

作者:携程技术中心大数据总监 许鹏
StarRocks 小编导语:
携程自 2022 年起引入了 StarRocks,目前已经成为了集团内部的主要技术栈,应用到酒店、机票、商旅、度假、市场、火车票等多个关键业务线。目前,携程内部已经拥有超过 10 个 StarRocks 集群,内表总数据量超过 230T,每日查询量超过 1100W ;StarRocks-Hive外表每日查询量超过 10W。
Artnova 是携程内部统一的报表平台,承载了集团所有 BU 的报表业务,如酒店、机票、商旅、度假、市场、火车票等。业务人员可以通过在平台内配置自定义报表来获取所需的业务数据,辅助业务监控和决策。Artnova 报表查询具有如下特点:
-
SQL复杂、底表大 :为了满足复杂的业务需求,用户配置的报表 SQL 往往涉及多表关联、子查询、聚合等复杂操作,非常多的 SQL 达到数百行。并且,用户查询的底表通常很大,往往超过了百 GB,甚至超过 TB。
-
高并发、低耗时 :用户习惯上会把数据通知的邮件任务设置在整点,比如 8:00、9:00 是发送邮件的高峰期。这时系统内会有超过上千个复杂 SQL 同时查询,给整个集群带来比较大的压力。并且,单个仪表盘往往包含十多张甚至几十张报表,当用户打开仪表盘时,会有几十个复杂 SQL 同时查询。如何降低 SQL 延迟,保证响应足够快,让用户 0 等待也是一个比较大的挑战。
01 Complex Workflow ->One Data,All Analytics
类似大部分互联网公司,携程基于 Hive 进行了数仓建设。由于 Artnova 的查询特殊性,直接基于 Hive 的查询是无法满足业务需求的。Trino 虽然提供了一定的查询加速能力,但在复杂和高并发查询上的性能仍旧有瓶颈。于是我们开始寻求其它的解决方式。
Stage1: StarRocks as an OLAP, 10 time faster but complex
一个最直观的方案是把数据导入至 OLAP 数据库内进行加速。经过一系列调研、测试、验证,自 2022 年起,携程就开始采用 StarRocks 作为加速 Artnova 报表的新引擎。
