【详述】starrocks周日突然发现flink写starrocks写不进去,建表也建不了。
【业务影响】starrocks写入数据失败。
【StarRocks版本】 2.0.0-GA
【集群规模】例如:3fe+3be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:16C/64G/万兆
【附件】
出问题时候,后台的be一直报这个错误

其次,我在创建表的时候,一直报这个错误

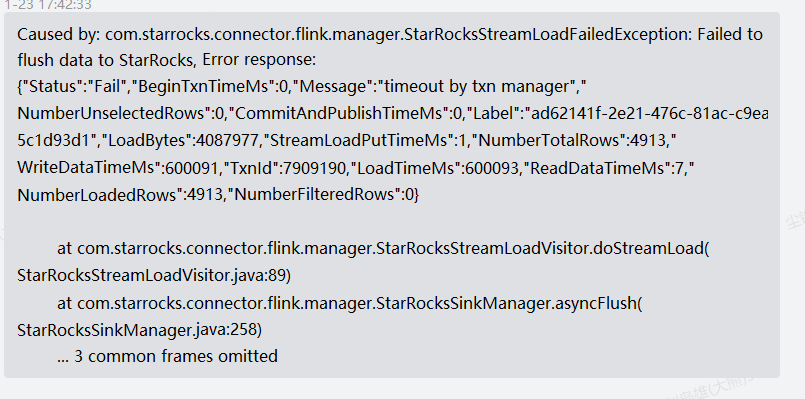
最后,开发反馈,相关的报错信息为:

【详述】starrocks周日突然发现flink写starrocks写不进去,建表也建不了。
【业务影响】starrocks写入数据失败。
【StarRocks版本】 2.0.0-GA
【集群规模】例如:3fe+3be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:16C/64G/万兆
【附件】
出问题时候,后台的be一直报这个错误
重启be后,恢复,但是这个问题希望定位一下,这已经是第二次出现了。
flink是多久写入一次呢,麻烦发下sink的配置
另外除了flink导入,没有其他stream load或者jdbc方式导入吧?
StarRocks:
sink.buffer-flush.interval-second: 30
sink.buffer-flush.max-mb: 90
sink.buffer-flush.max-rows: 200000
30秒 90MB 200000 行 谁先到就写
目前我们这3台starrocks,就是专门用来flink 写,对了,写的表都是primary key的数据模型的表
写入是json数据吗
是的,开发这边把数据一般合并成json,starrocks的flink connector本身其实也是Streamload的嘛。
.withProperty(“table-name”, table)
.withProperty(“database-name”, db)
.withProperty(“sink.properties.format”, “json”)
.withProperty(“sink.properties.strip_outer_array”, “true”)
.withProperty(“sink.buffer-flush.max-rows”, “100000”)
.withProperty(“sink.buffer-flush.max-bytes”, “94371840”)
.withProperty(“sink.buffer-flush.interval-ms”, “30000”);
flink connector底层走的stream load。报错原因是写入事务超时了,可能是导入频率高导致的写入事物比较多。可以看下be.warn的日志,另外flink日志中搜下"_stream_load"关键字,确认下每次触发flush的是哪个条件。
我们配置的1分钟的checkpoint,通过看了源码发现 SS 是checkpoint的时候会全部flush 一次,会不会是 正常的 flush 之后,checkpoint刚好触发,导致 两次 flush 间隔非常短导致?
不会,配置了checkpoint回按照checkpoint来flush,其他的参数就不生效了。
看了源码并不是呢,我们用的at least once ,看了源码 exactly once 是你说的只会通过ck 来flush 但at least once 不是
public final synchronized void writeRecord(String record) throws IOException {
checkFlushException();
try {
byte[] bts = record.getBytes(StandardCharsets.UTF_8);
buffer.add(bts);
batchCount++;
batchSize += bts.length;
if (StarRocksSinkSemantic.EXACTLY_ONCE.equals(sinkOptions.getSemantic())) {
return;
}
// at least once 依旧会按照参数 flush
if (batchCount >= sinkOptions.getSinkMaxRows() || batchSize >= sinkOptions.getSinkMaxBytes()) {
String label = createBatchLabel();
LOG.info(String.format("StarRocks buffer Sinking triggered: rows[%d] label[%s].", batchCount, label));
flush(label, false);
}
} catch (Exception e) {
throw new IOException("Writing records to StarRocks failed.", e);
}
}你说的没错at least once在 达到阈值或checkpoint时都会flush,exactly once 的flush只跟ck的周期相关。
这个改成1000000观察下吧。
我们用的exactly once,checkpoint的时间设置的是3分钟,在一次checkpoint完成之后插入数据,直接就flush到starrocks里了,没有等三分钟再flush啊
sink的参数少了配置sink.semantic