
作者:张博晗
理想汽车大数据平台-高级大数据开发
负责公司级数据集成平台的设计和开发,以及 OLAP 平台的体系化建设
对于致力创造移动的家、成为全球领先的智能电动车企业的理想汽车,所要管理的数据规模非常庞大。智能电动车是一个非常复杂的 IoT + 互联网场景,除了会产生 各种业务系统的数据、APP 埋点数据 外,还需要考虑汽车使用过程中传感器产生的 海量时序信号数据 。
除了庞大的数据量,智能电动车场景还依赖 强大的 OLAP 分析能力 ,去共同支持售后维护、OTA 升级、车辆的健康状况检测、早期预警以及维修保养等各种需求。
目前,理想汽车使用 Hadoop 数据湖技术栈,根据业务需求完成各种复杂的计算和分析任务,主要依靠 Spark SQL 和 Impala 共同支持 OLAP 多维分析、定制报表和 Ad-Hoc 数据分析等查询场景。
Hadoop 集群的扩容费时费力,有时甚至难以跟上业务的增长速度。 面对快速发展的业务,想要缓解业务对于敏捷性的高要求、维持业务运行的稳定,不够弹性的 Hadoop 让我们越来越力不从心。另外,传统的 Hadoop 架构为了应对网络延时和带宽的瓶颈,采用了计算和存储耦合部署的方式,增加计算意味着增加存储。 而存储和计算的匹配往往是错位的,不匹配的扩容也会带来很多冗余,造成不必要的浪费。 现如今,网络基础架构已经从当年的 1Gbps 发展到如今的 10Gbps、25Gbps 甚至是 100Gbps,网络在大数据架构中已经不再成为瓶颈,存储和计算分离的架构更加符合我们的需求。
业务的快速发展使得数据平台的转型迫在眉睫。经过内部多轮沟通和探索,发现 StarRocks 能以一套系统提供极速数据湖分析、高并发查询、实时分析等场景的解决方案,非常适合解决我们目前遇到的痛点,可以帮助理想汽车实现多场景极速统一分析:
一、将 Hadoop 集群的存储和计算进行解耦。 直接在 HDFS + Hive Metastore (HMS) 上构建数据湖,用于海量业务数据的存储。利用 StarRocks 的极速数据湖分析能力,直接分析 HDFS 上的数据,从而解决存储和计算错配的问题。同时利用 StarRocks 联邦查询的能力,使得 StarRocks 可以将 HDFS 上的数据源和其他数据源进行关联分析,省去数据在不同数据源迁移的成本。
二、构建强大的实时分析能力。 低延时分析要求的数据直接入库 StarRocks,利用 StarRocks 自身深度优化的数据存储结构、高效的分析引擎以及通用 SQL 能力的支持,使得我们能够以极低学习成本的方式进行实时数据分析。
#01
场景一:高效统一的数据湖分析引擎
—
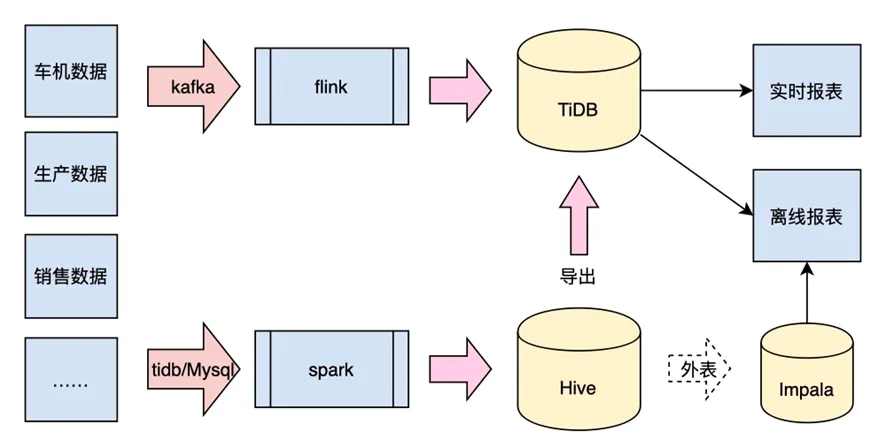
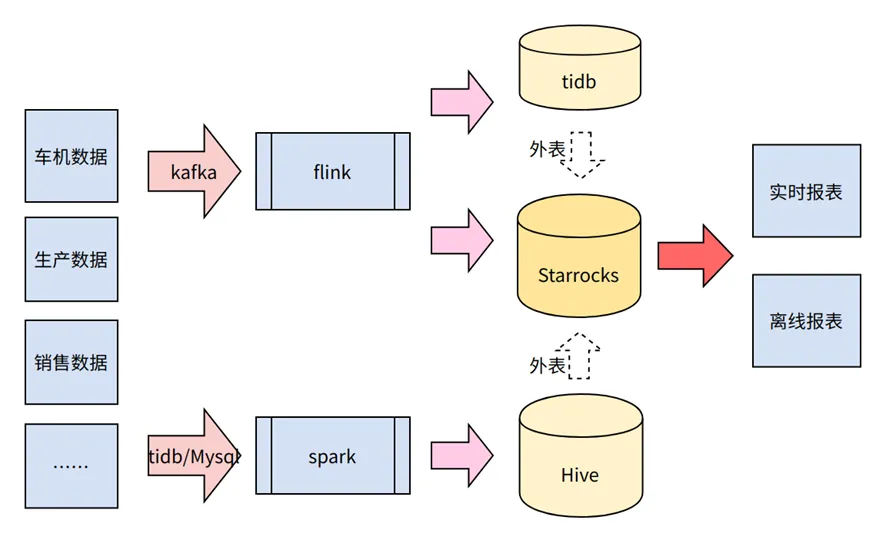
在引入 StarRocks 之前,我们用 Impala、TiDB 来提供离线报表的查询,用 TiDB 来提供实时数仓的查询能力,用 Spark SQL 来提供 AdHoc 查询能力。复杂的架构(如下图所示)给我们带来了很多困扰:
- 使用 Impala、TiDB 提供报表查询时,两种引擎中的数据没办法进行关联查询,经常需要互导数据,给数据处理带来很多额外成本。
- 使用 TiDB 提供实时数仓查询时,进行大表关联查询,经常无法满足业务方的查询延时要求。
- 使用 Spark SQL 提供的 AdHoc 查询能力时,遇到的问题与情况 1 类似,同样无法对 TiDB 中的数据进行关联查询。