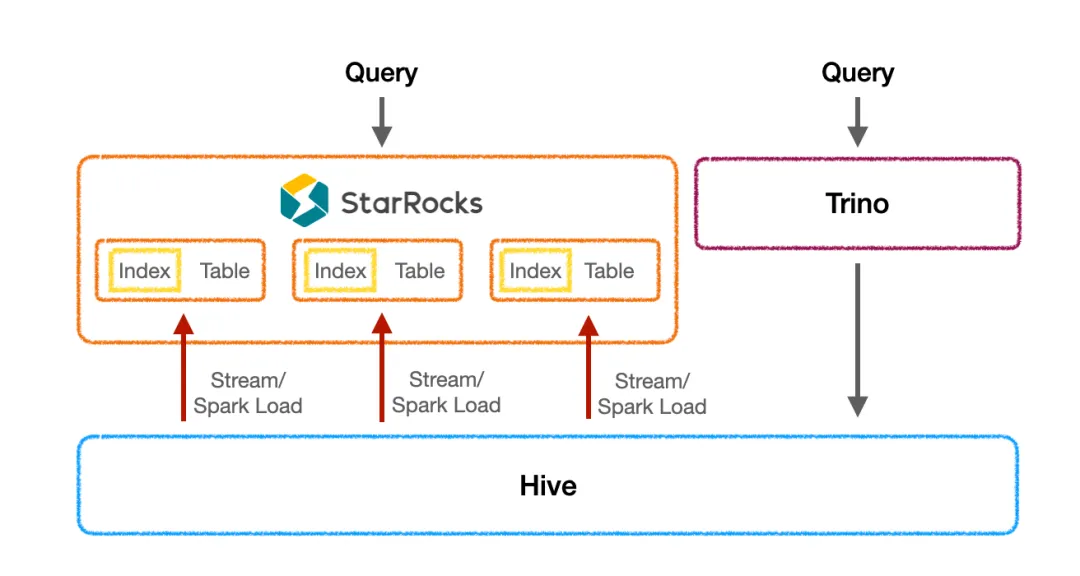
第一阶段我们把 StarRocks 当作 OLAP 数据库使用,小表通过 StreamLoad 方式、大表通过 SparkLoad 方式将数据从 Hive 导入到 StarRocks 内部,并针对 SQL 查询创建合适的索引。这样的方案取得了非常好的加速效果, 加速后平均耗时从 20 秒左右降低到了 1.5 秒,性能有 10 倍以上提升,真正为业务提供了秒级的报表体验 。
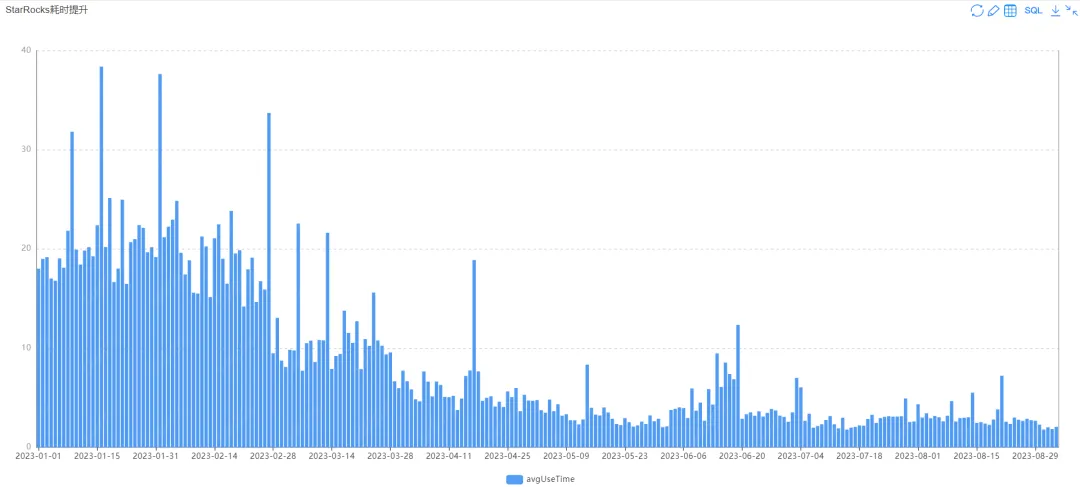
图表为日均查询耗时,可以看到前后对比明显
然而,这样的方式也有一定弊端:
- 导入性能虽然比较快,但相较查询 Hive 数据仍有一定的滞后,业务查询的灵活性和实效性受到了影响。
- 需要额外维护导入任务、针对不同查询进行表模型、索引设计,为整个数据 pipeline 引入了复杂性。
由于 Artnova 的业务量巨大,这个方案的复杂度使之无法规模化。我们无奈只选取了最重要、性能最需要提升的业务进行了迁移,剩余业务仍旧通过 Trino 来进行湖上查询加速。整体的查询延时问题并没有得到彻底的解决。
Stage2: StarRocks as a Lakehouse, fast and also easy and scalable
我们迫切的需要一种能够在降低数据链路复杂度的前提下提升性能的方式。 作为 StarRocks 的用户,我们一直积极地参与社区、关注社区的最新进展。社区自 2.0 版本之后就开始不断打磨湖上联邦查询的能力。3.0 版本发布之后,StarRocks 正式宣布升级为湖仓一体的新范式。不仅在查湖的性能、稳定性上进行了增强,外表物化视图的能力更是让人眼前一亮,而且社区还支持了 Trino 的语法,大大降低了迁移门槛。这让我们迫不及待的开始了测试。
测试效果非常惊艳。 StarRocks 在直接查湖的性能上非常优异,在开启 Data Cache 后性能是 Trino 的 7 倍,某些场景下创建物化视图后甚至有几十倍性能提升。
