

作者马腾,于彦芳
编者荐语:
StarRocks 在 Shopee 的应用表现出色,凭借高速外部数据湖查询、优化的多表连接性能及优于 Presto 的执行效率和资源节省,广泛应用于数据服务、Data Go、Data Studio 等多个数据平台。
背景介绍
StarRocks 是一款 SQL 查询引擎,能够在数据湖仓上提供数据仓库级别的性能。StarRocks 是一款出色的分析引擎,具有强大的功能,例如向量化执行引擎、基于成本的优化器、数据缓存和具有透明查询重写能力的物化视图。除了其自管理的专有表格式外,它还支持直接查询大多数流行的数据湖表格式,如 Hive、Iceberg、Delta Lake 和 Hudi。借助其内置的目录功能,只需一个创建外部目录的 SQL 语句,即可立即部署 StarRocks 并查询数据湖表。
在 Shopee,我们在多个平台上采用了 StarRocks ,利用其能力来满足各种分析需求。让我们深入探讨一下 StarRocks 如何在三个不同场景中在我们的数据环境中发挥了关键作用。
1. DataService - 构建低成本和高速的外部数据湖
- 使用 StarRocks 的 MV on External Catalog (Hive) 来提高查询性能
2. DataGo - 加速表连接和洞察提取
- 使用 StarRocks 的多表 Join 能力
3. DataStudio - 选择 StarRocks 替代 Presto,以获得更快的查询速度和资源节省
- 使用 StarRocks on Hive
Data Service x StarRocks
Data Service 产品简介
