

作者:向伟靖,37 手游大数据开发工程师
37 手游使用 StarRocks 已有半年多,在此期间非常感谢 StarRocks 团队的积极协助,感受到了服务速度和产品速度一样快,辅导我们解决了产品使用上的一些问题。
首先介绍下 37 手游的背景。37 手游主要专注于移动端游戏发行和游戏运营,成功发行运营了《斗罗大陆:魂师对决》、《云上城之歌》等游戏。数据是游戏运营的基石,查询效率对业务人员的体验感受非常重要,因此提升查询效率是我们团队一直努力的目标。
本次分享主要内容包含:37 手游的数据架构、StarRocks 对数据架构产生的影响,以及 StarRocks 在用户画像实践上的应用。
#01
业务和技术的痛点
—
在业务上,我们遇到了以下几个主要痛点:
第一,数据分析性能不足。因为我们游戏用户维度指标特别多,数据需要复杂关联查询,才能得到相应的分析指标。有时候甚至还需要传说中的 SQL Boy 帮忙取数。还有就是高并发查询时间周期特别长的数据,响应特别慢,例如 LTV 这些分析指标,就需要查询数据周期特别长。这些也是业务经常反馈比较多的问题。
第二,实时分析场景不足。主要体现在运营推广等数据实时清洗出现延迟,影响到游戏运营和广告投放的策略。
同时,我们还面临几项主要的技术难点:
第一,大数据产品复杂组件多,运维成本高。
第二,实时同步 MySQL 数据到 OLAP 查询引擎秒级查询。当前部分业务数据存储在 MySQL 上需要同步到 OLAP 进行提速查询,所以技术需要保证业务数据一致性、时效性和查询性能。
第三,千万级维表数据关联查询性能低下。
第四,业务发展使数据快速膨胀,线性扩容成本高。
#02
旧数据架构和 OLAP 选型
—
首先,我们先看看以下 37 手游的数据架构。这是一个比较经典的实时离线架构。从下往上看,离线传统的 Apache Hadoop(以下简称 Hadoop)集群加上了数据湖 Apache Hudi(以下简称 Hudi)组件和 Apache Kafka(以下简称 Kafka)消息队列组成存储层,Apache Hive(以下简称 Hive)和 Apache Flink(以下简称 Flink)组件组成实时离线处理引擎层,分析层就是众多且复杂的 OLAP 组件,业务层更多是提供接口、 BI 报表展示等功能。其中分析层 OLAP 组件众多且数据分析相对分散,就意味着使用这些组件成本高。