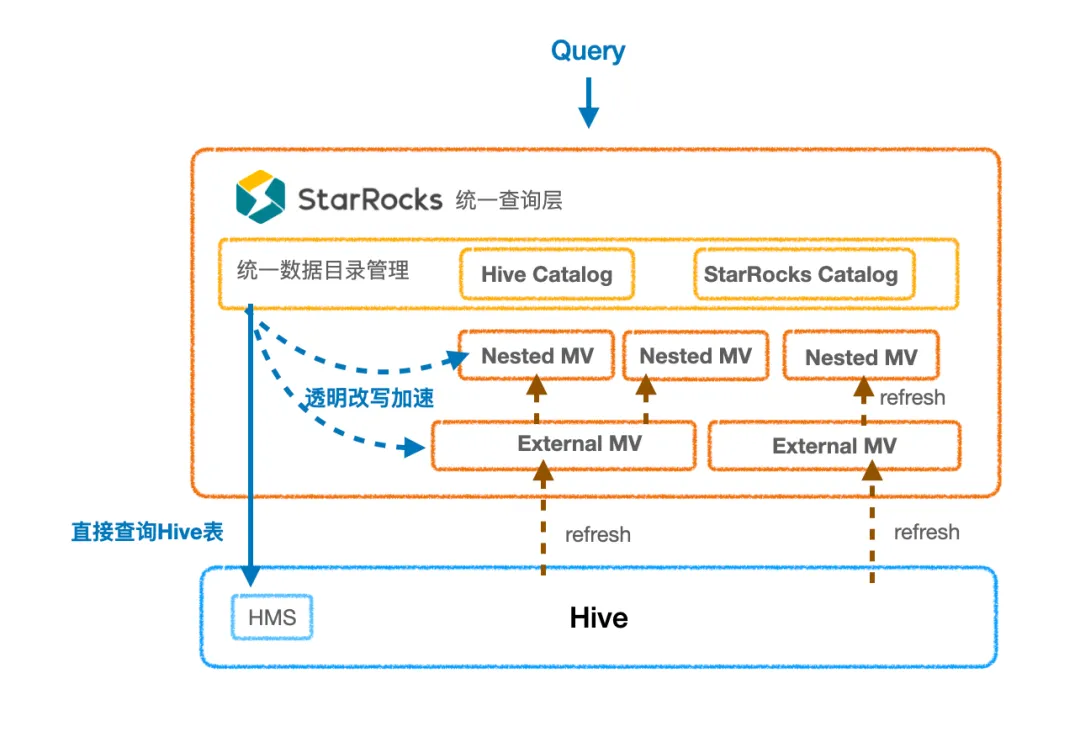
上图为 Artnova 当前的架构。新的架构充分利用了 StarRocks 数据湖查询以及异步物化视图的能力。新架构有如下优点:
-
无数据延时: StarRocks 的 Hive Catalog 可直接对 Hive 进行高效查询,提供比 Trino 更快的查询加速,解决了 StarRocks 作为 OLAP 时的数据延时问题。
-
无数据搬迁: 因为直接查询的性能已经足够优秀,大部分场景不用再将数据导入内表;对于部分需要进一步加速的极端复杂场景,可以通过物化视图来维护计算逻辑以及更新 pipeline。这大大降低了数据链路的维护成本,使整套方案更加通用可扩展。
-
按需透明加速: 物化视图的透明查询改写能力使平台可以按需对慢 SQL 进行治理。当出现慢查询时,平台只需分析 SQL 逻辑、创建合理的物化视图即可,不需要大张旗鼓地对数仓各层表逻辑进行更改。对于业务用户来说,也无需更改查询语句,即可通过透明改写享受到查询提速。从而业务用户可以不再关注性能优化,专注于业务逻辑;平台也提升了体验优化的效率。
下面来展开讲解整个测试流程及应用方案。
02 湖上直查性能强悍,7倍以上性能提升
湖上直接查询的性能是选型基础。网上有很多使用 TPC_DS、SSB 标准数据集测试StarRocks 和 Trino 的报告,效果非常理想。我们便跳过这一阶段,直接用真实业务报表进行测试。
先介绍下我们报表平台的数据结构:数据集和报表。数据集结构是指基础 SQL,可以是单表查询,雪花模型,星形模型等复杂 SQL。报表结构则是在数据集基础之上,进一步加工聚合的业务 SQL,同一个数据集上根据业务需求不同可能会存在多张报表。 本次测试选取了涉及 10 个常用数据集的共 4000 张报表,包含 15 种业务场景,涵盖多表 join,单表,大表,小表等 4000 多个常用查询。 在稳定性,正确性,查询性能等方面都得到了验证。
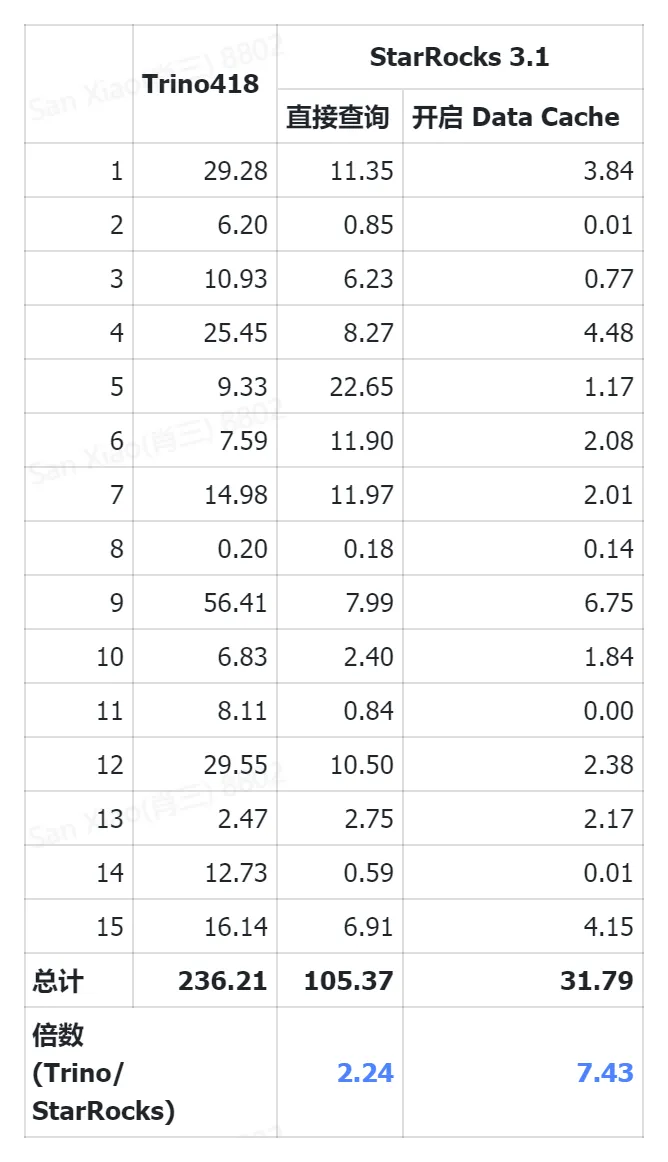
