为了更快的定位您的问题,请提供以下信息,谢谢
【详述】关于starrocks过滤条件中携带函数,bitmap索引失效
【背景】
建表SQL:
CREATE TABLE test
(
user_new_id varchar(65533) NOT NULL COMMENT “id”,
pt varchar(65533) NOT NULL COMMENT “full_partition”,
sr_auto_uuid bigint(20) NOT NULL AUTO_INCREMENT COMMENT “”,
capital_name varchar(65533) NULL COMMENT “部名称”,
user_guid varchar(65533) NULL COMMENT “户id”,
data_date varchar(65533) NULL COMMENT “筛日期”,
INDEX idx_data_date (data_date) USING BITMAP
) ENGINE = OLAP
PRIMARY KEY(user_new_id, pt, sr_auto_uuid)
COMMENT “测试数据”
PARTITION BY (pt)
DISTRIBUTED BY HASH(user_new_id) BUCKETS 1
PROPERTIES (
“replication_num” = “3”,
“bloom_filter_columns” = “product_name”,
“in_memory” = “false”,
“enable_persistent_index” = “false”,
“replicated_storage” = “true”,
“compression” = “LZ4”
);
data_date数据为:"2024-07-02"类型时间数据
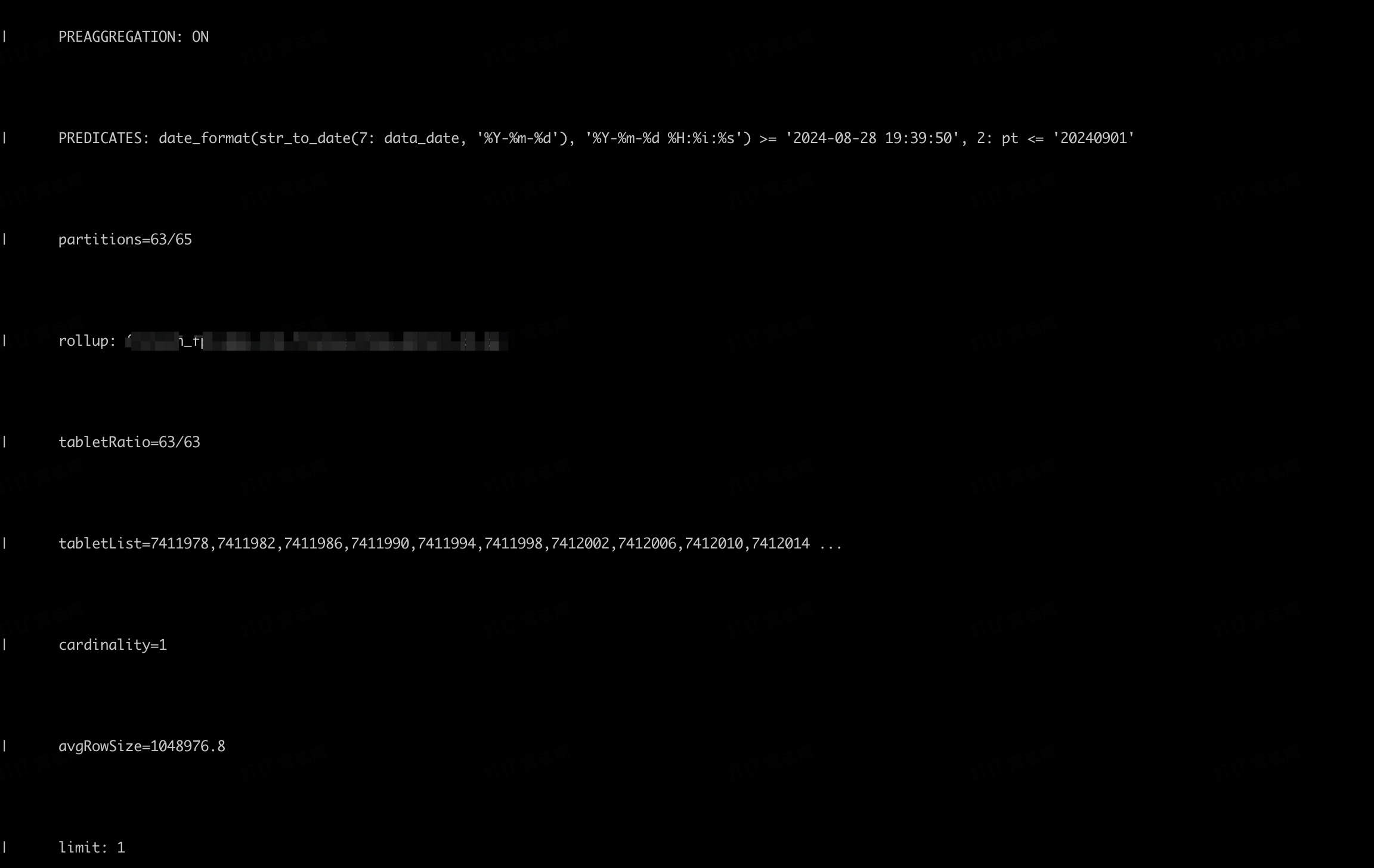
1.使用select count(1) from test where data_date=‘2024-08-27’;可以命中bitmap索引
详细见query_profile:

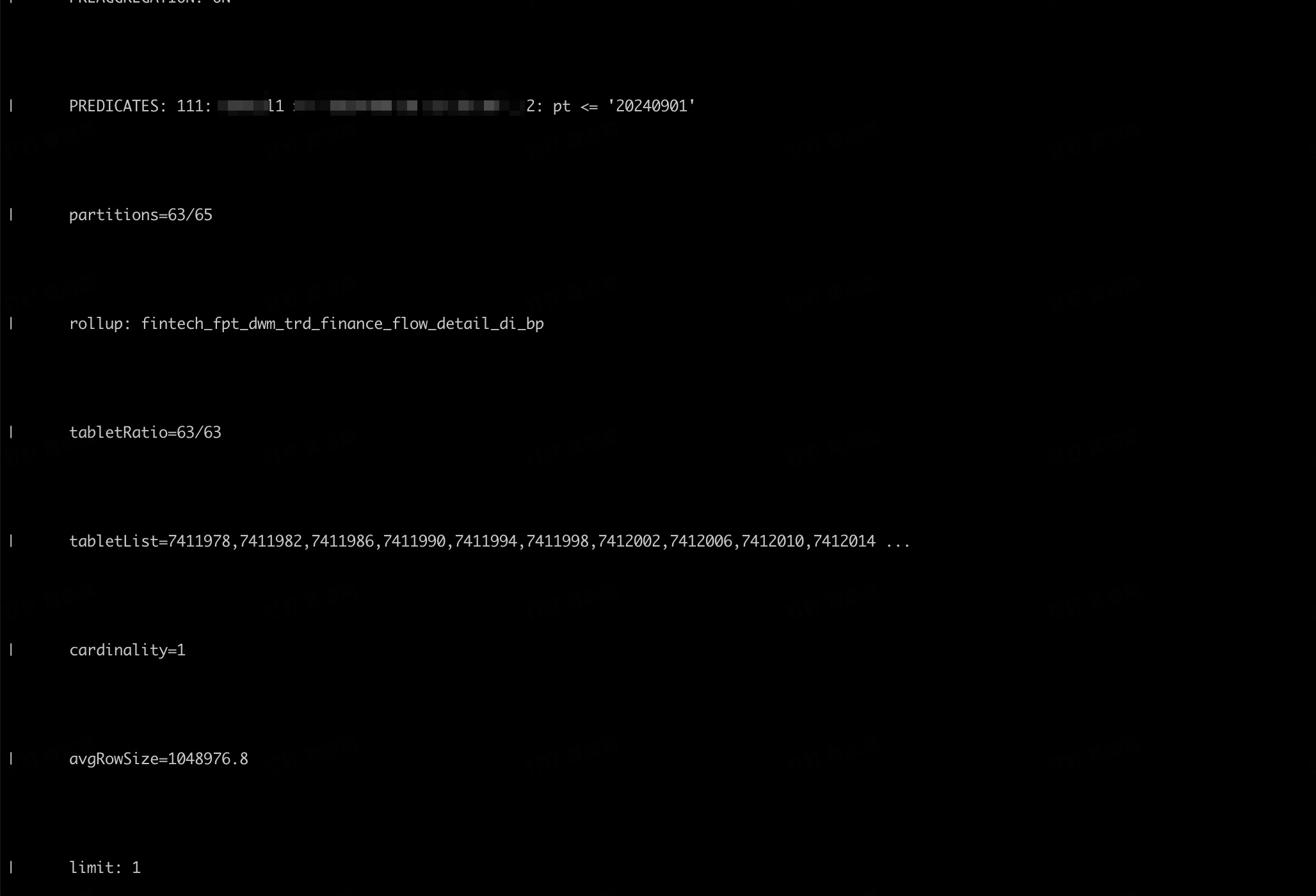
2.使用select count(1) from test where str_to_date(data_date, ‘%Y-%m-%d’)=‘2024-08-27’,无法命中bitmap索引
详细见:

因为我们场景中在过滤数据中经常会对字段做函数处理,如果索引无法针对函数生效,那我们每次进行scan时,会相对的耗费时间,像这类场景,我们应该如何提升scan的效率呢
【业务影响】查询性能慢
【是否存算分离】 否
【StarRocks版本】3.2.8
【集群规模】例如:3fe+10be
【机器信息】CPU虚拟核/内存/网卡,例如:48C/64G/万兆