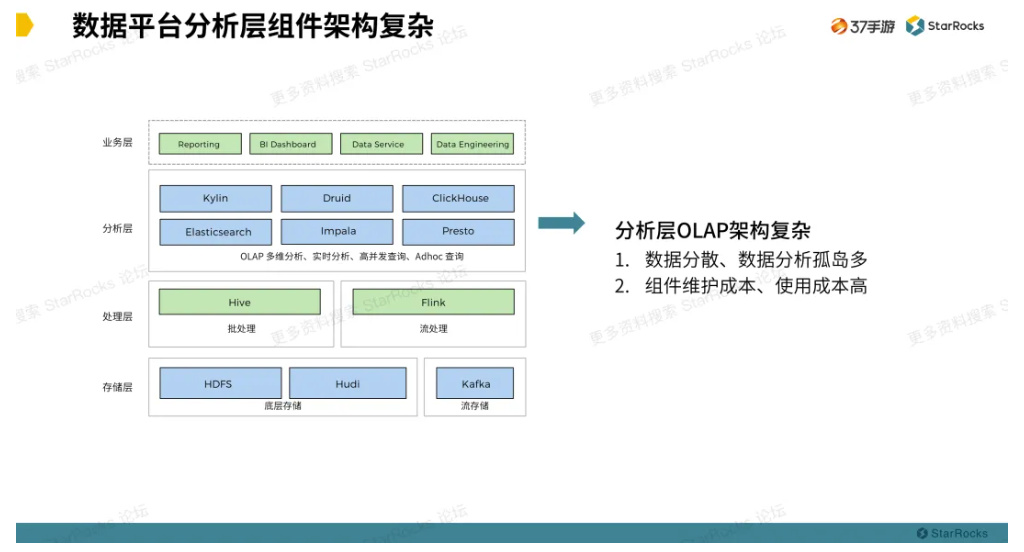
以下是我们用过的 OLAP 组件,各有优缺点:
1)Apache Kylin(以下简称 Kylin):作为国产第一个 Apache 顶级项目,当时让国内众多开发者看到了原来我们可以离开源项目这么近。如今国内众多优质开源项目百花齐放,比如我们使用的海豚调度系统、StarRocks 等。Kylin 利用空间换取时间的方式,提前预构建好数据进行快速查找。这就使得构建数据需要消耗大量计算资源和存储资源,时效性也比较差,慢慢变得不太适用 37 手游的场景。
2)ClickHouse:这匹俄罗斯黑马的单表查询性能特别强悍,但是随着业务的深入使用,从单机到集群构建,发现其运维复杂,且稳定性和数据一致性也有问题。这个时候就要根据我们的业务诉求开始调研其他 OLAP 组件。
3)StarRocks:我们是从技术博客上发现了 StarRocks。随着对 StarRocks 的系统架构和产品特性深入了解后发现,其产品能力基本解决了我们的痛点。主要体现在以下四点:部署监控运维简单,兼容 MySQL 协议和标准 SQL 语法,大表多表关联查询性能优异,支持不同数据来源高效导入和支持数据实时更新。
经过业务数据导入进行测试,StarRocks 基本满足我们的测试性能基准。当前线上部署了3 台 FE 和 5 台 BE , FE 的硬件配置单台 8核 32G, BE 的硬件配置单台 32核 128G。当前集群相对较小,后面随着业务迁移会逐渐申请扩容。
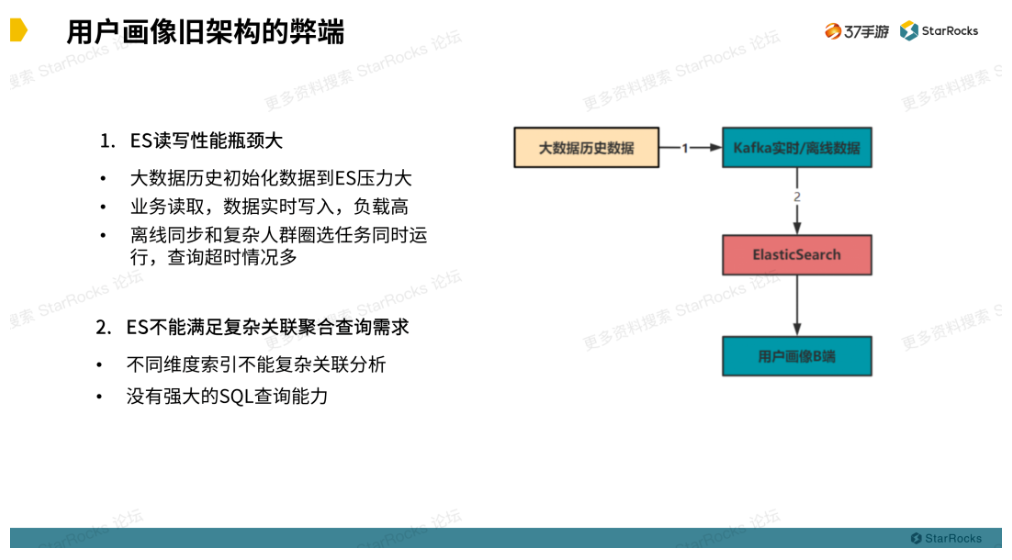
这里有一张简短的数据流程图,可以看出旧架构数据流向和使用的中间组件,这里使用 ElasticSearch 存储用户画像数据来提供服务应用查询,中间的 Kafka 作为消息队列经过 Logstash 消费到 ElasticSearch。
为什么历史数据会推到 Kafka 上呢?