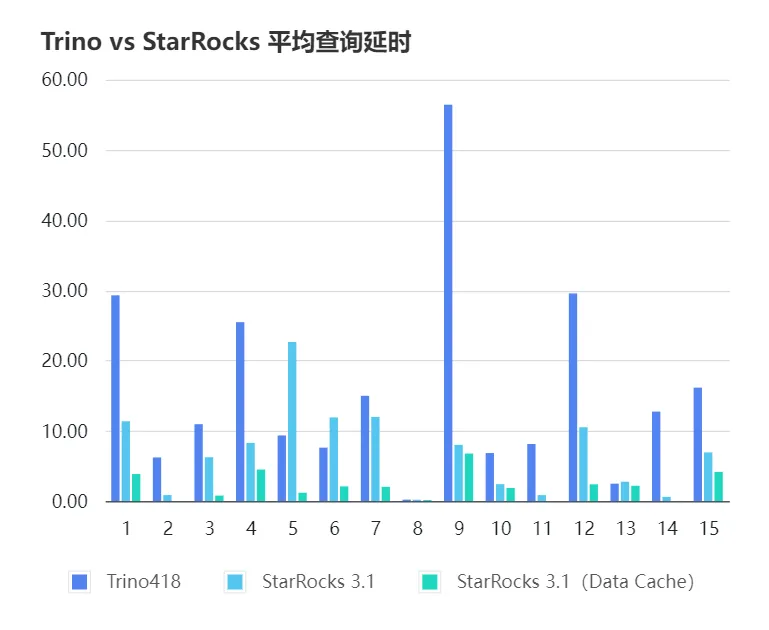
在同等配置的集群下,在未开启 DataCache 情况下,StarRocks 是 Trino 的2.2倍,在开启了 DataCache 之后,平均是 Trino 的7.4倍。
测试结果下:
图表中延时为每一类查询的平均延时。
03 StarRocks为什么能比Trino直查快
StarRocks 凭借其优秀的向量化引擎、pipeline 执行引擎、CBO、Global Runtime Filter 等特性,在复杂场景下的查询原生就具备优势。但是,湖上查询与内表不同,一方面数据在远端存储上,计算和存储不在一个节点会导致天然的网络开销。另一方面,元数据不是 StarRocks 托管的,很难像内表一样完全掌控统计信息用于加速查询规划和调度。
但是好在 StarRocks 也对湖上查询做了非常多的专项优化,主要分为两大块:
01 裸查加速优化
湖上查询加速的瓶颈主要在 I/O 跟元数据上。StarRocks 做了很多降低 I/O 的优化:
-
I/O 合并:根据查询情况自适应 I/O 合并,从而减少 I/O 次数;
-
延迟物化:首先对带谓词筛选的列进行过滤,定位目标行,再对应读取其他需要访问的列,减少 I/O 总量;
-
针对各类文件类型 Reader 的优化
同时 StarRocks 也针对做了元数据做了优化,包括元数据、统计信息的缓存以及更新机制。
02 Data Cache
StarRocks 查询 Hive 外表需要把远端数据拉取到BE节点进行计算,这一阶段比较消耗网络开销,也会对 HDFS 造成一定压力。并且,如果 HDFS 有抖动,也会对最终的响应时间有一定影响。
StarRocks 的 Data Cache 可以在用户第一次查询时异步地按照查询范围的 block 块缓存原始数据到 BE 节点,当后续查询命中 block 块时便可以直接从 BE 节点读取,避免了再次从 HDFS 取数。社区也在研发异步填充 Cache 的优化,从而让 Cache 填充本身不会对查询性能产生影响。