Data Service 是 Shopee 的一个数据平台产品,旨在以 API 的形式提供用户需要的数据,并管理整个 API 生命周期。通过数据服务,用户可以轻松选择所需的 Hive 表和列,配置过滤条件,创建 API。在后台,Data Service 根据用户的配置生成查询语句。当用户触发 API 时,数据服务运行查询语句并将请求的数据返回给用户。然而,当查询过于复杂时,可能需要数分钟到数小时才能完成查询执行;有时甚至需要更长时间。
Data Service 使用 StarRocks 来实现查询加速 – OLAP SpeedUp
为什么选择 StarRocks
a. StarRocks 支持对 Hive 进行查询,并且这一功能已经达到生产级别。
b. StarRocks 支持基于外部引擎(Hive)构建物化视图(MV)。
c. 使用 StarRocks 在 Hive 上的 MV,用户无需维护从 Hive 到 OLAP 引擎的实时或近实时写入管道。这不仅节省了用户在人工资源开发成本上的支出,也减少了实时管道所需的组件成本。此外,这种方法对用户的使用没有任何影响;他们无需做任何工作就能从 API 查询性能的提升中受益。这种方法也大大提升了用户业务推广的效率。
- 其他引擎如 ClickHouse 也可以利用物化视图来预计算查询数据。然而ClickHouse 对数据湖的支持有限,并且在社区路线图中没有开发计划。这意味着使用 ClickHouse 实现类似 OLAP 的功能需要手动开发 API,或者将 Hive 数据传输到 ClickHouse 并使用 ClickHouse 的 MV 进行预计算。或者,可以使用 Flink 实现实时预计算逻辑,然后将结果写入 ClickHouse。不论选择哪种方法,都需要大量的人力支持,并且还会增加 ETL 管道组件的成本
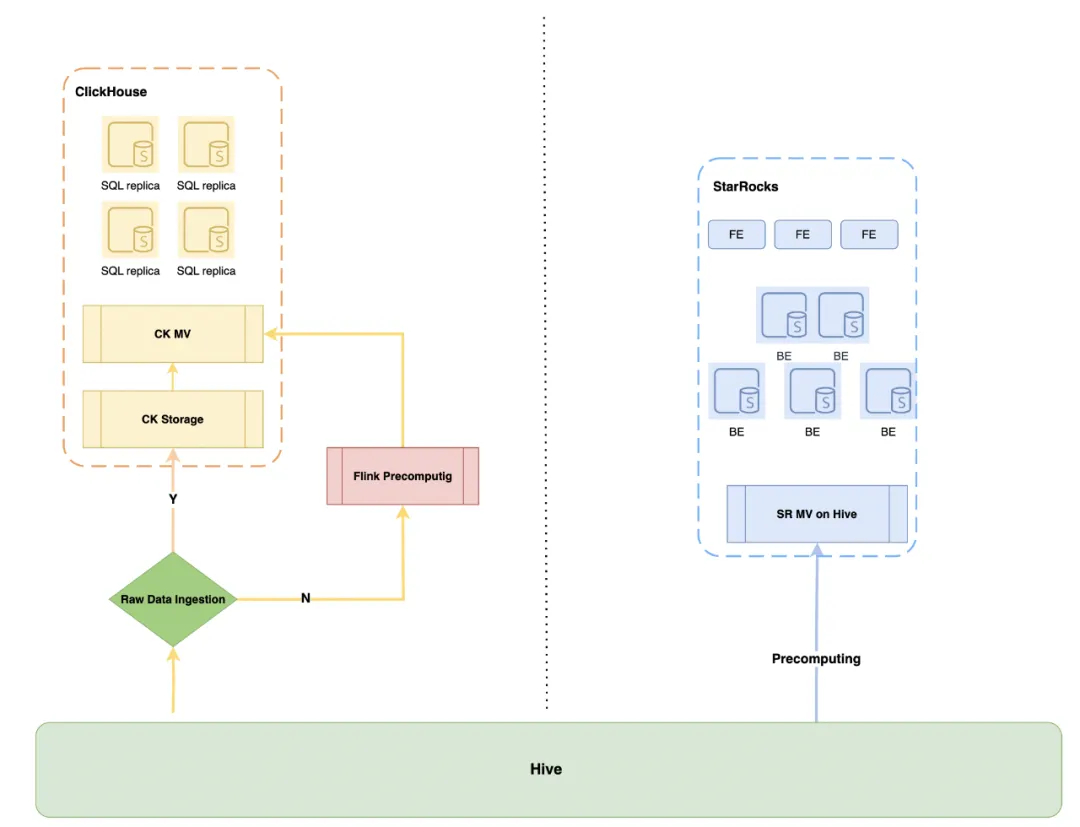
OLAP Speed Up 方案 (StarRocks MV On Hive) 介绍
