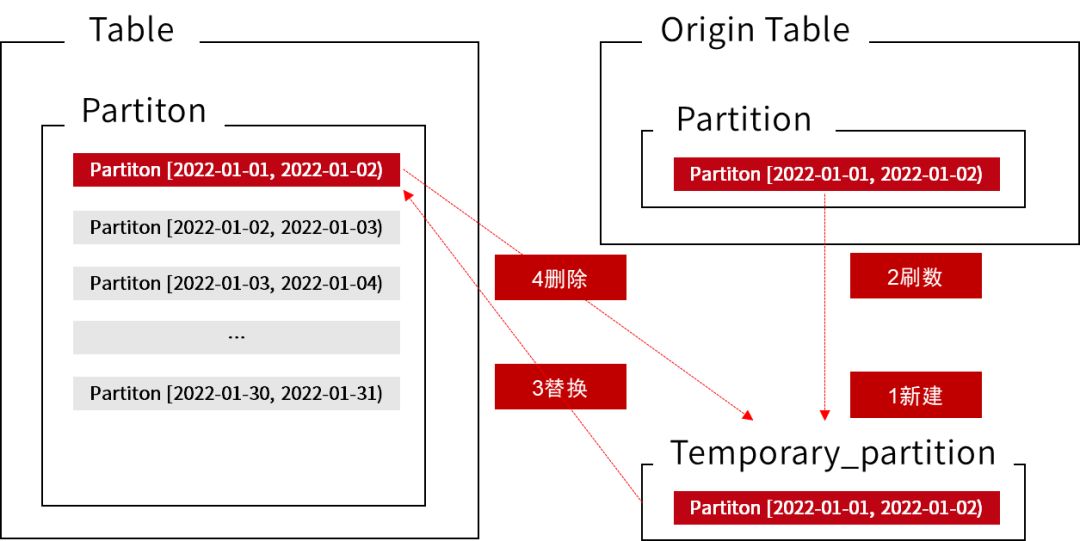
3、查询
我们所使用的 BI 报表工具,对前端报表查询控件的操作都会在底层转化成预定义的 SQL 向 StarRocks 查询,返回结果再进行 Web 渲染。由于采用的是自动生成的 SQL 语句,需要注意在 SQL 生成的过程中,是否对表的索引字段自动添加了转换函数,从而导致索引失效的情况。
4、性能效果
报表上线后,我们对实际的查询效果也做了持续的观察和分析。包括复杂查询在内,总体 99% 查询延时在 150ms 左右,QPS 9000+ 的高并发场景下仍能较为稳定执行,达到了导入的预期效果。
2. 实时探索
1、兼容测试
实时团队也测试了 Apache Flink+StarRocks 的兼容性,凭借官方的 Flink-connector-starrocks 依赖,可以很好实现实时需求的改造。不过需要注意的是:
1.、1.11 版本的依赖没有 Source 读取方法,仍需使用 JDBC 读取。
2、 1.13 以后版本的依赖有 Source 和 Sink 方法。
这两个方法的底层实际是转为 Stream Load 方法进行写入写出,对比 JDBC 的单 FE,可以实现多 FE 数据传输,性能更强。所以如果有实时的应用场景,推荐 Flink 1.13+ 版本配合对应的依赖取得更好的使用体验。
2、其他设想
我们曾尝试使用 Apache Kafka+Routine Load 的方式将数据导入 StarRocks,期望结合 StarRocks 本身的物化视图预计算实现实时 Join,从而直接替代 Apache Spark/Flink 这类专业的实时引擎。遗憾的是,我们基于 2.1.6 版本的物化视图功能比较基础,尚无法实现更为复杂的表间关联操作,而 StarRocks 2.4 版本已开始支持并逐步完善多表物化视图功能。
#04
实践总结
—
1. 优点
-
性能卓越:StarRocks 的单表性能不输 ClickHouse,多表 Join 的延时对比我们现有的的组件又有着较大优势,即便不做特定的优化,也能有较好表现,这是十分难得的。
-
运维简单:StarRocks 舍弃了传统多组件的架构形式,FE+BE 的结构十分精简,部署较为便捷。而运行上的稳定可靠,使得对运维的资源消耗非常低。
-
插件丰富:开发者维护了一些较为实用的插件和工具,可以进行一键部署、日志结构化等。如果这些功能后期能够稳定嵌入 StarRocks 后续版本中,应该可以更好优化使用体验。
-
社区活跃:开源社区有长期稳定版和快速迭代版可以自由选择,版本升级操作也较为容易。同时有中文社区论坛和官方群可以随时进行问题反馈获得答疑,这一点是要胜过很多竞品的。
2. 不足
这里基于 2.1.6 版本提出两点使用中的困扰:
-
权限管理不足:StarRocks 的用户角色功能有待改善,例如该版本只能在创建用户时授予角色,不能授予用户多角色,删除角色后用户权限依然保留。庆幸的是,在不久后的 3.0 版本中,StarRocks 将实现完整的 RBAC,并丰富更多权限项目,从而解决这一问题。
-
预计算功能泛用性不强:物化视图作为预计算的特色功能,运用场景较为基础,条条框框局限过多,比如不能实现多列聚合运算,不能实现多表 Join 等,使用起来难以做到如臂使指的效果。StarRocks 2.4 版本的异步物化视图功能已经在逐步解决这一困扰。
我们通过实践发现,StarRocks 能够很好地解决大润发数据分析中的一些痛点问题,能够解决问题的工具就是好工具。StarRocks 以其优异的特性,得到大润发数据团队的一致好评。而其开发团队从善如流的服务态度,高效迭代的技术努力,无不彰显着他们在这片市场耕耘的勃勃雄心,相信 StarRocks 在不远的未来,能够结出他们所期待的光明。