除了这些湖上的原生加速手段,StarRocks 还拥有一个其他湖仓架构没有的加速利器:物化视图。
03 物化视图锦上添花,整体 10 倍以上性能提升
虽然直接查询已经比 Trino 的性能好很多,但是还是有一些老大难的数据集不仅数据量大、查询复杂,业务的查询时延要求还较高。在这种情况下,原来我们只能将数据提前进行处理,然后将结果数据导入到 StarRocks 来进行加速。这意味着我们需要额外维护数据的加工及导入逻辑,用户的查询 SQL 也需要对应改到查询 StarRocks 内表。
通过物化视图可以方便、无痛地解决这个问题。物化视图具备如下几个特点:
- 自动异步加载数据
物化视图可以自己维护刷新的逻辑,尤其分区物化视图还能自动根据分区变更进行增量刷新,降低了维护成本。另外物化视图加载和处理数据的速度非常快,原来 Spark Load 耗时一小时的表,物化视图大概只需要 5 分钟。
- 透明加速
物化视图支持透明的查询改写,从而用户不用修改 SQL 便可借用物化视图进行查询加速,做到了对用户透明。
我们针对某个查询延时要求较高、数据量较大的场景进行了 PoC 验证。该场景需要对 16 亿行的大数据集进行聚合计算,由于数据量太大,全部导入内表基本不可能。然而,直接通过 Catalog 冷查询的性能在 1-2 分钟,不能满足业务需求。因此我们根据查询创建了物化视图。物化视图的大小缩小至 10GB 左右,整体刷新在 15 分钟内即可完成,基于物化视图的查询耗时缩短至了 2.5 秒以内,性能有 3-40 倍提升。
物化视图非常适合数据聚合加速的场景,应用可以非常灵活,在单表聚合、多表 join 在聚合等场景都能发挥价值。某特慢数据集从 Trino 转为 StarRocks Hive 外表+MV 的查询前后性能对比如下,可以看到在8月23日之后查询耗时有断崖式的下跌。
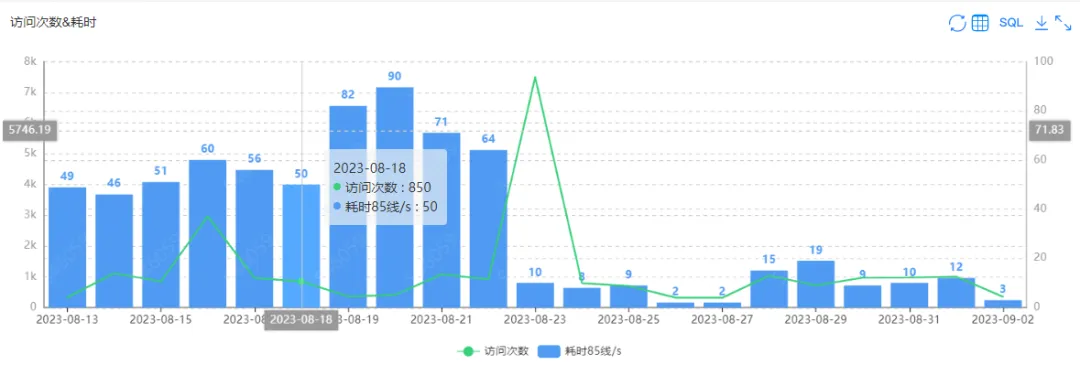