Data Service 利用 StarRocks 来加速查询,这一功能称为 olap-speedup。以下查询为例。Data Service 首先要求用户把 SQL 逻辑写成 CTE 的模式然后后端会将用户的 SQL with 部分 提取出来改造成 StarRocks 异步物化视图的 create stmt。“With” 语句中的 SQL 称为公共表表达式(CTE)。
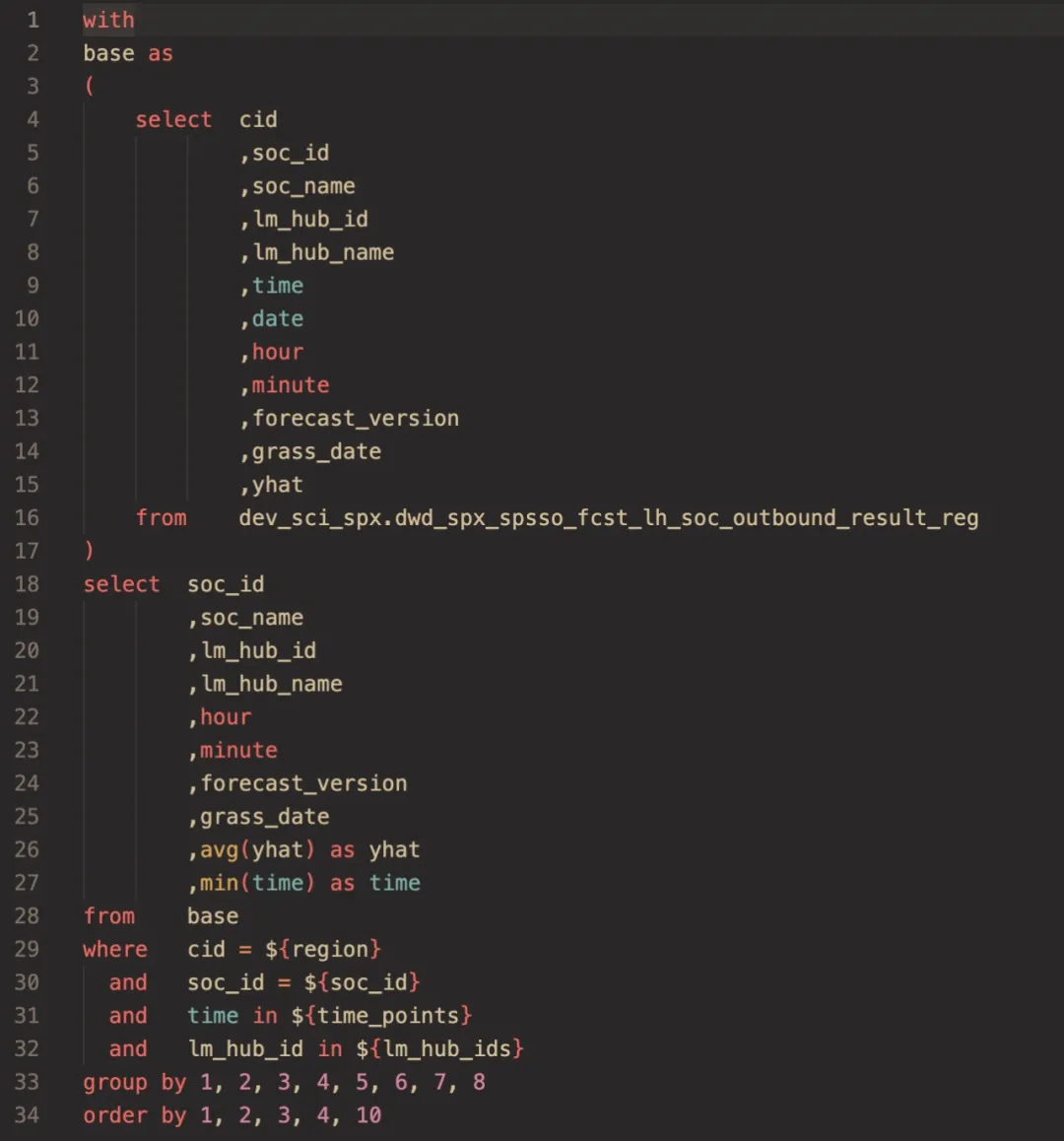
Data Service 在 StarRocks 物化视图上构建用户查询的 CTE 部分。通过引用这些物化视图,数据库引擎可以快速检索预计算结果,从而显著提升查询速度。
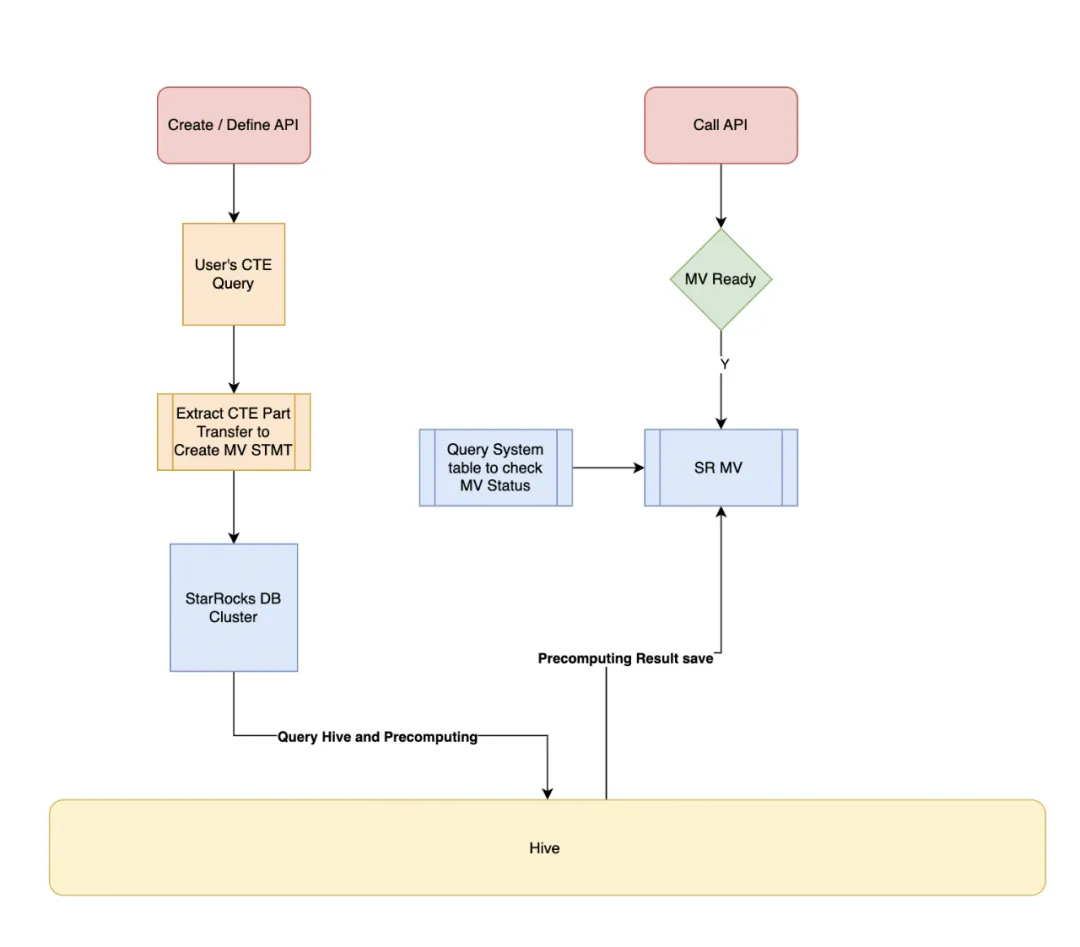
OLAP speed-up 性能结果
这种优化使查询执行速度提高了 10 到 2000 倍,减少了资源消耗并提高了整体效率。
- Data service 计划推出 10 个高流量 API,这些 API 将占据平台总流量的 70%。目前,已有 5 个 API 上线。
- 基于这 5 个 API 的查询响应时间,olap speed up 解决方案取得了显著的成果
下表显示了 Data Service API 的执行时间统计。目前,这 5 个 API 分别通过 Presto 查询 Hive 和查询 StarRocks 物化视图各运行一次。这使得可以直观地比较两种方法的 p90 和 p99 执行时间。

