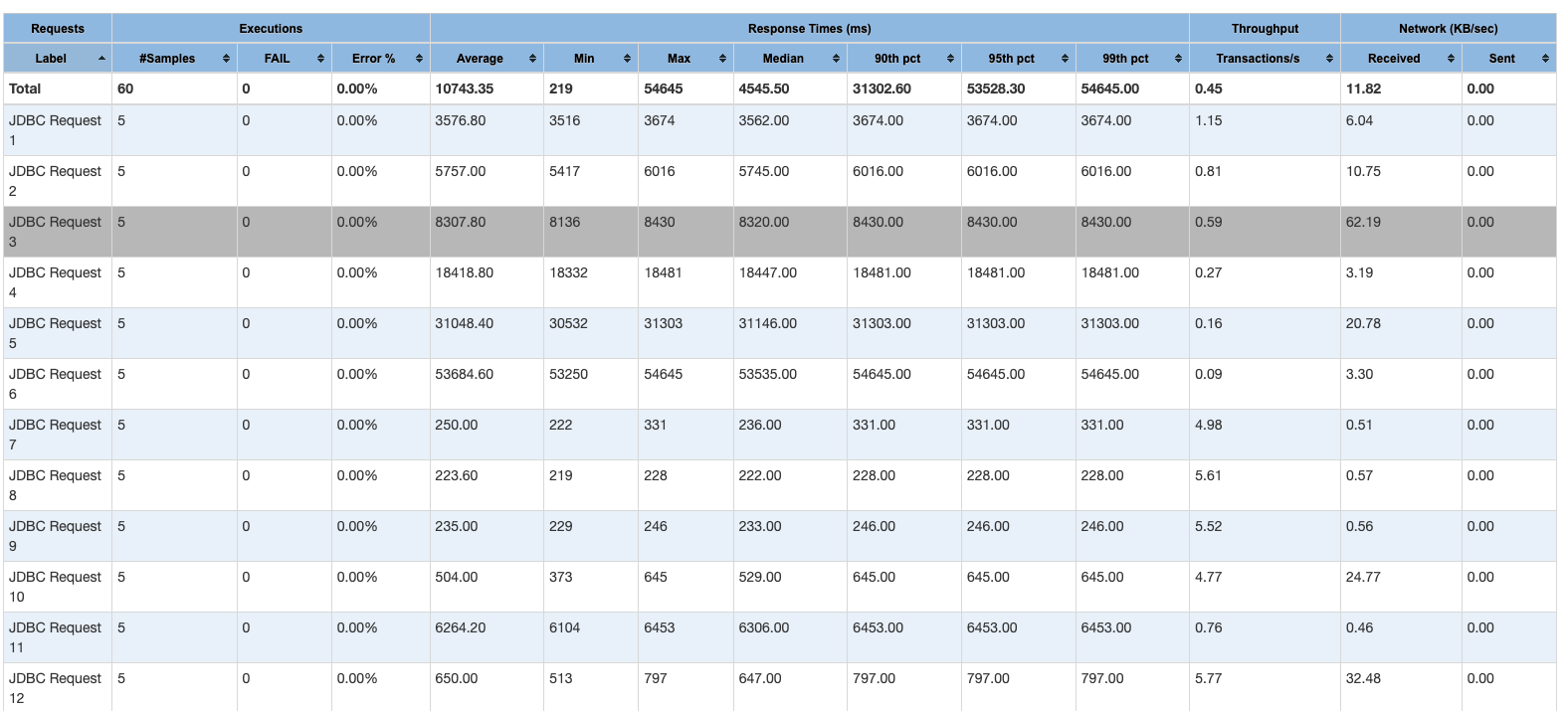
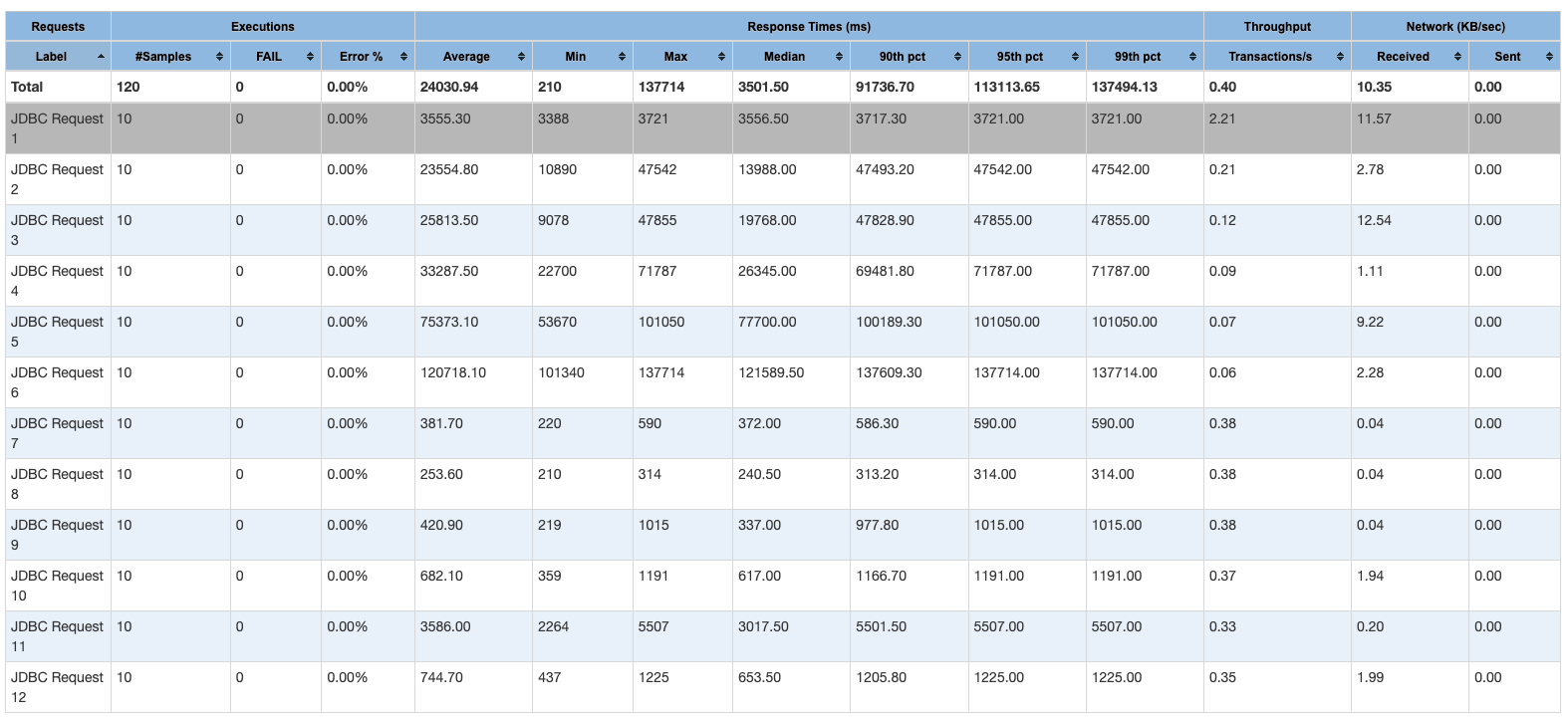
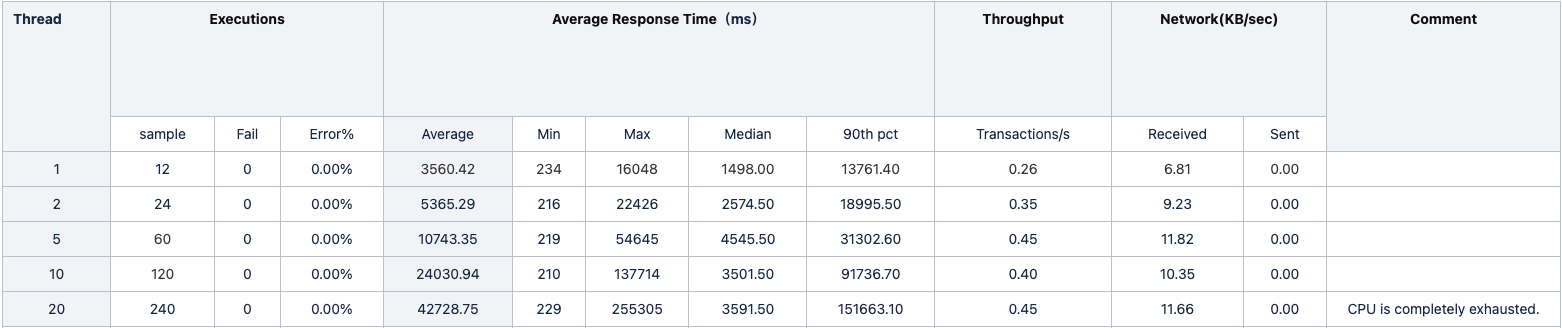
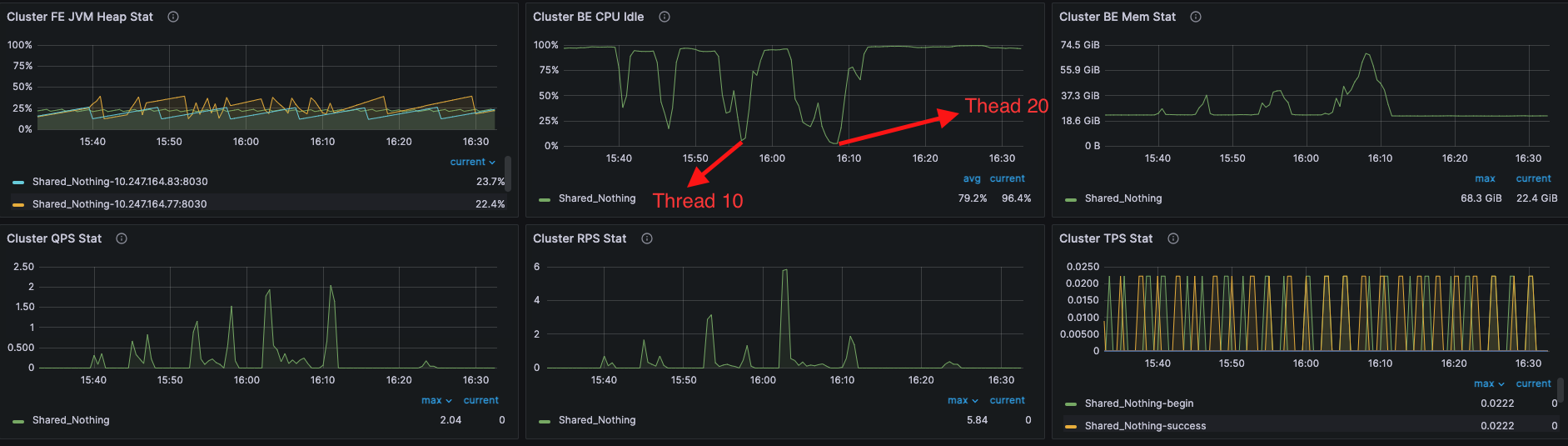
【详述】使用Jmeter进行压测,观察Starrocks的并发查询结果,根据截图1,Starrocks确实是并发处理的。