通过 Catalog+MV 的整体方案,提速非常显著, 已迁移 StarRocks Hive 外表的报表平均提速达到 10 倍,与 StarRocks 内表提速相当 。 目前已超过 10W 查询从 Trino 切到 StarRocks Hive 外表上。 用户体验得到显著提升。
最佳实践
接下来介绍在整个迁移过程中的一些经验:
01 语法兼容性 99%,为业务迁移打好基础
StarRocks 和 Trino 都有自己的方言,部分函数并不兼容。前期我们通过 Calcite 工具把 Trino SQL 转成 StarRocks SQL,这种方式解决了常见的兼容性问题。StarRocks 3.0.0 版本之后内置了语法兼容,可通过 set sql_dialect = “trino” 开启。其原理是通过设置 Trino 方言,把 Trino SQL 解析成 Trino AST,然后把Trino AST 转成 StarRocks AST,再进一步生成执行计划,复用 StarRocks 执行框架。 我们使用生产 SQL 反复测试得出其内置语法兼容性已经超过 99%,比例非常之高。
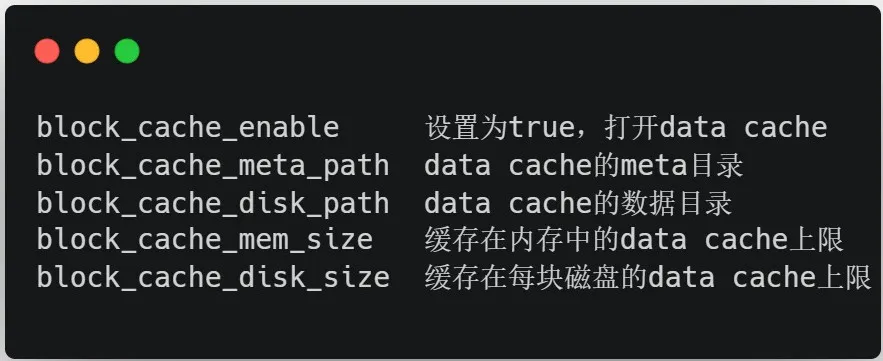
02 开启 Data Cache
Data Cache 是在 BE 节点上进行配置的,在配置时需要考虑到内存大小和磁盘的容量,如果 BE 磁盘容量过小可能效果并不理想。和社区讨论得知后续的版本中 Data Cache 的管理将更加精细化,可以配置缓存数据的规则,以及黑白名单等,其主要参数如下
03 创建合适的物化视图
物化视图特别合适加速重复聚合查询和周期性多表关联查询。为了能够让 MV 及时刷新,我们借助调度工具进行配置,与 MV 中的基表 Job 设置成依赖关系,当基表数据导入之后便可第一时间刷新 MV。
另外,如果刷新出现问题也可以借助调度工具进行告警通知。
04 DataNode混部
由于 Data Cache 和 MV 本质都是空间换时间,因此需要选择有存储的机器当做BE节点。为了合理利用资源,我们选择和 HDFS 的 DataNode 进行混部。在与 DataNode 同一块磁盘上,StarRocks 单独创一个目录,用来存储 MV 和 Data Cache 的数据