- 在上图中,第二列,query_count,表示在所选时间窗口(24小时)内调用当前API的次数。第三列,result_consistency_ratio,指示了 StarRocks 加速结果与直接使用 Presto 查询 Hive 结果之间的比较。(第五个 API 的低准确性是因为其存储表每小时更新一次,而标记设置为每日更新。StarRocks 材料化视图的刷新取决于标记配置。)第四和第五列分别显示了在使用 StarRocks 材料化视图加速后的查询延迟 p99 和 p90。最后两列代表了使用 StarRocks 材料化视图相对于直接在 Hive上使用 Presto 进行查询的性能改进,分别针对 p90 和 p99 的查询
- 为什么一些 API 在 StarRocks 下可以将查询性能提升超过 1000 倍?StarRocks 在给定时间段内执行速度更快,而 Presto 较慢且倾向于排队,导致大部分 API 调用的延迟时间花费在排队上。
Data Service 资源使用总结
在 Data Service 的 OLAP 加速场景中,StarRocks 支持基于外部存储的材料化视图加速,也就是说在物化视图刷新期间,它将根据物化视图的计算逻辑,从 Hive 中提取预计算的数据到本地 StarRocks 存储。这提供了 ETL 和预计算的功能。不论是业务用户利用数据服务平台,还是数据服务平台的开发人员,都无需额外的人力来维护实时写入流水线。这显著节省了人力成本,以及实时流水线所需的 ETL 任务的组件成本。
Data Go x StarRocks
Data Go 产品简介
Data Go 是一个 codeless 的数据查询构建平台,支持业务用户从可访问的数据模型中检索感兴趣的指标数据(例如店铺绩效、订单 GMV 等)。数据模型由数据管理员创建,通过向数据模型中添加1个或多个表或者数据列。数据用户可以选择适当的数据模型,通过选择输出列并应用筛选器来构建查询。当用户在 UI 上触发查询时,Data Go 使用 Presto 引擎检索 Hive 数据 并将数据下载到 CSV 文件供用户使用。然而当从多个表中提取数据时,多表连接查询的性能优化可能具有挑战性,往往会导致增加的资源消耗和查询执行时间。
