
1. Iceberg 介绍
1.1 什么是Iceberg
Iceberg是一个面向海量数据分析场景的开放 表格式(Table Format)。 表格式可以理解为元数据以及数据文件的一种组织方式,处于计算框架(Flink,Spark…)之下,数据文件之上。
可以跟一些主流的框架做集成
1.2 Iceberg的特性
1.2.1 Iceberg支持隐藏分区
隐藏分区 :可以指定分区字段做计算,计算的结果不用体现在字段定义中
1.2.2 Iceberg支持表演化
Iceberg可以通过SQL的方式进行表级别模式演进。进行这些操作的时候,代价极低。 不存在读出数据重新写入或者迁移数据这种费时费力的操作。
1.2.3 Iceberg支持Scheme 演化
Iceberg支持下面几种模式演化:
ADD:向表或者嵌套结构增加新列
Drop:从表中或者嵌套结构中移除一列
Rename:重命名表中或者嵌套结构中的一列
Update:将复杂结构(struct, map<key, value>, list)中的基本类型扩展类型长度, 比如tinyint修改成int.
Iceberg保证模式演化(Schema Evolution)是没有副作用的独立操作流程, 一个元数据操作, 不会涉及到重写数据文件的过程。具体的如下:
增加列时候,不会从另外一个列中读取已存在的的数据
删除列或者嵌套结构中字段的时候,不会改变任何其他列的值
更新列或者嵌套结构中字段的时候,不会改变任何其他列的值
改变列列或者嵌套结构中字段顺序的时候,不会改变相关联的值
在表中Iceberg 使用唯一ID来定位每一列的信息。新增一个列的时候,会新分配给它一个唯一ID, 并且绝对不会使用已经被使用的ID。
使用名称或者位置信息来定位列的, 都会存在一些问题, 比如使用名称的话,名称可能会重复, 使用位置的话, 不能修改顺序并且废弃的字段也不能删除。
1.2.4 Iceberg支持分区演化
Iceberg可以在一个已存在的表上直接修改,因为Iceberg的查询流程并不和分区信息直接关联。
改变一个表的分区策略时,对应修改分区之前的数据不会改变, 依然会采用老的分区策略,新的数据会采用新的分区策略,也就是说同一个表会有两种分区策略,旧数据采用旧分区策略,新数据采用新新分区策略, 在元数据里两个分区策略相互独立,不重合。
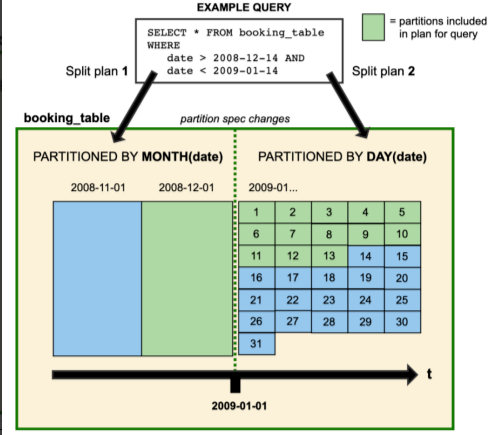
上图中booking_table表2008年按月分区,进入2009年后改为按天分区,这种中分区策略共存于该表中。
借助Iceberg的隐藏分区(Hidden Partition),在写SQL 查询的时候,不需要在SQL中特别指定分区过滤条件,Iceberg会自动分区,过滤掉不需要的数据。
Iceberg分区演化操作同样是一个元数据操作, 不会重写数据文件。
1.2.5 Iceberg支持列顺序演化
Iceberg可以在一个已经存在的表上修改排序策略。修改了排序策略之后, 旧数据依旧采用老排序策略不变。往Iceberg里写数据的计算引擎总是会选择最新的排序策略, 但是当排序的代价极其高昂的时候, 就不进行排序了。
1.3 Iceberg数据类型
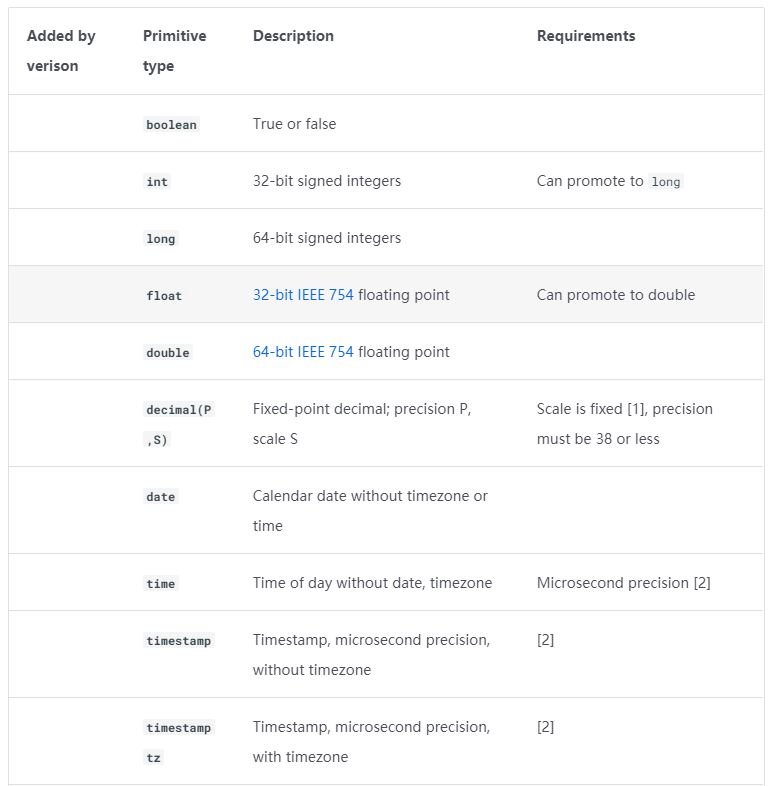
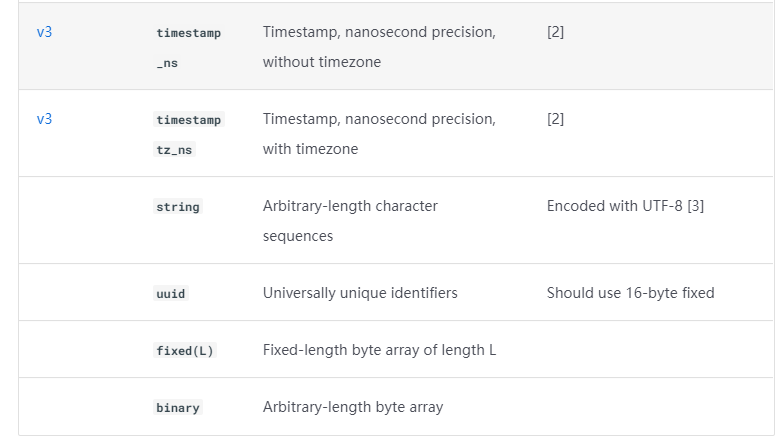
详细可以参考官网文档:https://iceberg.apache.org/spec/?h=data+type#primitive-types
1.4 Iceberg存储结构
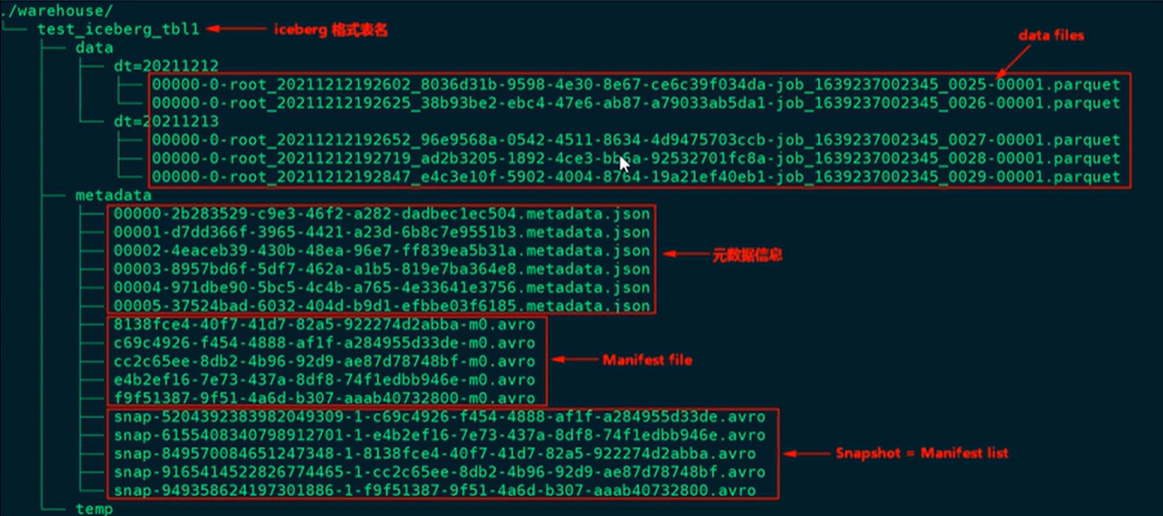
这个表是在hive底下存储的,上图中data是真正的数据目录,metadata 是元数据
data files : 真实存储数据的文件。一般是在表的数据存储目录的data目录下,是以parquet格式存储的 (什么时候会生成parquet文件?每一次向表里插入数据,就会生成一个parquet( 每一次操作iceberg,都会生成一个parquet文件 )
Manifest file: 清单文件,每次生成parquet的时候都会生成一个清单文件
每一个manifest file文件都指向parquet的详细描述(表是哪个表,分区是哪个分区,分区列是什么,包含几条数据)
Manifest list: manifest list是一个元数据文件,它列出构建表快照(Snapshot)的清单(Manifest file)。这个元数据文件中存储的是Manifest file列表,每个Manifest file占据一行。
Metadata file: 元数据文件,以json格式存储
snapshot: 就等于 Manifest list 表快照。每一个avro文件对应一个snapshot. 【每操作一次iceberg表,都会生成一个data file,同时也会生成一个snapshot】 快照可以回滚