我们看到 StarRocks 能以外部表的形式,接入其他数据源。外部表指的是保存在其他数据源中的数据表。StarRocks 可以直接向外部表所在数据源发起查询,并且可以对多引擎中的数据进行关联,而且查询性能比较强悍。这使得通过 StarRocks 形成统一的数据查询入口成为可能。
因此,我们选型的重点落在了用 StarRocks 外表替换 Impala 的角度上。
以下是 StarRocks 和 Impala 基准测试概况:
测试环境
Hadoop / Hive MetaStore 和 Impala / StarRocks 分别运行在两个集群上,集群之间跨网络读取数据,地处相同机房,这样将计算和存储进行分离。Impala / StarRocks 集群分别有 3 个节点,每个节点的配置都是 16vCPU 和 64GB 内存。
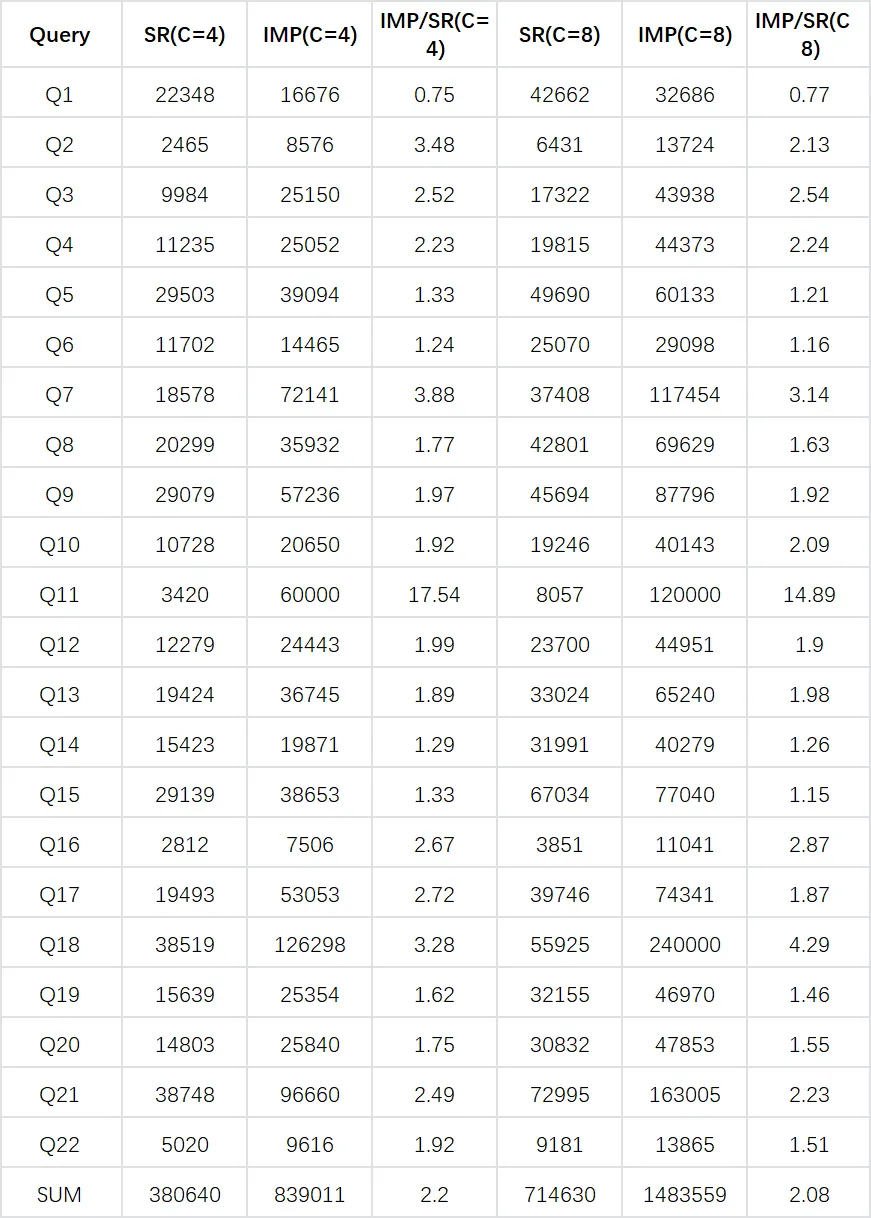
我们分别用 StarRocks 的 Hive 外表和 Impala,在 4 并发和 8 并发下,对 TPC-H 100Scale 规模数据集进行了对比测试,测试结果如下:
注:Impala 在运行 Q18 的时候出现过 OOM,Q11 不支持 Having 子句,所以这两栏使用了自定义的数字代替。
Impala 负载情况(C=8)
CPU、内存和网络几乎都压到了极限
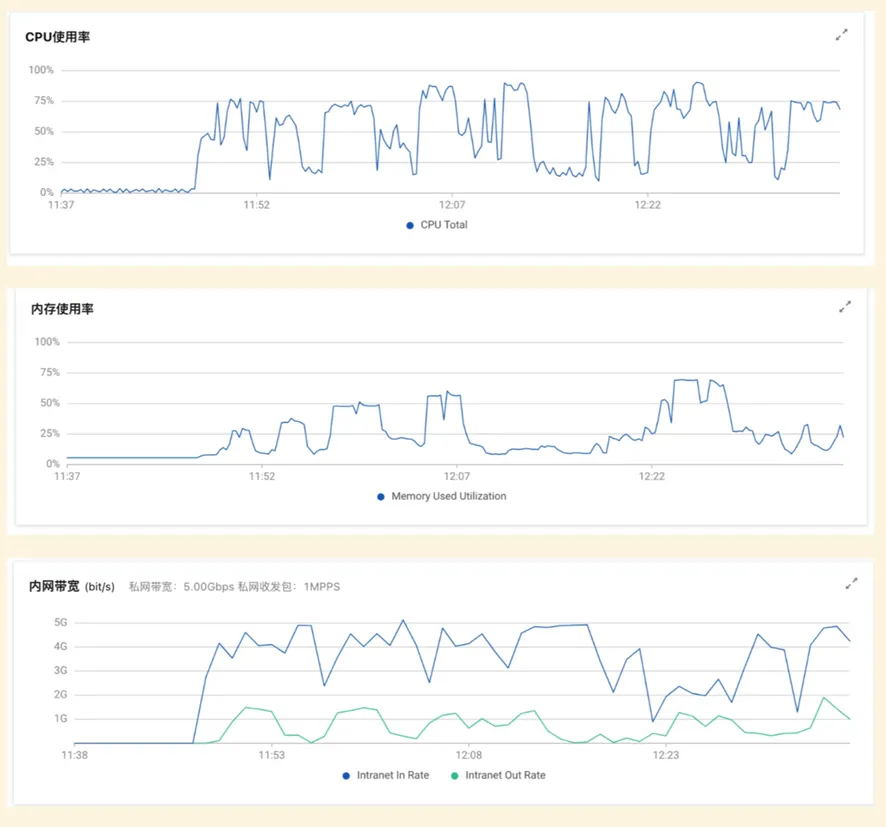
StarRocks 负载情况(C=8)
CPU 几乎压到极限,内存使用看起来比较顺滑
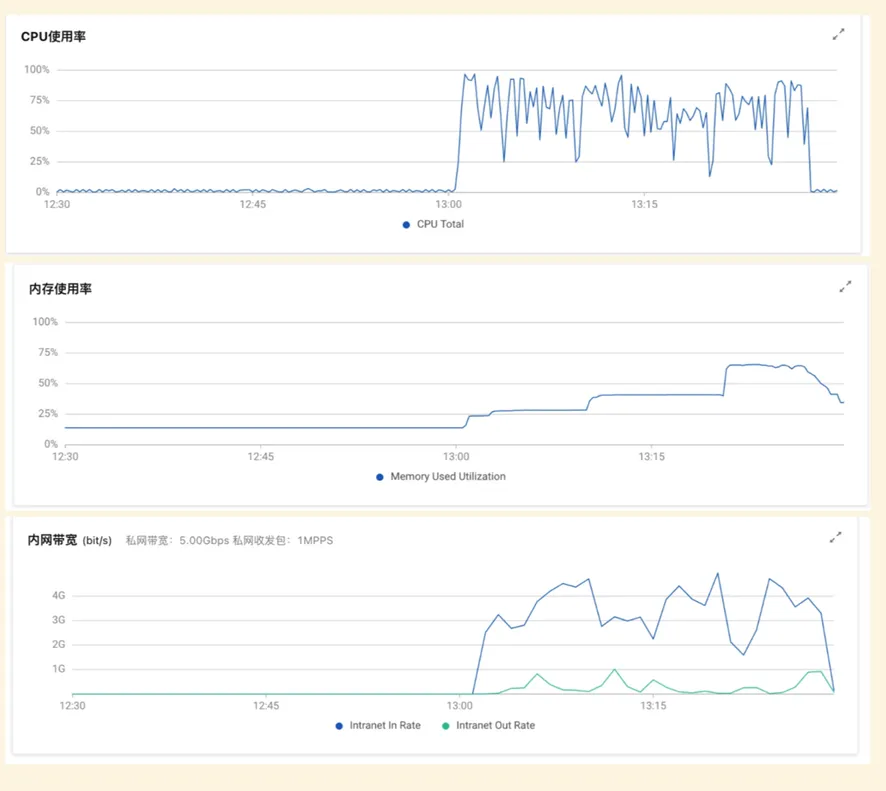