Data Go 使用 StarRocks 实现加速 多表 JOIN 的场景
为什么选择 StarRocks
StarRocks 是非常适合进行多表连接查询的数据库产品,因为它配备了基于成本的优化器。这个优化器非常创新,特别为向量化执行引擎定制,能够使 StarRocks 以快速且优化的方式执行查询执行计划,最终提供比竞争对手更好的多表连接查询性能。
Join Table 查询性能
Data Go 已经实施了使用 StarRocks 代替 Presto 进行表连接查询的策略。在多个国家的多个数据模型上进行了使用 StarRocks 和 Presto 的查询性能对比测试。
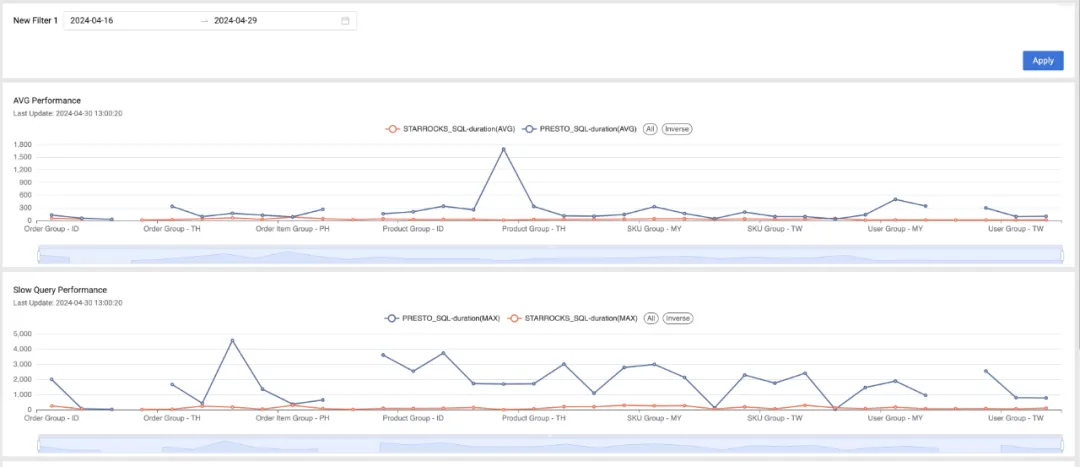
- 基于对 Data Go上实时业务场景的监控,可以观察到,StarRocks 在 Hive 上的性能比 Presto 在 Hive 上提高了 3 到 10 倍。
以 “Product Group - MY” 为例,以下是基于产品组的一个样本查询。在使用 Presto 执行这种复杂查询时,平均耗时 364 秒。而 StarRocks 仅用 20 秒就完成了相同的查询。因此,StarRocks 执行查询所需的时间显著减少。这种高效性使 StarRocks 能够在相同的时间框架内处理更多的查询,同时每个查询分配的资源更少。
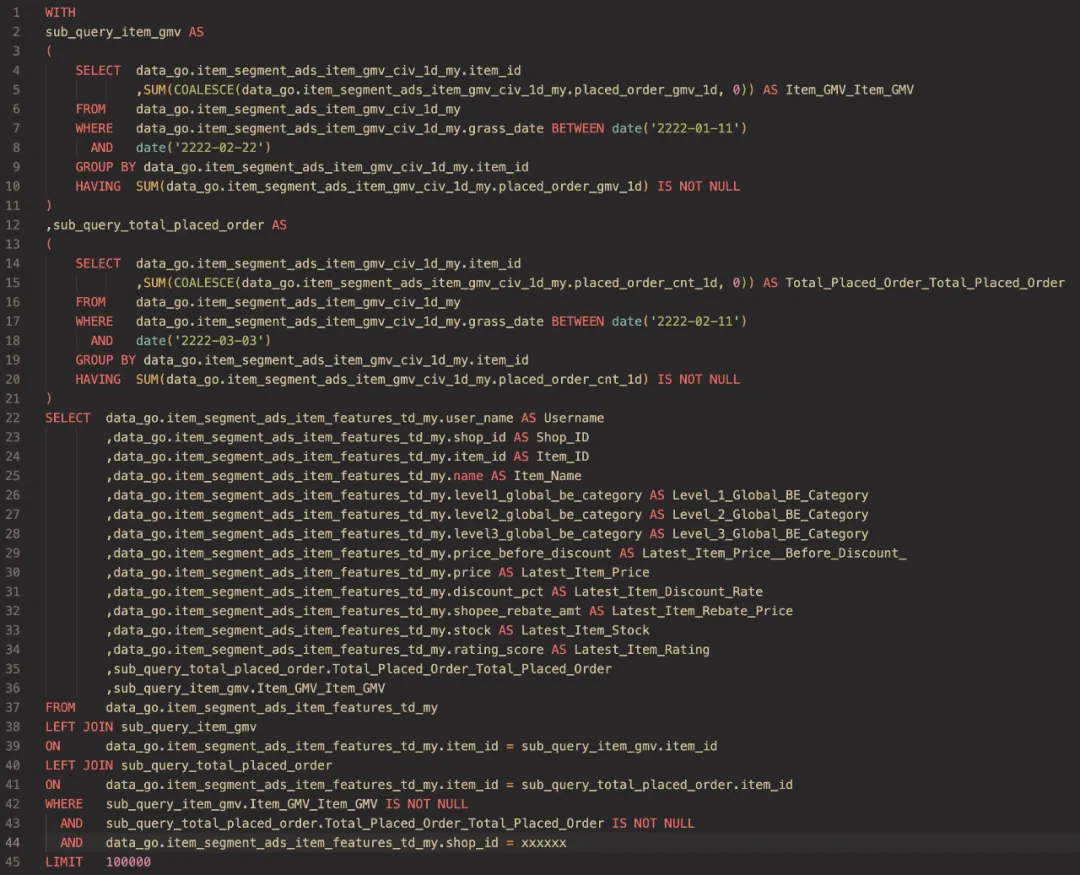
StarRocks 集群和 Presto 集群资源使用对比
StarRocks 集群 CPU 资源使用:
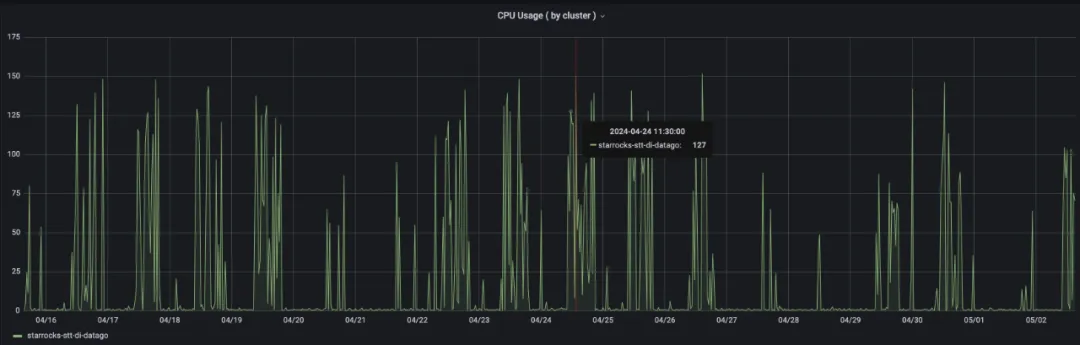