注意:向上图表中插入一条数据,生成一个parquet文件,parquet生成manifest file ,生成的manifest file 会存储在snapshot 中,
插入第二条一条数据,会再生成一个parquet文件,parquet生成manifest file ,新的manifest file文件和第一个manifest file 存储在第二个snapshot中。
2. Iceberg与Hive集成
这里使用的 hive版本是3.1.2 , iceberg版本是1.1.0
2.1 环境准备
1)Hive与Iceberg的版本对应关系如下
| Hive 版本 | 官方推荐Hive版本 | Iceberg 版本 |
|---|---|---|
| 2.x | 2.3.8 | 0.8.0-incubating – 1.1.0 |
| 3.x | 3.1.2 | 0.10.0 – 1.1.0 |
Iceberg与Hive 2和Hive 3.1.2/3的集成,支持以下特性:
·创建表
·删除表
·读取表
·插入表(INSERT into)
更多功能需要Hive 4.x(目前alpha版本)才能支持。
2). 上传jar包,拷贝到Hive的auxlib目录中
用到以下两个jar包
mkdir auxlib
cp iceberg-hive-runtime-1.1.0.jar /opt/module/hive/auxlib
cp libfb303-0.9.3.jar /opt/module/hive/auxlib
3)修改hive-site.xml,添加配置项
<property>
<name>iceberg.engine.hive.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.aux.jars.path</name>
<value>/opt/module/hive/auxlib</value>
</property>
4)使用TEZ引擎注意事项(可选):
(1)使用Hive版本>=3.1.2,需要TEZ版本>=0.10.1
(2)指定tez更新配置:
<property>
<name>tez.mrreader.config.update.properties</name>
<value>hive.io.file.readcolumn.names,hive.io.file.readcolumn.ids</value>
</property>
(3)从Iceberg 0.11.0开始,如果Hive使用Tez引擎,需要关闭向量化执行:
<property>
<name>hive.vectorized.execution.enabled</name>
<value>false</value>
</property>
5)启动HMS服务
6)启动 Hadoop
2.2 创建 管理catalog
Iceberg支持多种不同的Catalog类型,例如:Hive、Hadoop、亚马逊的AWS Glue和自定义Catalog。
根据不同配置,分为三种情况:
·没有设置iceberg.catalog,默认使用HiveCatalog
| 配置项 | 说明 |
|---|---|
| iceberg.catalog.<catalog_name>.type | Catalog的类型: hive, hadoop, 如果使用自定义Catalog,则不设置 |
| iceberg.catalog.<catalog_name>.catalog-impl | Catalog的实现类, 如果上面的type没有设置,则此参数必须设置 |
| iceberg.catalog.<catalog_name>. | Catalog的其他配置项 |
·设置了 iceberg.catalog的类型,使用指定的Catalog类型,如下表格:
·设置 iceberg.catalog=location_based_table,直接通过指定的根路径来加载Iceberg表
2.2.1 默认使用 HiveCatalog
## 创建表
CREATE TABLE iceberg_test1 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
注意:STORED BY 指定类名使iceberg_test1成为iceberg表
如果使用的是hive 4, STORED BY 'Iceberg' (类名只需要写Iceberg即可)
## 插入数据
INSERT INTO iceberg_test1 values(1);
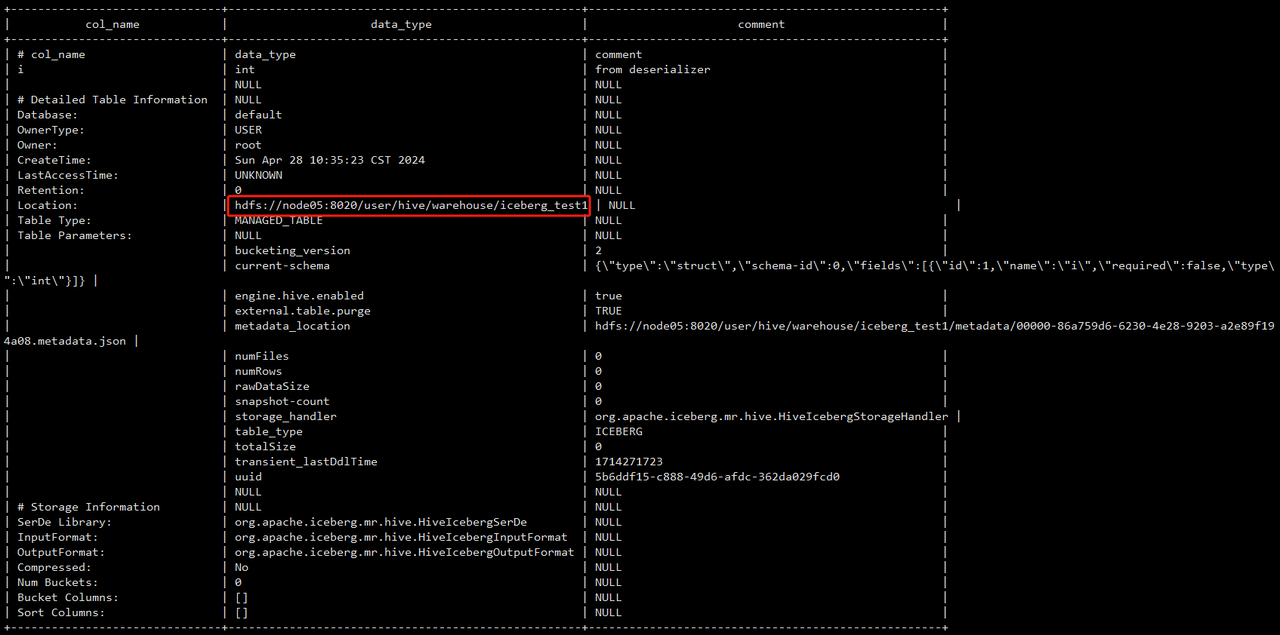
## 查看表:
describe iceberg_test1;
## 查看表的详细信息:
describe formatted iceberg_test1;
创建的表目录在默认的hive仓库路径下。
2.2.2 指定 Catalog 类型
1)使用 HiveCatalog
set iceberg.catalog.iceberg_hive.type=hive;