综上,StarRocks 的 Hive 外表,在相同硬件规格条件下,运行在 TPC-H 100Scale 规模数据集,查询性能是 Impala 的 2 倍以上。这些是两者都在存储计算分离情况下,基于测试数据集得到的性能分析。
在真实业务场景下,原来 Impala 计算和 Hive 存储耦合在一起,但是我们把 StarRocks 计算和 Hive 存储进行了分离,这样存储和计算可以单独弹性扩展,存储计算分离后查询性能也实现了不错的提升,性能是原有存储计算耦合时 Impala 的 1.6 倍。当然,对于理想汽车的业务场景来讲,StarRocks 能通过外表的方式覆盖全部 Impala 场景,并且能够和 TiDB 进行 Join 查询,就已经坚定了我们用 StarRocks 替换 Impala 的决心了。最终带来了不俗的性能提升,更是意外之喜。
收益
采用基于 StarRocks 的 OLAP 查询新方案后,我们下线了 Impala 服务,减轻了 Hadoop 集群运维压力。通过多引擎 Join 的外表查询功能,系统用户可以在看板上对 Hive 和 TiDB 表直接进行关联查询,减短了数据加工的链路,效果非常理想。
#02
场景二:实时画像标签系统
—
我们希望通过这一系统打造公司级画像数据服务,提供标签生产及标签元数据管理功能,促进各业务用户画像"数据供给"和"数据消费"高效匹配。面向运营、产品、分析师、用户研究、设计、市场营销、数据研发、系统研发等角色,画像平台系统需要实现的功能有:
- 实时+离线标签的生产能力,收录各业务用户画像数据资产。
- 为用户标签查询服务与跟进标签圈选用户群服务提供支持,满足业务"寻找目标群体、查询目标群体具体的属性/特征、判断画像描述对象是否符合业务策略"的诉求。
- 以数据服务的方式应用在用户运营、市场营销、数据分析、数据研发等业务场景中。
