
为了更快的定位您的问题,请提供以下信息,谢谢
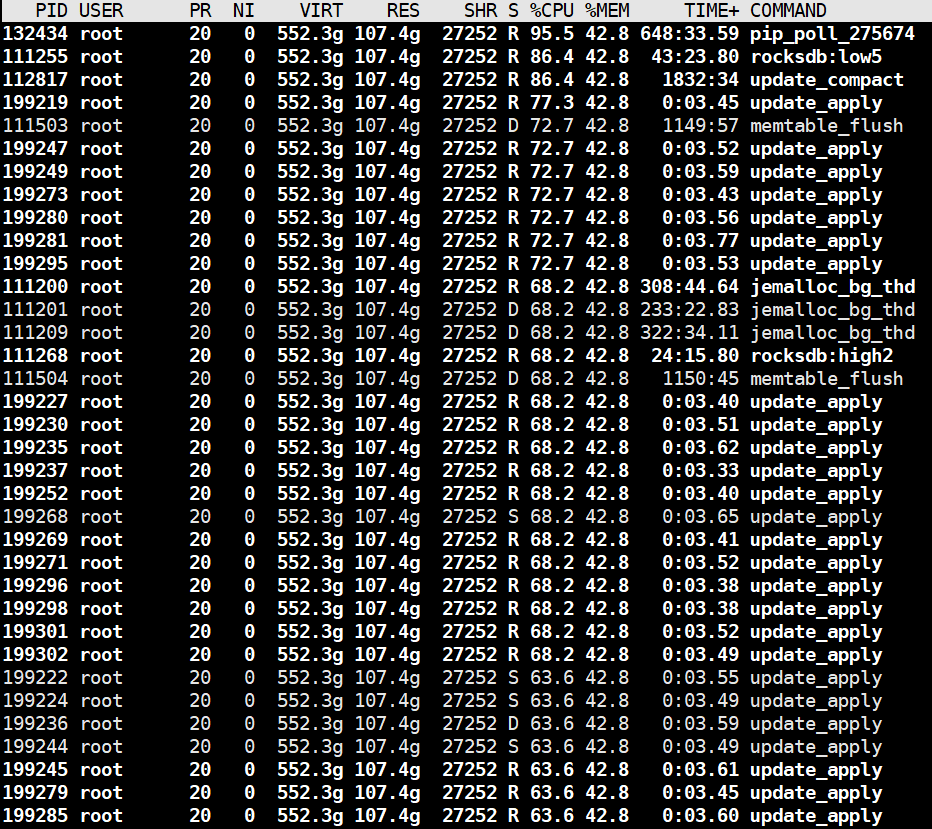
【详述】大部分be节点的cpu激增
【背景】集群中,streamload、routineload job都有,表模型基本是主键模型
【业务影响】
【是否存算分离】否
【StarRocks版本】3.3.5
【集群规模】例如:3fe + 6be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:80C/256G/万兆
【联系方式】
【附件】
top

1赞
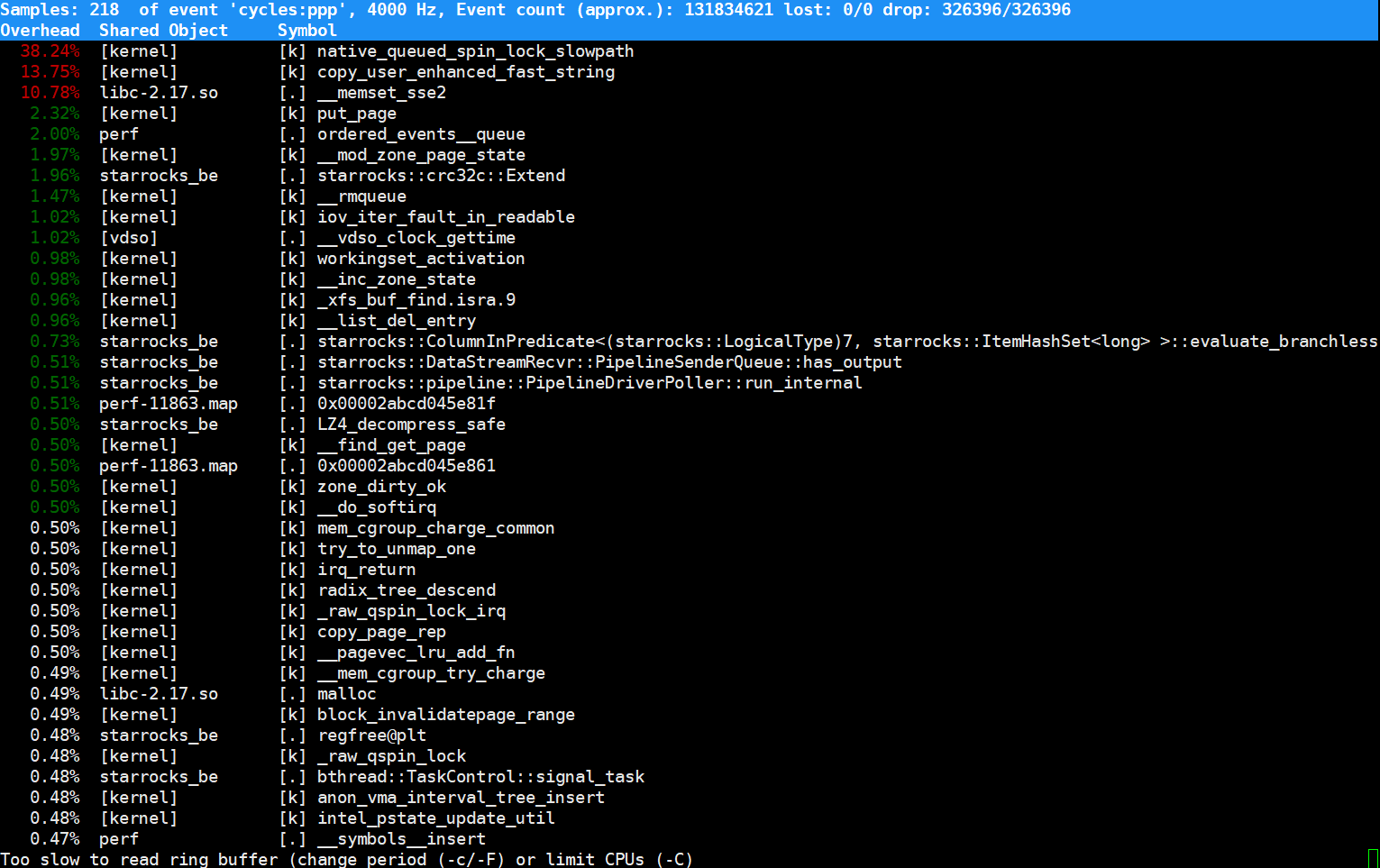
sudo perf top -g > a.txt 获取个30s的
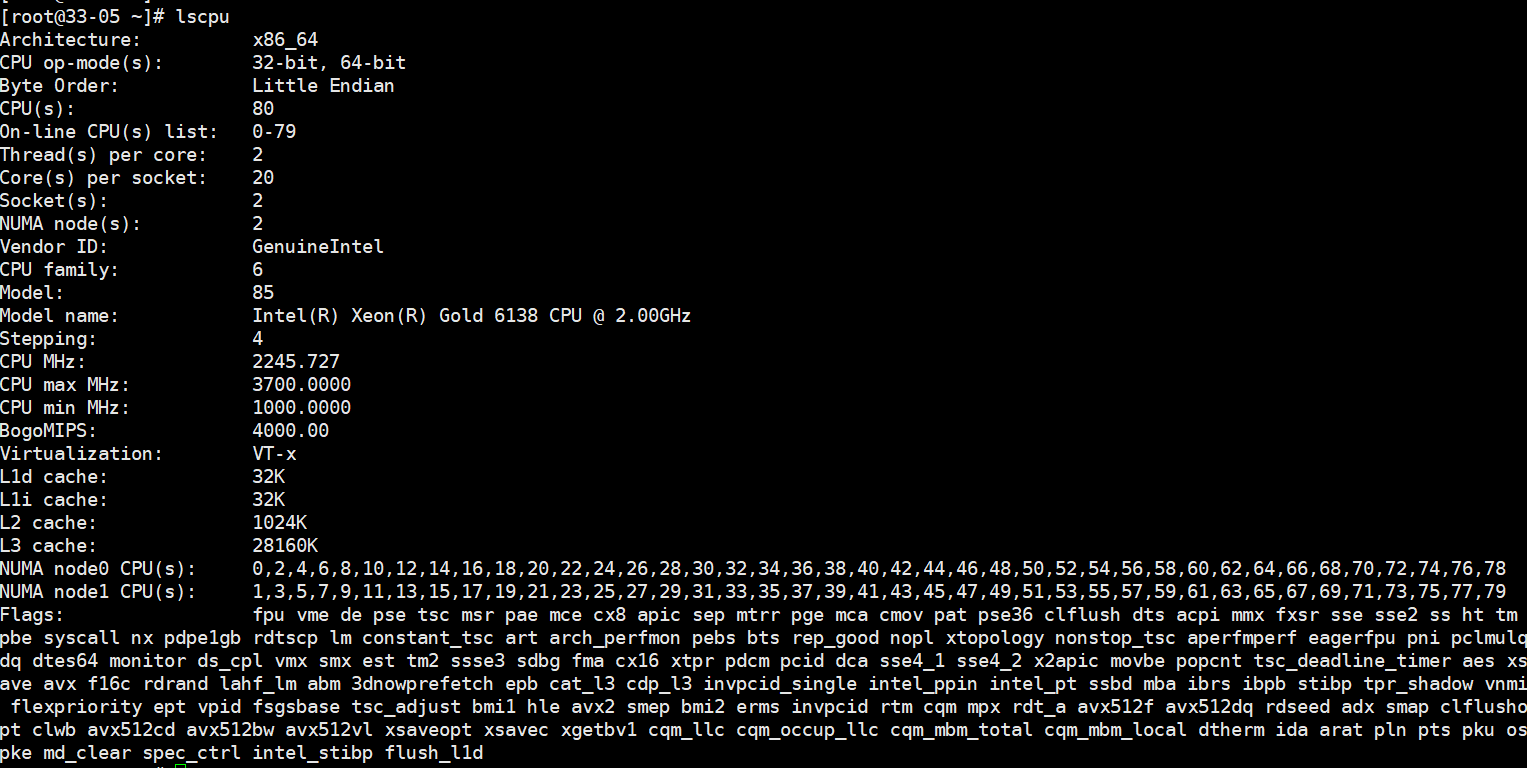
然后看下机器有几个Numa
cat /proc/meminfo | grep -i numa
64核机器?
命令执行, 显示为空 
有超大的宽表?
有一个 近60个字段的宽表 (每小时写入),数据量在1亿左右, 其余应该都是字段十多个的那种
show backends; 看下有多少tablet
我也遇到了这个问题,同样一份数据routine load写到3.2.2版本的集群里没有问题,写到3.2.9版本的灾备集群就update_apply线程把cpu占完了
是否是有非常大的主键表?比如未分区的大主键表,或者分区的主键表但历史分区一直在更新?
按照使用经验,主键表如果一直在大数据量更新,cpu和io都会飙升
有几张 几亿的数据分区表,频率会在 小时级别的spark 全量load,难不成是这原因?