## iceberg.catalog 前缀是固定的
## iceberg_hive: <catalog_name>是自定义的,但是下边的<catalog_name>需要保持一致
## type:catalog的类型
set iceberg.catalog.iceberg_hive.uri=thrift://192.168.110.120:9083;# 元数据服务的地址
set iceberg.catalog.iceberg_hive.clients=10;# 连接并行数,可设置也可以不设置
#不设置warehouse
set iceberg.catalog.iceberg_hive.warehouse=hdfs://192.168.110.120:8020/warehouse/iceberg-hive; #仓库路径的地址。也是可指定可不指定;不指定默认是hive-site里配置的默认仓库路径地址 (3.1.2版本指定仓库路径地址未生效,实际还是使用的hive-site.xml中的仓库路径地址)
--建表
CREATE TABLE iceberg_test2 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
TBLPROPERTIES('iceberg.catalog'='iceberg_hive'); ##用上边创建好的catalog
INSERT INTO iceberg_test2 values(1);
2)使用 HadoopCatalog
set iceberg.catalog.iceberg_hadoop.type=hadoop;#iceberg_hadoop:<catalog_name>
set iceberg.catalog.iceberg_hadoop.warehouse=hdfs://192.168.110.120:8020/warehouse/iceberg-hadoop;
--建表
CREATE TABLE iceberg_test3 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://192.168.110.120:8020/warehouse/iceberg-hadoop/default/iceberg_test3'
TBLPROPERTIES('iceberg.catalog'='iceberg_hadoop');
##使用hadoop catalog时必须指定location,location需要跟catalog仓库路径地址保持一致;
##后边需要写上库名表名,默认是default库下
INSERT INTO iceberg_test3 values(1);
Hive catalog 和hadoop catalog的区别
区别在于元数据文件的名称,可以在hdfs中查看metadata进行区分
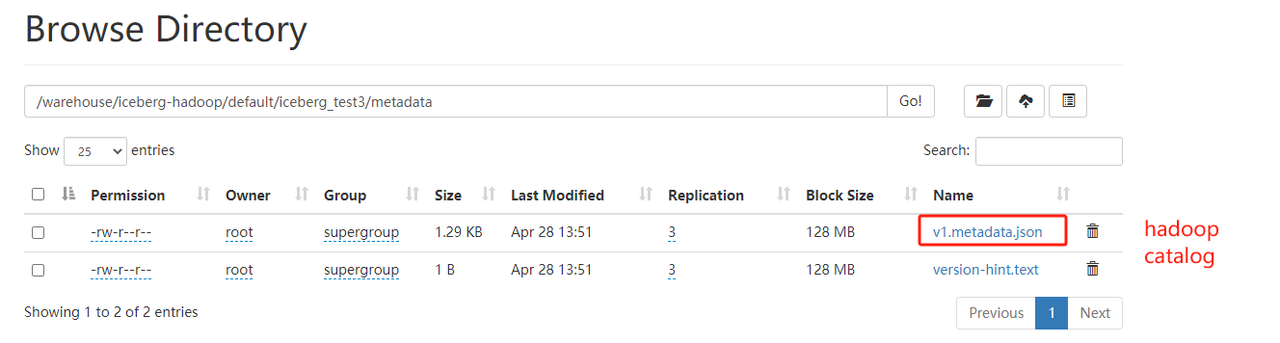
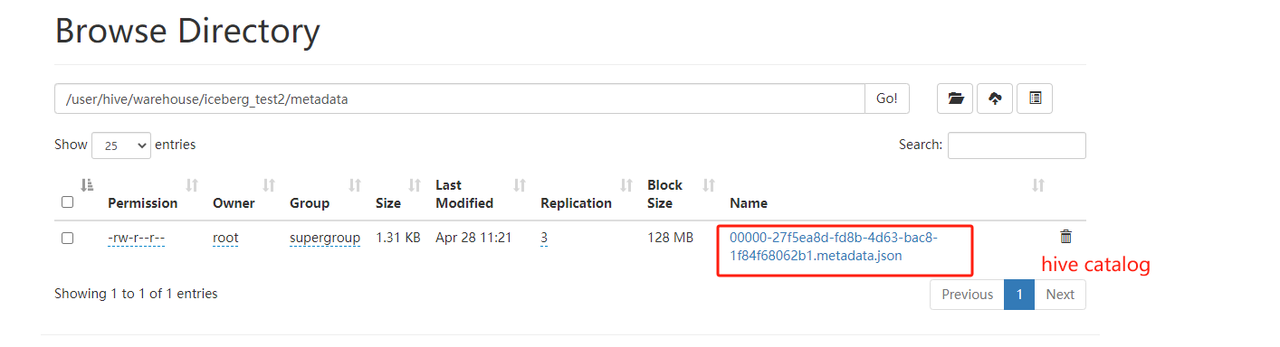
2.2.3 指定路径加载
如果HDFS中已经存在iceberg格式表,我们可以通过在Hive中创建Icerberg格式表指定对应的location路径映射数据。
CREATE EXTERNAL TABLE iceberg_test4 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://192.168.110.120:8020/warehouse/iceberg-hadoop/default/iceberg_test3'
TBLPROPERTIES ('iceberg.catalog'='location_based_table');
注意: 表iceberg_test4需要跟原表数据类型保持一致
location: location要指定到具体的表名
如果指定路径加载时创建的是内部表,删除iceberg_test4表的同时,会删除iceberg_test3表的数据(show tables;可以查到表,但是查表数据会报错:Table does not exist)。所以指定路径加载 建议创建外部表。
2.3 DDL操作
2.3.1 创建表
1)创建外部表
CREATE EXTERNAL TABLE iceberg_create1 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
-- 查看表相情
describe formatted iceberg_create1;
2)创建内部表
CREATE TABLE iceberg_create2 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
describe formatted iceberg_create2;
3)创建分区表
CREATE EXTERNAL TABLE iceberg_create3 (id int,name string)