主要在于 ElasticSearch 读写性能瓶颈。开始我们尝试了将离线的 Hive 表,通过外部表的方式直接同步到 ElasticSearch 。在这种方式下,十亿级别历史数据初始化到 ElasticSearch,会导致其服务负载高、同步时间特别长。因此才把历史数据推到 Kafka 利用其削峰填谷的能力,减轻 ElasticSearch 的部分压力。但是实践证明减缓不了多少压力,另外业务读取和实时离线写入也会出现因负载高导致业务查询超时的情况。
此外,ElasticSearch 不能满足复杂关联聚合查询的需求,不同维度索引无法关联并且没有强大的 SQL 查询能力。ElasticSearch 的限制导致了在复杂查询场景下不能满足需求。
简单总结一下画像选型的变更时间线:
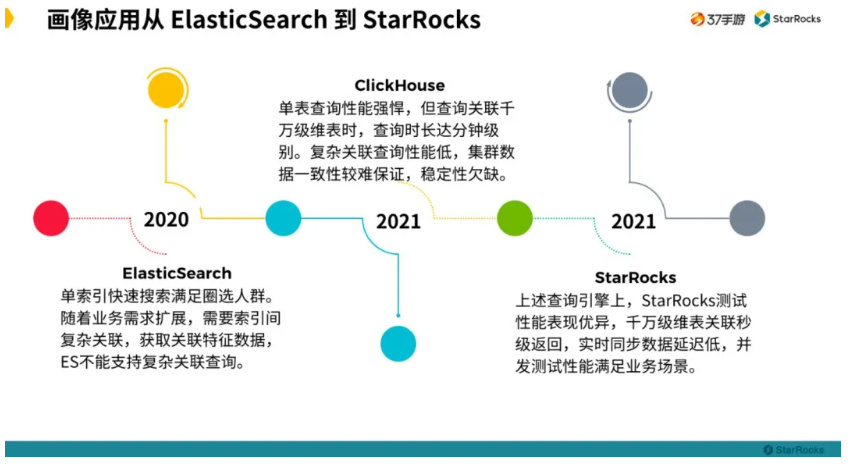
ElasticSearch 在用户画像应用使用时间周期是比较长的。因为 ElasticSearch 单索引能快速满足简单的圈选人群需求。但是随着业务发展,需要索引间复杂关联分析,此时 ElasticSearch 支持不了。
ClickHouse 会出现大表关联查询性能低、数据一致性等问题。
最终 StarRocks 测试表现性能相当优异,千万级维表关联查询秒级返回,数据实时同步延迟低等。
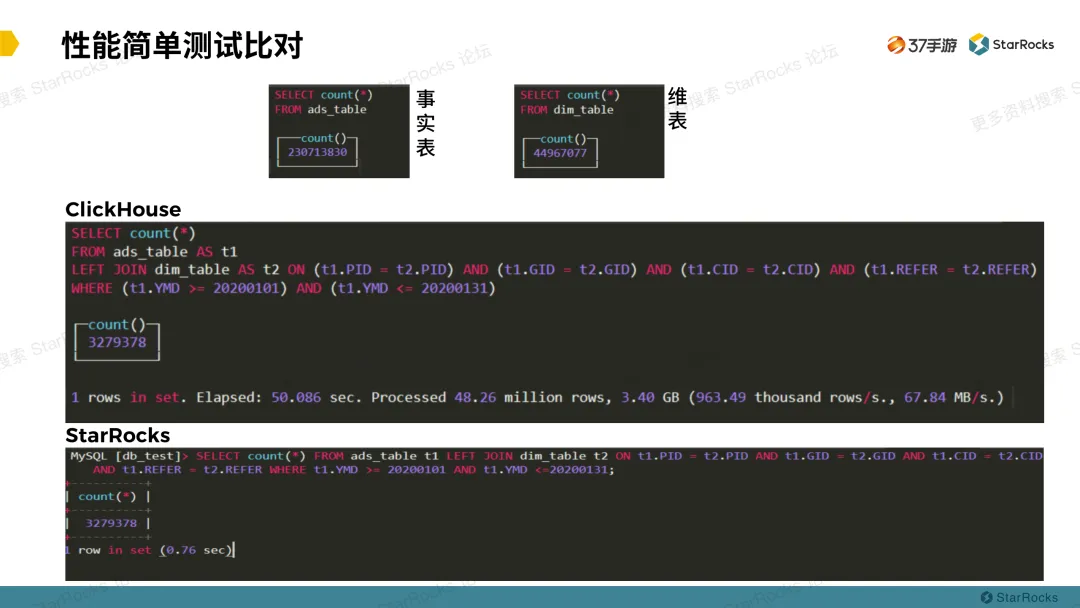