- 峰值 CPU 用量:150 core
- 均值 CPU 用量:40 core
Presto 集群 CPU 资源使用:
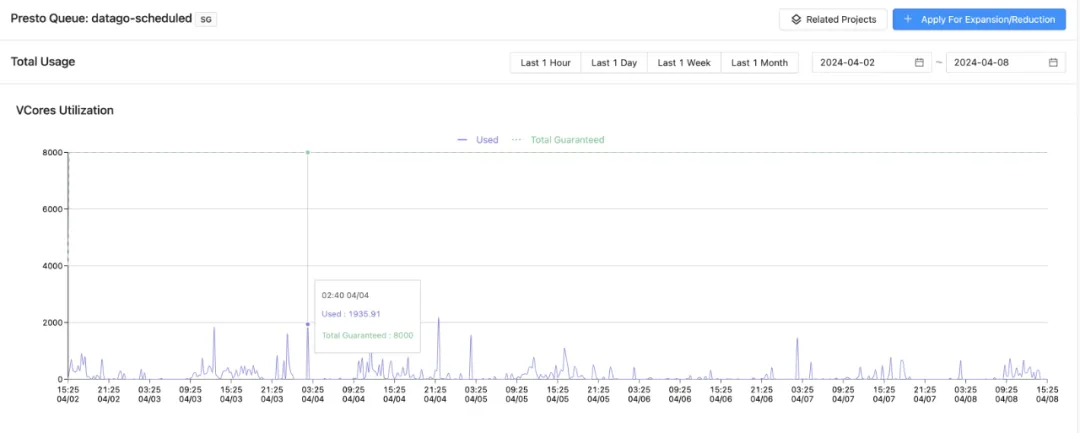
- 峰值 CPU 用量:2000 core
- 均值 CPU 用量:100 cores
Data Go 资源使用总结
基于对 Data Go 在线使用情况的分析,利用 StarRocks 在 Hive 上进行业务操作,与使用 Presto 查询 Hive 相比,平均性能提升了 3 到 10 倍,同时节省了 60% 的 CPU 资源。
- 显著的性能提升和计算资源节省主要归因于两个主要原因Data Go 业务的查询模式相对固定,主要涉及多个每日更新表的连接。我们的StarRocks 集群支持内存数据缓存和磁盘数据缓存(Data Go 的集群配置为 10GB 内存数据缓存和 400GB 磁盘数据缓存),这使得 Data Go 的业务查询具有很高的缓存命中率。StarRocks 自研的优化器比 Presto 的优化器更高效。在处理执行计划和计算过程是主要耗时因素的复杂查询(例如连接和嵌套子查询)时,StarRocks 表现出显著优势。相比之下,对于以 I/O 为主要耗时因素的查询,两者的差异不大。
Data Studio x StarRocks
Data Studio 产品简介
Data Studio 是一个支持临时和定时数据作业的数据开发平台。对于临时查询,用户创建一个空文件,输入查询语句,然后通过简单的“运行”命令来执行查询。然而,这个过程消耗大量资源,且复杂的分析查询通常需要较长的处理时间才能生成结果。
Data Studio StarRocks On Hive 介绍
为什么选择 StarRocks