PARTITIONED BY (age int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
describe formatted iceberg_create3;
Hive语法创建分区表,不会在HMS中创建分区(这个指的是hive分隔的分区),而是将分区数据转换为Iceberg标识分区。这种情况下不能使用Iceberg的分区转换,例如:days(timestamp),如果想要使用Iceberg格式表的分区转换标识分区,需要使用Spark或者Flink引擎创建表。
2.3.2 修改表
只支持HiveCatalog表修改表属性(字段调整,分区变化都不支持修改。hive 4支持字段调整等),Iceberg表属性和Hive表属性存储在HMS中是同步的。
ALTER TABLE iceberg_create1 SET TBLPROPERTIES('external.table.purge'='FALSE');
2.3.3 插入表
支持标准单表INSERT INTO操作
INSERT INTO iceberg_create2 VALUES (1);
INSERT INTO iceberg_create1 select * from iceberg_create2;
在HIVE 3.x中,INSERT OVERWRITE虽然能执行,但其实是追加。
2.3.4 删除表
DROP TABLE iceberg_create1;
3. Iceberg与Flink SQL集成
这里使用flink版本是 flink-1.16.0 ,Iceberg版本是 1.1.0
3.1 环境准备
3.1.1 安装 Flink
1)Flink与Iceberg的版本对应关系如下
| Flink 版本 | Iceberg 版本 |
|---|---|
| 1.11 | 0.9.0 – 0.12.1 |
| 1.12 | 0.12.0 – 0.13.1 |
| 1.13 | 0.13.0 – 1.0.0 |
| 1.14 | 0.13.0 – 1.1.0 |
| 1.15 | 0.14.0 – 1.1.0 |
| 1.16 | 1.1.0 – 1.1.0 |
2)上传并解压Flink安装包
tar -zxvf flink-1.16.0-bin-scala_2.12.tgz -C /opt/module/
3)配置环境变量
sudo vim /etc/profile.d/my_env.sh
export HADOOP_CLASSPATH=`hadoop classpath` #这样就不需要在flink lib下放hadoop相关的包
source /etc/profile.d/my_env.sh
4)拷贝iceberg的jar包到Flink的lib目录
cp /opt/software/iceberg/iceberg-flink-runtime-1.16-1.1.0.jar /opt/module/flink-1.16.0/lib
3.1.2 启动 Hadoop
3.1.3 启动 sql-client
1)修改flink-conf.yaml配置
vim /opt/module/flink-1.16.0/conf/flink-conf.yaml
classloader.check-leaked-classloader: false
taskmanager.numberOfTaskSlots: 4
state.backend: rocksdb
execution.checkpointing.interval: 30000
state.checkpoints.dir: hdfs://hadoop1:8020/ckps
state.backend.incremental: true
(2)启动Flink
/opt/module/flink-1.16.0/bin/start-cluster.sh
(3)启动Flink的sql-client
/opt/module/flink-1.16.0/bin/sql-client.sh embedded
3.2 创建和使用 Catalog
3.2.1 语法说明
CREATE CATALOG <catalog_name> WITH (
'type'='iceberg',
`<config_key>`=`<config_value>`
);
注意:
· type: 必须是iceberg。(必填)
· catalog-type: 内置了hive和hadoop两种catalog,也可以使用catalog-impl来自定义catalog。(可选)
· catalog-impl: 自定义catalog实现的全限定类名。如果未设置catalog-type,则必须设置。(可选)
· property-version: 描述属性版本的版本号。此属性可用于向后兼容,以防属性格式更改。当前属性版本为1。(可选)
· cache-enabled: 是否启用目录缓存,默认值为true。(可选)