从上图可以看到,测试事实表数据量两亿多,维表数据量四千多万。ClickHouse 的关联查询时间大概 50s左右, StarRocks 关联查询在 1s 内,性能差异明显。ClickHouse 的关联查询是直接把维表数据全部读取出来进行匹配关联查询,而 StarRocks 对这块做了关联优化下推,这也体现了 StarRocks 大表关联查询性能优异。
#03
替换 StarRocks 后的用户画像架构
—
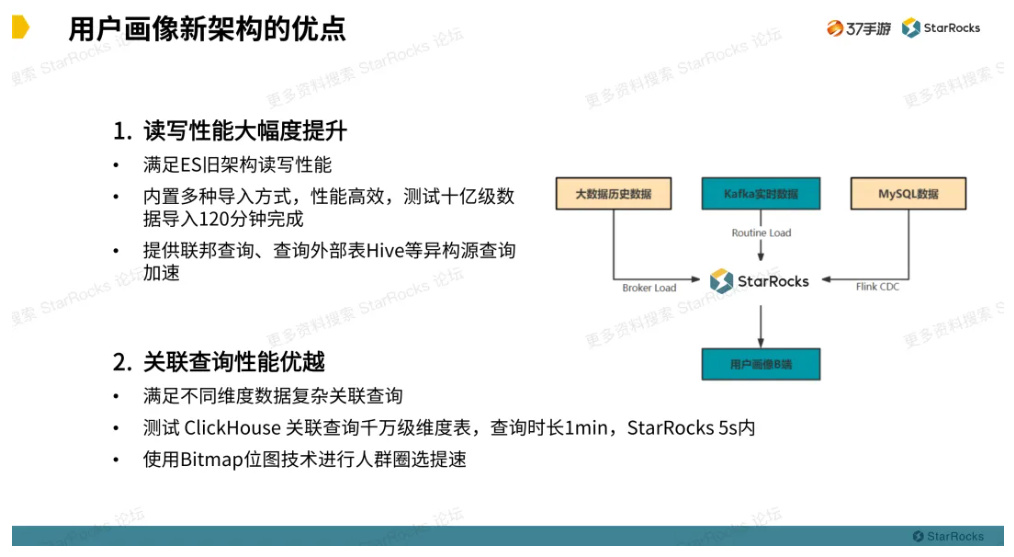
替换为 StarRocks 后的数据架构新增了使用 FlinkCDC 实时同步 MySQL 数据到 OLAP 引擎上,这样就增加了关联数据的多样性。
读写性能大幅度提升:1)满足 ElasticSearch 旧架构读写性能;2)内置多种导入方式,性能高效,测试使用 Broker load 导入 Hive 十亿级数据 ,120 分钟就能完成处理,资源占用低,也解决了旧架构读写的问题;3)增加了联邦查询功能,提供外部表连接 Hive 等异构数据源查询加速。
关联查询性能优异:1)满足了画像不同维度数据的复杂关联;2)测试 ClickHouse 关联查询千万级维度表,查询时长为 1min,而 StarRocks 是在 5s 内;3)画像时可以利用 Bitmap 位图技术对复杂人群圈选进行提速。
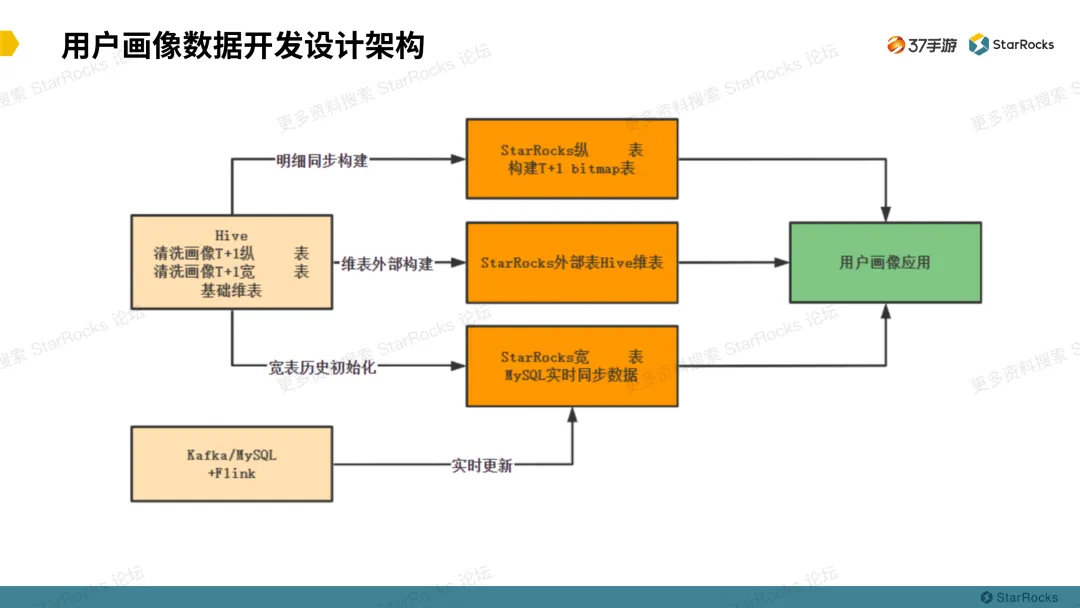
上图是一个简单数据开发流向图,从 Hive 离线清洗出用户画像纵表、宽表和基础维表。纵表就是一个用户、一个标签、一个值。例如,一条记录是,用户小明,标签age,标签值18。另外一条记录是,用户小明,标签sex,标签值man。
