
为了更快的定位您的问题,请提供以下信息,谢谢
【详述】问题详细描述
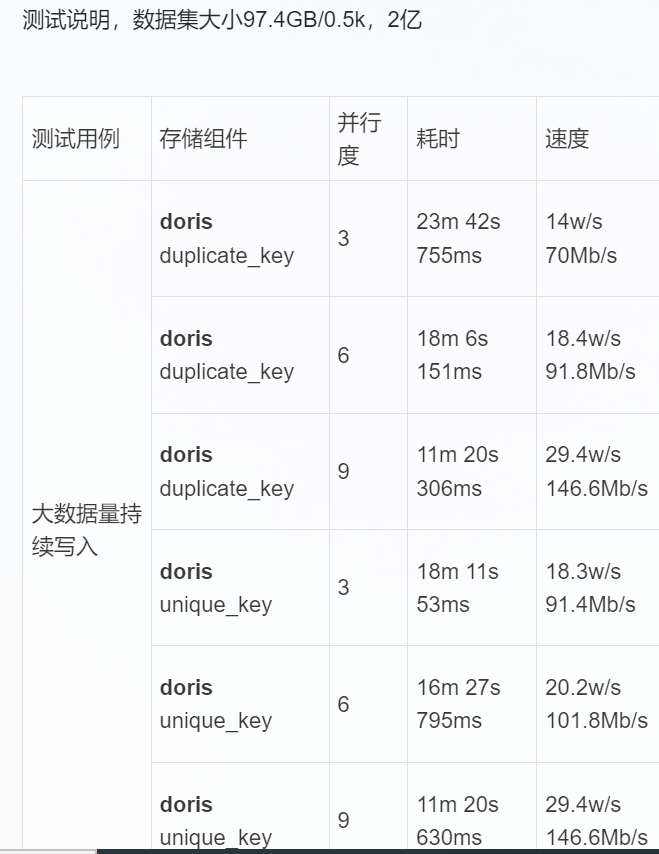
用flink-connector写入sr,三台集群,三个fe,三个be。
source是自定义内存造数据,固定条数和大小。
为何加大flink任务的并发不能提升整体的写入速率???
【背景】做过哪些操作?
【业务影响】
【是否存算分离】 存算一体
【StarRocks版本】最新
【connector版本】flink-connector 1.2 或者spark-connector 1.2
【集群规模】例如:3fe(1 follower+2observer)+5be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:48C/64G/万兆
【联系方式】例如:社区群24-张义传
【附件】
flink 是standlone集群,根据具体并发数调节tm中slot个数
代码如下:
`
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = env.addSource(new MySource3(Integer.parseInt(args[0])));
StarRocksSinkOptions options = StarRocksSinkOptions.builder()
.withProperty("jdbc-url", "jdbc:mysql://10.0.81.195:9030,10.0.81.50:9030,10.0.81.63:9030")
.withProperty("load-url", "10.0.81.195:8030;10.0.81.50:8030;10.0.81.63:8030")
.withProperty("database-name", "ssb")
.withProperty("table-name", args[1])
.withProperty("username", "root")
.withProperty("password", "")
.withProperty("sink.properties.format", "csv")
.withProperty("sink.properties.column_separator", "|")
.withProperty("sink.buffer-flush.interval-ms", "30000")
.build();
// Create the sink with the options.
SinkFunction<String> starRockSink = StarRocksSink.sink(options);
source.addSink(starRockSink);
env.execute("StarRocks flink source");
}`