· cache.expiration-interval-ms: 本地缓存catalog条目的时间(以毫秒为单位);负值,如-1表示没有时间限制,不允许设为0。默认值为-1。(可选)
3.2.2 Hive Catalog
1)上传hive connector到flink的lib中
cp flink-sql-connector-hive-3.1.2_2.12-1.16.0.jar /opt/module/flink-1.16.0/lib/
2)启动hive metastore服务
hive --service metastore
3)创建hive catalog
重启flink集群,重新进入sql-client
CREATE CATALOG hive_catalog WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://192.168.110.120:9083',
'clients'='5',
'property-version'='1',
'warehouse'='hdfs://192.168.110.120:8020/warehouse/iceberg-hive'
);
use catalog hive_catalog;
注意:
· uri: Hive metastore的thrift uri。(必填)
· clients:Hive metastore客户端池大小,默认为2。(可选)
· warehouse: 数仓目录。(必选)
3.2.3 Hadoop Catalog
Iceberg还支持HDFS中基于目录的catalog,可以使用’catalog-type’='hadoop’配置。
CREATE CATALOG hadoop_catalog WITH (
'type'='iceberg',
'catalog-type'='hadoop',
'warehouse'='hdfs://192.168.110.120:8020/warehouse/iceberg-hadoop',
'property-version'='1'
);
use catalog hadoop_catalog;
·warehouse:存放元数据文件和数据文件的HDFS目录。(必填)
3.2.4 配置sql-client初始化文件
vim /opt/module/flink-1.16.0/conf/sql-client-init.sql
## hive catalog
CREATE CATALOG hive_catalog WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://192.168.110.120:9083',
'clients'='5',
'property-version'='1',
'warehouse'='hdfs://192.168.110.120:8020/warehouse/iceberg-hive'
);
## hadoop catalog
CREATE CATALOG hadoop_catalog WITH (
'type'='iceberg',
'catalog-type'='hadoop',
'warehouse'='hdfs://192.168.110.120:8020/warehouse/iceberg-hadoop',
'property-version'='1'
);
## 默认使用hive_catalog(可选)
USE CATALOG hive_catalog;
后续启动sql-client时,加上 -i sql文件路径 即可完成catalog的初始化。
/opt/module/flink-1.16.0/bin/sql-client.sh embedded -i conf/sql-client-init.sql
3.3 DDL 语句
3.3.1 创建数据库
CREATE DATABASE iceberg_db;
USE iceberg_db;
3.3.2 创建表
CREATE TABLE `hive_catalog`.`default`.`sample` (
id BIGINT COMMENT 'unique id',
data STRING
);
建表命令现在支持最常用的flink建表语法,包括:
·PARTITION BY (column1, column2, …):配置分区,apache flink还不支持隐藏分区。
·COMMENT ‘table document’:指定表的备注
·WITH (‘key’=‘value’, …):设置表属性
目前,不支持计算列、watermark(支持主键)。
1)创建分区表
CREATE TABLE `hive_catalog`.`default`.`sample` (
id BIGINT COMMENT 'unique id',
data STRING
) PARTITIONED BY (data);
Apache Iceberg支持隐藏分区,但Apache flink不支持在列上通过函数进行分区,现在无法在flink DDL中支持隐藏分区。