这在纵表中存有两条记录,在宽表里面构建,就只有一条记录,两列分别存取年龄和性别的标签值。然后把开发好的纵表同步到 StarRocks 上用于构建 Bitmap 表,宽表同步到 StarRocks 的主键表,维表使用 StarRocks 外部表连接。实时数据同步到对应的基础数据表上用于关联查询。
1.用户画像Bitmap表的开发设计

基于数据流向,这里首先阐述下 Bitmap 数据表的开发设计。上图展示了 Hive 明细纵表推送到 StarRocks 后的更新模型表。在 StarRocks 聚合模型的 Bitmap 表中,就有构建 Bitmap 表的一个 SQL 语句,到此 Bitmap 表构建设计已完成。
我们在明细数据聚合表设计上遇到过一些性能问题。一开始,我们根据 Hive 直接设计 StarRocks 更新表 Key 和桶顺序分别是 uid,tag_type 这样的顺序的。但是我们构建 Bitmap 表的时候基本是使用 where tag_type in 的方式来查询构建的,导致每次读取 IO 基本打满,影响实时数据写入。后来,我们重新设计表的 Key 值顺序,把 tag_type 提到 uid 前,修改之后读取 IO 只占用 20% 以下了。
2.用户画像查询性能对比

再看下简单查询性能对比,当前明细纵表数据接近六百亿数据,100多个标签值,构建完 Bitmap 表后数据量在四十万左右。上图简单查询对比了 Apache Impala(以下简称 Impala)和 StarRocks 的 Bitmap 表的圈选速度,使用 StarRocks 后提升了接近 26 倍。

