为了更快的定位您的问题,请提供以下信息,谢谢
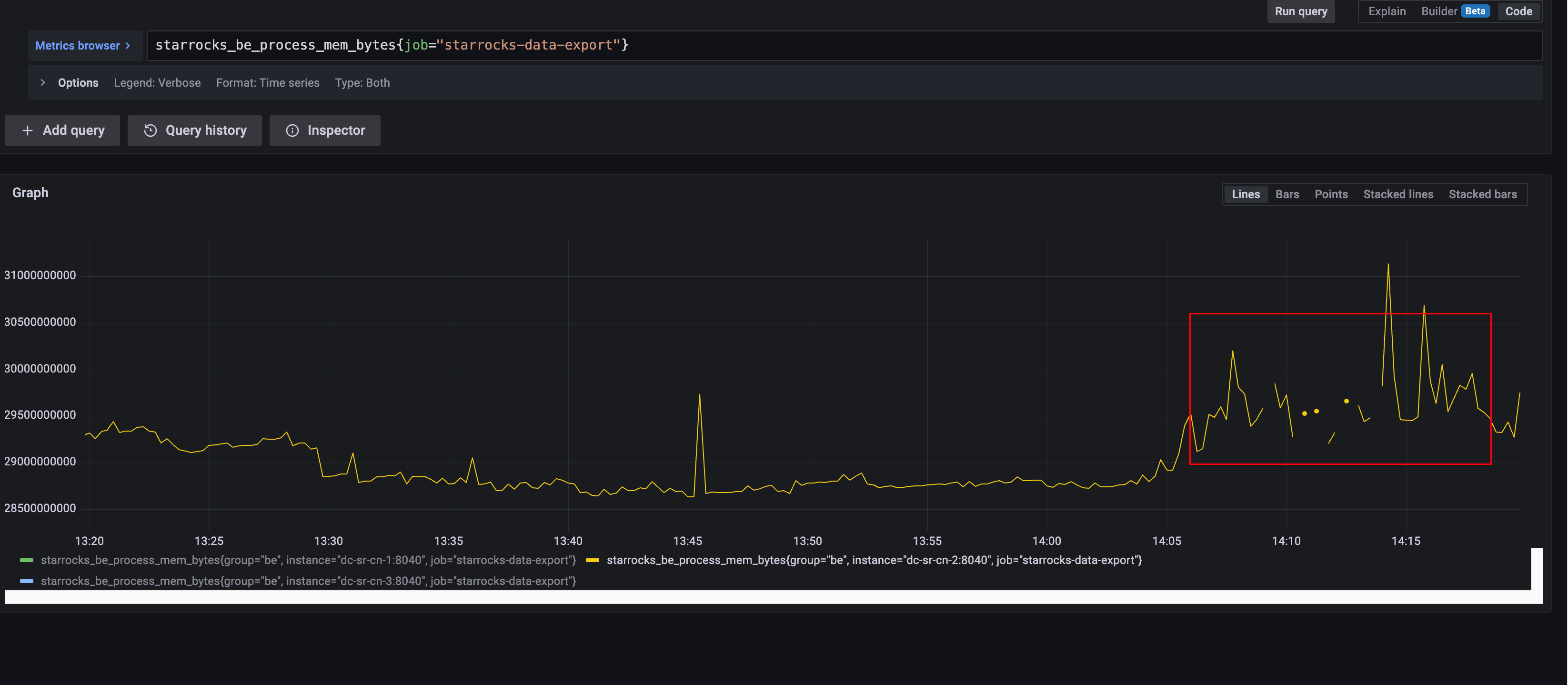
【详述】存算分离的SR集群使用S3作为远程存储,使用prometheus采集FE和CN的metrics来做监控,在grafana中配置dashboard监控集群状态,生产稳定运行一周后最近发现有频繁的FE和CN的metrics获取不到的情况
【背景】对于SR集群没有进行过任何操作,开始怀疑是prometheus采集的target太多的原因,所以干脆重建了一个prometheus,只针对这个SR集群进行采集metrics,同时老的prometheus也在采集,通过一段时间的观察,发现两个prometheus采集的指标都存在指标中断的情况,并且时间范围差不多,只不过时间点并不完全一致。
【业务影响】监控指标采集不全
【是否存算分离】是
【StarRocks版本】3.3.2
【集群规模】例如:3fe(1 follower+2observer)+3cn(fe与be分开部署)
【机器信息】CPU虚拟核/内存/网卡,例如:32C/128G/万兆
【联系方式】社区群16-一叶
【附件】
FE和CN都没有任何异常的日志,而且内存,CPU,磁盘IO,系统负载 都在正常合理的范围内
prometheus开启了debug日志后打印了下面的日志
Sep 11 15:13:33 dc-eks-node-01 prometheus[3379631]: ts=2024-09-11T07:13:33.413Z caller=scrape.go:1347 level=debug component=“scrape manager” scrape_pool=starrocks-data-export target=http://dc-sr-cn-2:8040/metrics msg=“Scrape failed” err=“Get “http://dc-sr-cn-2:8040/metrics”: context deadline exceeded”