2)使用LIKE语法建表
LIKE语法用于创建一个与另一个表具有相同schema、分区和属性的表。
CREATE TABLE `hive_catalog`.`default`.`sample` (
id BIGINT COMMENT 'unique id',
data STRING
);
CREATE TABLE `hive_catalog`.`default`.`sample_like` LIKE `hive_catalog`.`default`.`sample`;
3.3.3 修改表
目前只支持修改表属性,表名
1)修改表属性
ALTER TABLE `hive_catalog`.`default`.`sample` SET ('write.format.default'='avro');
2)修改表名
ALTER TABLE `hive_catalog`.`default`.`sample` RENAME TO `hive_catalog`.`default`.`new_sample`;
3.3.4 删除表
DROP TABLE `hive_catalog`.`default`.`sample`;
3.4 插入语句
3.4.1 INSERT INTO
INSERT INTO `hive_catalog`.`default`.`sample` VALUES (1, 'a');
INSERT INTO `hive_catalog`.`default`.`sample` SELECT id, data from sample2;
3.4.2 INSERT OVERWRITE
仅支持Flink的Batch模式
SET execution.runtime-mode = batch;
INSERT OVERWRITE sample VALUES (1, 'a');
INSERT OVERWRITE `hive_catalog`.`default`.`sample` PARTITION(data='a') SELECT 6;
3.4.3 UPSERT
当将数据写入v2表格式时,Iceberg支持基于主键的UPSERT。有两种方法可以启用upsert。
1)建表时指定
CREATE TABLE `hive_catalog`.`iceberg_db`.`sample` (
`id` INT UNIQUE COMMENT 'unique id',
`data` STRING NOT NULL,
PRIMARY KEY(`id`) NOT ENFORCED
) with (
'format-version'='2',
'write.upsert.enabled'='true'
);
format-version : 格式版本,默认值是1。1 表示只支持追加;2表示upsert
2)插入时指定,使用sql hint指定
INSERT INTO tableName /*+ OPTIONS('upsert-enabled'='true') */
...
插入的表,format-version需要为2。
OVERWRITE和UPSERT不能同时设置。在UPSERT模式下,如果对表进行分区,则分区字段必须也是主键。
3)读取Kafka流,upsert插入到iceberg表中
create table default_catalog.default_database.kafka(
id int,
data string
) with (
'connector' = 'kafka'
,'topic' = 'test111'
,'properties.zookeeper.connect' = 'hadoop1:2181'
,'properties.bootstrap.servers' = 'hadoop1:9092'
,'format' = 'json'
,'properties.group.id'='iceberg'
,'scan.startup.mode'='earliest-offset'
);
scan.startup.mode:扫描模式
INSERT INTO hive_catalog.test1.sample5 SELECT * FROM default_catalog.default_database.kafka;
3.5 查询语句
Iceberg支持Flink的流式和批量读取。
3.5.1 Batch模式
SET execution.runtime-mode = batch;
select * from sample;
3.5.2 Streaming模式
SET execution.runtime-mode = streaming;
SET table.dynamic-table-options.enabled=true;
SET sql-client.execution.result-mode=tableau;
1)从当前快照读取所有记录,然后从该快照读取增量数据
SELECT * FROM sample5 /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/ ;