上图左是一个 Bitmap 表使用的 SQL 示例,右边是画像业务实现的 SQL 逻辑。左边示例中,应该填写其他维度画像的 Bitmap 表,或者填写其它基础数据表进行复杂关联查询圈选,这样可能会更好地展现 StarRocks 优势。
3.用户画像提供的基础查询服务
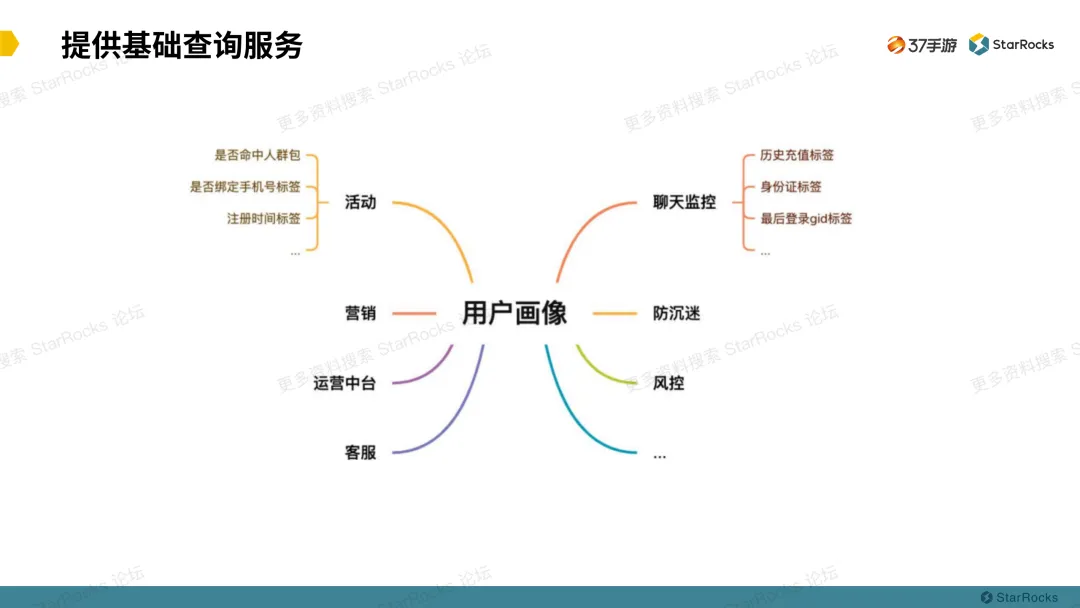
在基于 Bitmap 表实现的人群圈选的功能模块中,现在支持按规则或非规则创建人群包,自定义上传人群包,自由组合创建人群包。 未来会支持外联更多数据。
我们还直接使用了 StarRocks 提供的监控模版直接使用配置相关监控告警。下图是 StarRocks 实时消费 Kafka 监控面板。
#04
展望
—
接下来我们会有更多业务接入 StarRocks,替换原有 OLAP 查询引擎;运用更多的业务场景,积累经验,提高集群稳定性。未来希望 StarRocks 优化提升主键模型内存占用,支持更灵活的部分列更新方式,持续优化提升 Bitmap 查询性能,同时优化多租户资源隔离。
今后我们也会继续积极参与 StarRocks 的社区讨论,反馈业务场景。之前我经常参加社区群进行讨论,在社区群里获得过很多技术上的支持和答疑。在此,感谢流木大佬、颖婷等 StarRocks 社区伙伴在技术上的耐心指导!
本文整理自 37 手游 Meetup 直播
收看视频回顾请至:
https://www.bilibili.com/video/BV1ES4y1v7Eu?spm_id_from=333.999.0.0
如需完整版讲师 PPT,请添加小助手微信 StarRocks-1,报暗号“37”