理想汽车旧版的标签系统主要是用 ElasticSearch 来做,在开发迭代上不够灵活,不能写 SQL,基本都是定制开发。经过调研,StarRocks 可以基于 Roaring Bitmap 来做客群圈选,方便地把前端圈群的动作翻译为交集、并集、异或等关系计算,大大简化了 SQL 开发的复杂度,拓展了业务实现的想象空间。故此,我们基于 StarRocks 对圈选业务进行了重新梳理和升级改造。
架构方面,通过 Spark 生成 T+1 数据标签,导入 StarRocks。通过 Flink 对实时数据进行加工,将近线数据进行补充。在离线层和加速层加持下,不断将新数据存入 StarRocks 中,同时保证既有数据的完整性。
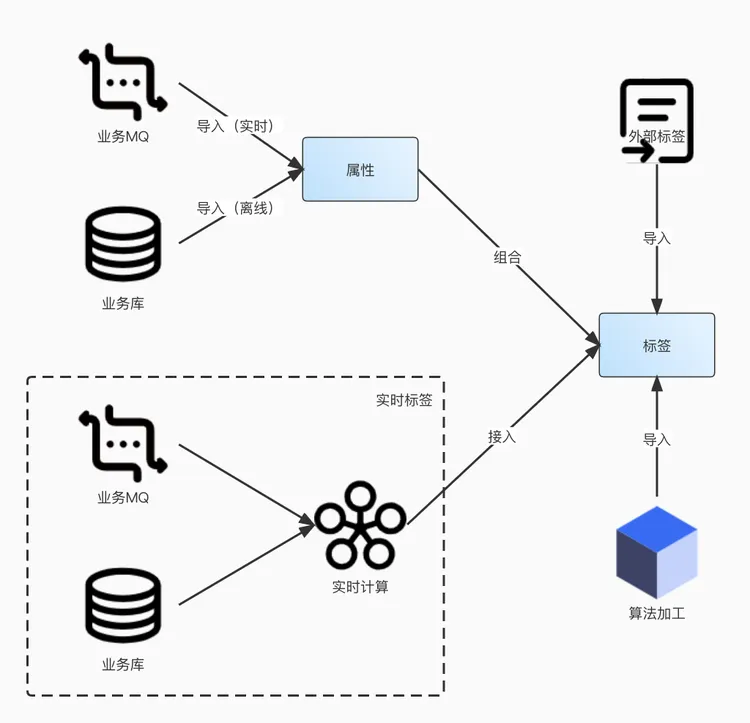
下图是数据落地到 StarRocks 中的工作。离线数据和实时数据,写入了不同的表;加工好的离线标签数据,导入宽表模型;实时加工的数据,采用高表的模型。实时进行写入、读取时,对两表进行 Join,这样可以更好地应用 StarRocks 进行查询加速。
收益
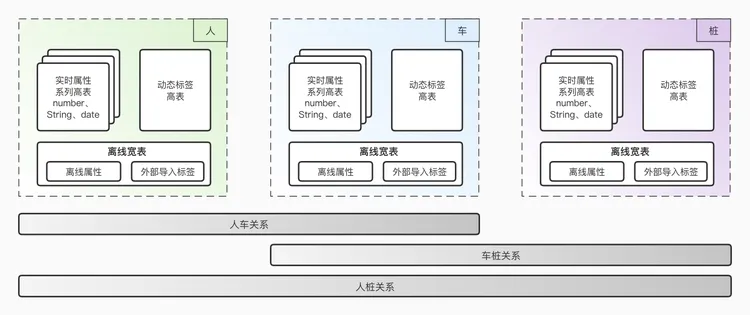
- 整体提供了更具时效性的人、车、桩的把控。借助 StarRocks 高效的多表关联能力和灵活的 Bitmap 集合计算能力,我们不仅可以在人、车、桩某一个要素体系内进行分析查询,还可以跨域圈选,实现了人车关系、车桩关系和人桩关系的要素交叉分析。
- 工程实现上,Bitmap 集合 Bitwise 计算语义清晰,可以很好的把 UI 的圈选动作翻译过来,从而使得我们轻松完成了全新的配置化页面的设计,能够提供复杂外显指标在线计算。我们下线了通过代码、复杂 SQL 子查询嵌套、脚本等方式开发计算指标的历史通道,整体业务的复杂性大大降低,人效得到提升。