2)读取指定快照id(不包含)后的增量数据
SELECT * FROM sample /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s', 'start-snapshot-id'='3821550127947089987')*/ ;
·monitor-interval: 连续监控新提交数据文件的时间间隔(默认为10s)。
·start-snapshot-id: 流作业开始的快照id。
注意: 如果是无界数据流式upsert进iceberg表(读kafka,upsert进iceberg表),那么再去流读iceberg表会存在读不出数据的问题。如果无界数据流式append进iceberg表(读kafka,append进iceberg表),那么流读该iceberg表可以正常看到结果。
3.6 与Flink集成的不足
| 支持的特性 | Flink | 备注 |
|---|---|---|
| SQL create catalog | √ | |
| SQL create database | √ | |
| SQL create table | √ | |
| SQL create table like | √ | |
| SQL alter table | √ | 只支持修改表属性,不支持更改列和分区 |
| SQL drop_table | √ | |
| SQL select | √ | 支持流式和批处理模式 |
| SQL insert into | √ | 支持流式和批处理模式 |
| SQL insert overwrite | √ | |
| DataStream read | √ | |
| DataStream append | √ | |
| DataStream overwrite | √ | |
| Metadata tables | 支持Java API,不支持Flink SQL | |
| Rewrite files action | √ |
·不支持创建隐藏分区的Iceberg表。
·不支持创建带有计算列的Iceberg表。
·不支持创建带watermark的Iceberg表。
·不支持添加列,删除列,重命名列,更改列。
·Iceberg目前不支持Flink SQL 查询表的元数据信息,需要使用Java API 实现。
4. Iceberg与Flink DataStream 集成
4.1 环境准备
4.1.1 配置pom文件
新建Maven工程,pom文件配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.iceberg.demo</groupId>
<artifactId>flink-iceberg-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.16.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope> <!–不会打包到依赖中,只参与编译,不参与运行 –>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<!--idea运行时也有webui-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
<!-- <scope>provided</scope>-->
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.iceberg/iceberg-flink-runtime-1.16 -->
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-flink-runtime-1.16</artifactId>
<version>1.1.0</version>
</dependency>
</dependencies>
</project>
4.1.2 配置log4j
resources目录下新建log4j.properties。
log4j.rootLogger=error,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
4.2 读取数据
4.2.1 常规Source写法
1)Batch方式
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.iceberg.flink.TableLoader;
import org.apache.iceberg.flink.source.FlinkSource;
public class ReadDemo {
public static void main(String[] args) throws Exception {