- StarRocks 作为一个强大的查询执行引擎,支持外部目录如 Hive。用户可以利用 StarRocks 直接查询 Hive 表。借助其大规模并行处理(MPP)框架,单个查询请求被分成多个物理计算单元,然后可以在多台机器上并行执行。计算单元的并行执行充分利用了所有 CPU 核心和物理机器的资源,加速了查询性能。此架构使得 StarRocks 在查询性能上表现出色,特别是在处理涉及聚合、求和和分组的复杂分析查询时。
- 为了解决 Data Studio 在处理复杂查询时的当前挑战,团队正在考虑使用 StarRocks 来执行用户查询。他们正在进行实验,以评估性能和错误率,并将 StarRocks 与现有引擎 Presto 进行比较。
- StarRocks 对数据湖有成熟的支持。其他公司,如携程,利用 StarRocks 查询 Hive 以生成报表,而小红书则使用 StarRocks on Hive 作为临时查询引擎。腾讯进一步利用 StarRocks 进行 Iceberg 的查询和写入,实现冷热数据分离,并定期将冷数据沉入 Hive。
StarRocks & Presto 查询性能对比
集群计算资源概况
- StarRocks 400 core; 2700 GB Memory
- Presto 400 core; 2700 GB Memory
查询 Benchmark 基准
- SQL:选择 Data Studio 平台上 2024年3月25日到2024年3月29日用户执行的 Ad-Hoc Query SQL。
- 测试方法:分别使用1、5、20、40和50个线程并发压力测试 StarRocks 和 Presto。
- 查询延时结果统计:在相应的并发压力测试下,测量 StarRocks 和 Presto 的平均延迟、P90 延迟和 P99 延迟。
测试报告