我的jmeter是在本地测试的,然后选取了12条真实业务的sql,sql访问的同一张表,查询结果的统计如图二所示。可以发现,并发查询结果特别不理想,基本上查询时延和并发数都接近正比了,这非常不合理。想请问下这就是SR的正常水平吗?
【背景】没做过额外的操作
【业务影响】
【是否存算分离】否
【StarRocks版本】3.3.0
【集群规模】例如:3fe(3 follower)+13be(fe与be不混部)
【机器信息】32核 * 128G
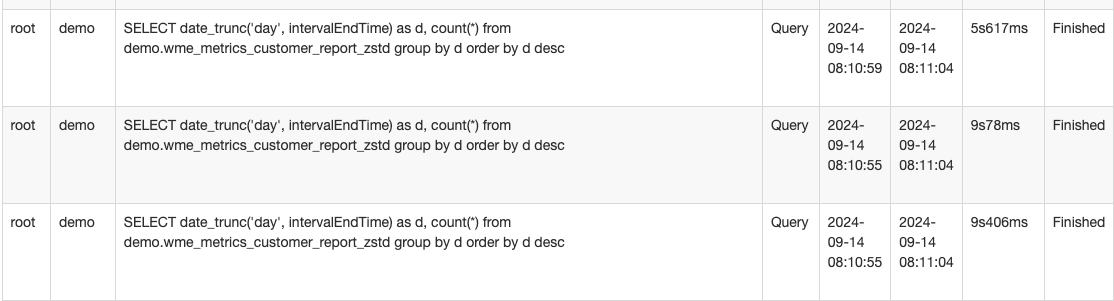
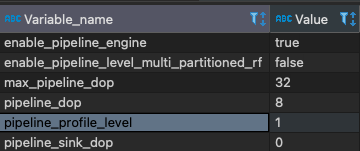
备注:
- 这是pipeline的相关参数,我的be是32核
- 至于查询队列我觉得现阶段应该不是关键因素,我是默认没开启的。
- 我不确定我在本地测试而且还是所有的sql都是同一张表有什么影响
 ?
?