//1.创建flink 环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://192.168.110.120:8020/warehouse/iceberg-hadoop/iceberg_db/sample");
DataStream<RowData> batch = FlinkSource.forRowData()
.env(env)
.tableLoader(tableLoader)
.streaming(false) // false : batch方式读取数据; true:streaming方式读取数据
//.asOfTimestamp()
//.startSnapshotId()
.build();
batch.map(r -> Tuple2.of(r.getInt(0),r.getString(1).toString()))
.returns(Types.TUPLE(Types.INT,Types.STRING))
.print();
env.execute("Test Iceberg Read");
}
}
2)Streaming方式
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://hadoop1:8020/warehouse/spark-iceberg/default/a");
DataStream<RowData> stream = FlinkSource.forRowData()
.env(env)
.tableLoader(tableLoader)
.streaming(true)
.startSnapshotId(3821550127947089987L)
.build();
stream.map(r -> Tuple2.of(r.getLong(0),r.getLong(1) ))
.returns(Types.TUPLE(Types.LONG,Types.LONG))
.print();
env.execute("Test Iceberg Read");
4.2.2 FLIP-27 Source写法
1)Batch方式
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://hadoop1:8020/warehouse/spark-iceberg/default/a");
IcebergSource<RowData> source1 = IcebergSource.forRowData()
.tableLoader(tableLoader)
.assignerFactory(new SimpleSplitAssignerFactory())
.build();
DataStream<RowData> batch = env.fromSource(
Source1,
WatermarkStrategy.noWatermarks(),
"My Iceberg Source",
TypeInformation.of(RowData.class));
batch.map(r -> Tuple2.of(r.getLong(0), r.getLong(1)))
.returns(Types.TUPLE(Types.LONG, Types.LONG))
.print();
env.execute("Test Iceberg Read");
2)Streaming方式
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://hadoop1:8020/warehouse/spark-iceberg/default/a");
IcebergSource source2 = IcebergSource.forRowData()
.tableLoader(tableLoader)
.assignerFactory(new SimpleSplitAssignerFactory())
.streaming(true)
.streamingStartingStrategy(StreamingStartingStrategy.INCREMENTAL_FROM_LATEST_SNAPSHOT)
.monitorInterval(Duration.ofSeconds(60))
.build();
DataStream<RowData> stream = env.fromSource(
Source2,
WatermarkStrategy.noWatermarks(),
"My Iceberg Source",
TypeInformation.of(RowData.class));
stream.map(r -> Tuple2.of(r.getLong(0), r.getLong(1)))
.returns(Types.TUPLE(Types.LONG, Types.LONG))
.print();
env.execute("Test Iceberg Read");