- 应用上,新系统提供了基于人、车、桩的实时特征多维查询分析。针对碰撞告警、故障预警等场景,大数据平台团队与算法团队共同开展了一系列工程改造实践,整体响应速度较老系统有明显提升。
#03
总结与展望
—
综上,通过 StarRocks 构建了一套湖仓一体的数据架构,这套架构让我们能够低成本存储海量数据,也能够进行高效实时的数据分析,从而灵活应对各种业务分析场景。
我们一直在跟进 StarRocks 社区的发展。早期对 StarRocks 不熟悉时,在使用中遇到了很多问题,感谢社区小伙伴积极帮忙并快速解决了问题。
使用过程中,我们发现了以下几点需要改进的地方:
- 针对 Hive 外表的元数据刷新机制还不是很完善。针对一些分区较多的表,首次加载 Hive 元数据会比较慢,用户的直接感受就是SQL 查询偶尔较慢。StarRocks 社区反馈 2.2 版本以后会增加元数据增量更新的功能,届时将不再需要手动刷新元数据缓存。
- 希望官方能尽快推出资源隔离、存算分离等功能。
在我们今年的工作规划中,一方面会在公司内部各业务部门进行推广并测试高并发的主键点查, 尝试基于 StarRocks 打造 HSAP(Hybrid Serving/Analytical Processing)架构 。另一方面,我们也开始 将 StarRocks 与公司的大数据平台进行更深度的集成,开发如数据管道、数据库管理工具等更丰富的 StarRocks 周边工具 ,降低用户的使用门槛。
随着业务的发展和使用的深入,我们也会投入更专业的人才来进行底层溯源和改造优化。相信我们可以更好地和 StarRocks 社区合作,让 StarRocks 可以覆盖更多的场景,打造满足业务发展的湖仓一体的数据库产品。