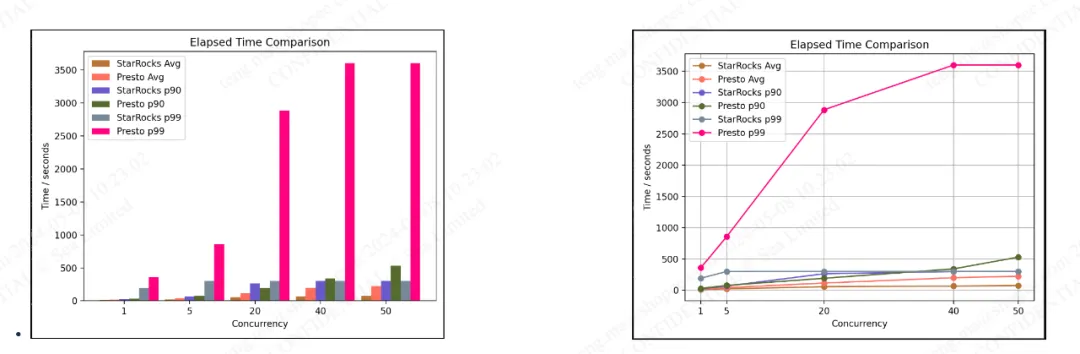
Data Studio 资源使用总结
根据 Data Studio 的测试结果,在使用相同计算资源(400 核心 + 2700GB 内存)的情况下,StarRocks 的性能比 Presto 提升了 2 到 3 倍。换句话说,StarRocks 可以用 Presto 仅 50% 到 70% 的资源提供与 Presto 相当的计算能力。
- 对于 Data Studio ,主要的改进来源于 StarRocks 优化器的优越性。Data Studio 中日常临时查询的特点是不固定模式,而是带有大量嵌套子查询和连接的复杂查询。这正是 StarRocks 擅长处理的查询模式。此外,由于临时查询模式的不可预测性,数据缓存
- 对我们的 Data Studio 场景影响较小。
总结
总而言之,StarRocks 在多种用户场景中表现出色,提供了从外部数据湖的高速查询、优化的多表连接查询性能,以及比 Presto 更优越的执行速度和资源节省。StarRocks 在我们组织中的广泛应用,包括数据服务、Data Go、Data Studio 等。它有效地解决了痛点并优化了数据分析的资源利用,使其成为数据分析需求的理想解决方案。
特别资讯:Shopee 大数据专家工程师马腾 将于 12 月 7 日在 StarRocks Summit Asia 2024 湖仓最佳实践分论坛分享 StarRocks 相关应用实践,欢迎感兴趣的用户扫码报名,到现场近距离了解详情~
大会官网 http://mkt.mirrorship.cn/activity/ActivityInfo/7Yev6K/k46OTWk
http://mkt.mirrorship.cn/activity/ActivityInfo/7Yev6K/k46OTWk