
【详述】starrocks 高并发查询,2个资源组,sql执行变的很慢,如何解决。
【背景】调整过pipeline_dop参数
【业务影响】影响查询
【是否存算分离】否
【StarRocks版本】3.1.15版本
【集群规模】1fe + 3be
【机器信息】be: 256g 48cores fe:256g 48cores
【联系方式】
【附件】
- 慢查询:
- Profile信息
- 并行度:show variables like ‘%parallel_fragment_exec_instance_num%’;
±------------------------------------±------+
| Variable_name | Value |
±------------------------------------±------+
| parallel_fragment_exec_instance_num | 1 | - pipeline是否开启:show variables like ‘%pipeline%’;
±--------------------------------±------+
| Variable_name | Value |
±--------------------------------±------+
| enable_pipeline_engine | true |
| enable_pipeline_query_statistic | true |
| max_pipeline_dop | 64 |
| pipeline_dop | 12 |
| pipeline_profile_level | 2 |
| pipeline_sink_dop | 0 |
±--------------------------------±------+
2个资源组的信息:
create
resource group rg_tpch
to
(user=‘tpch’, query_type in (‘select’,‘insert’))
with (
‘cpu_core_limit’ = ‘24’,
‘mem_limit’ = ‘80%’,
‘type’ = ‘normal’
);
create
resource group rg_short_query
to
(user=‘tutor_cyber’, query_type in (‘select’,‘insert’))
with (
‘cpu_core_limit’ = ‘24’,
‘mem_limit’ = ‘80%’,
‘type’ = ‘short_query’
);
一、单独跑任意一个资源组的sql,进行压测(每隔2s,提交1个sql,总计60个SQL):结果是:
1.rg_tpch
sum总耗时 平均查询耗时 最大查询耗时 最小查询耗时
88750 1479 1679 1389
2.rg_short_query
sum总耗时 平均查询耗时 最大查询耗时 最小查询耗时
82621 1377 1658 1322
二、同时对2个资源组压测,进行压测(每隔2s,提交1个sql,总计60个SQL):结果是:
1.rg_tpch
sum总耗时 平均查询耗时 最大查询耗时 最小查询耗时
3943678 65727 108914 5404
2.rg_short_query
sum总耗时 平均查询耗时 最大查询耗时 最小查询耗时
721079 12017 22542 1420
分析慢查:
2个资源组的慢查,profile如下:
rg_tpch
rg_tpch.txt (2.2 MB)
rg_short_query
rg_short_query.txt (839.9 KB)
be内存监控:
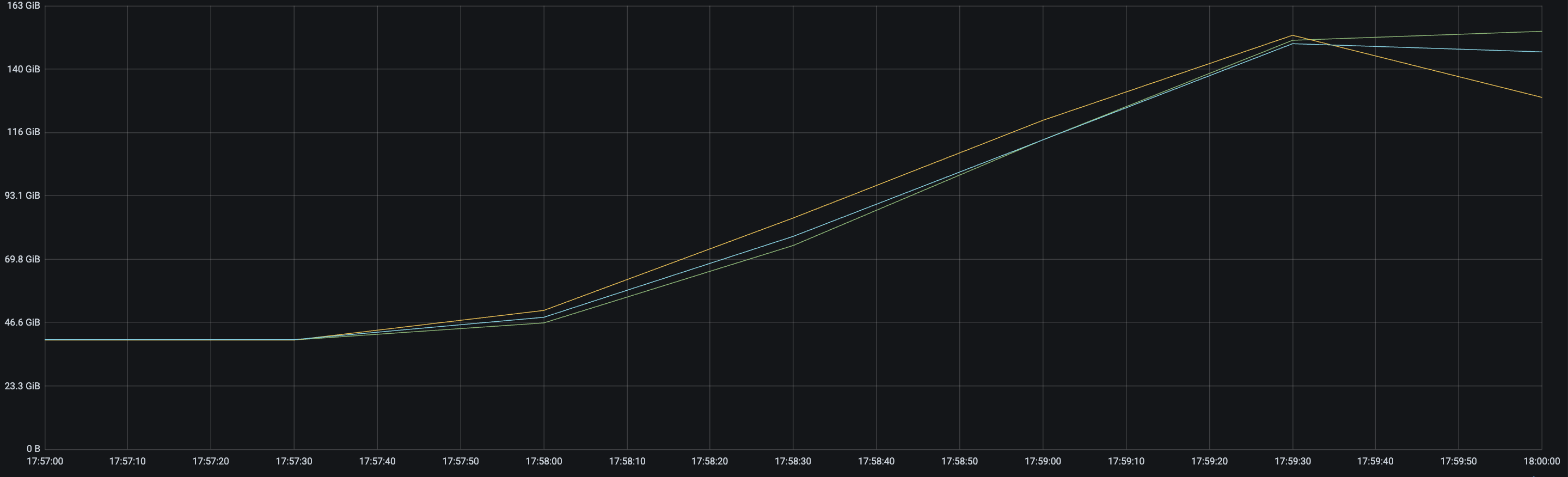
be cpu监控:
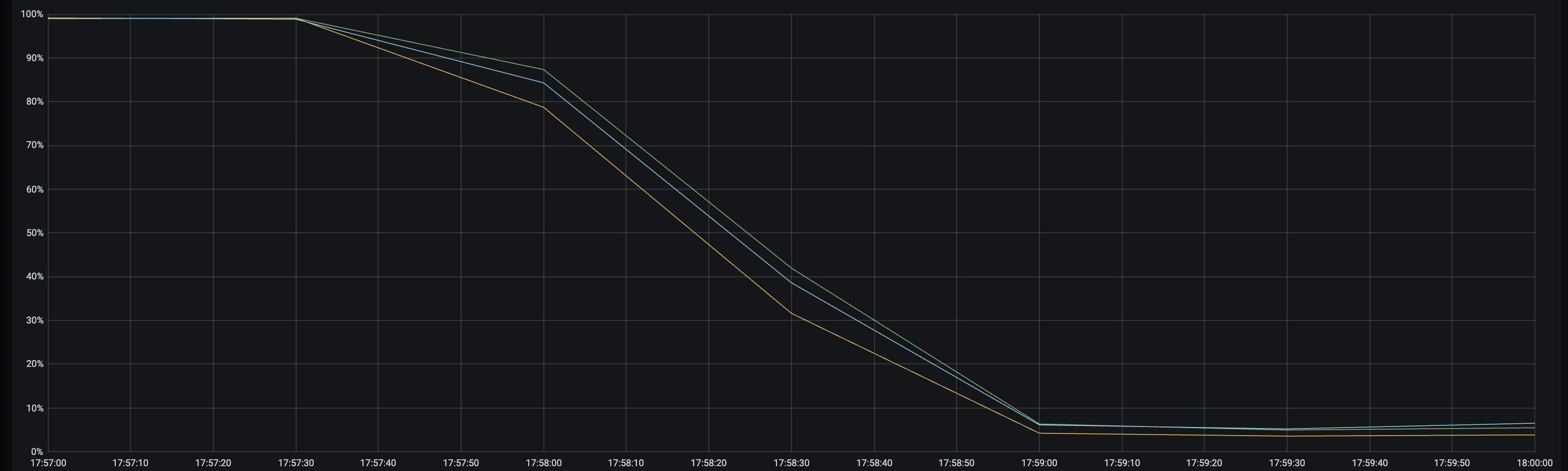
需求:如何把这2个资源组的平均查询时间都缩短?优化查询。