05 自动迁移
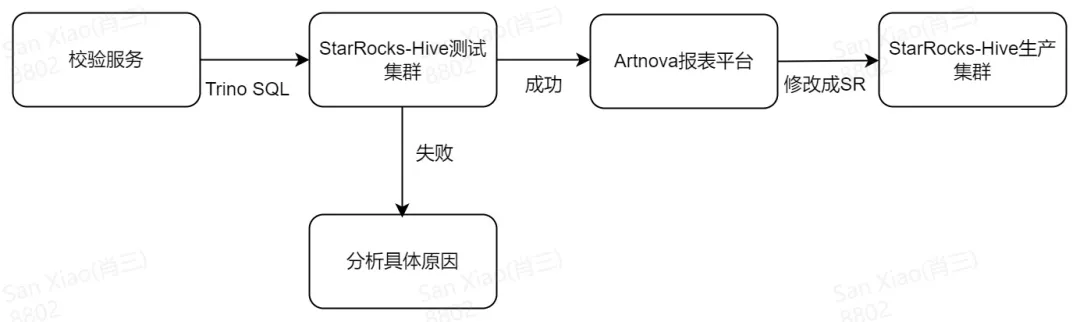
为了让引擎能够自助平滑的从 Trino 迁移到 StarRocks,我们设计了校验服务,每天把 TrinoSQL 回放到 StarRocks 测试集群,并分析 SQL 是否运行成功以及 SQL 结果的数据是否正确,如果运行失败则分析具体原因。Artnova 报表平台每天会选取部分测试成功的数据集从 Trino 切换到 StarRocks,同时会发送邮件告知其 owner。整个自动迁移服务如下图
后续优化方向
除了持续推动存量 Trino 查询迁移到 StarRocks 外表+物化视图的查询方式外,我们也在积极与社区沟通,探索进一步的数据加工提速方案以及产品优化方向
01 物化视图的智能推荐
当前 MV 的分析、创建、校验还是纯人工完成。为了能够更加节省人力,将物化视图的应用规模化,我们将联合社区探索物化视图的智能推荐,通过程序自动给出合理的物化视图建议。
02 物化视图的索引
MV 和 StarRocks 内表有相同的数据结构,为了进一步加速、充分利用 StarRocks 原生存储优势,我们开发了基于物化视图创建索引的功能,目前也已经贡献给社区。
03 通过StarRocks进行湖上ETL:Iceberg+DBT+StarRocks
StarRocks自3.1版本支持Iceberg写入的能力之后,我们就在尝试通过Iceberg+DBT+StarRocks 来把数仓的整体实效性进一步提升。在实际的测试过程中,发现 StarRocks 还有很多优化方向,例如:
- 支持 Iceberg V2 表的 equal-delete 读取
- 支持更新 Icerberg 文件(Merge Into语法)
- Iceberg 文件 compaction 及管理优化
目前,我们已经和 StarRocks 社区以及其他在这方面有需求的用户展开了深入的讨论与规划,并积极地参与到后续的研发工作中来。期待 StarRocks 能够在这一场景上发挥更大价值!