为了更快的定位您的问题,请提供以下信息,谢谢
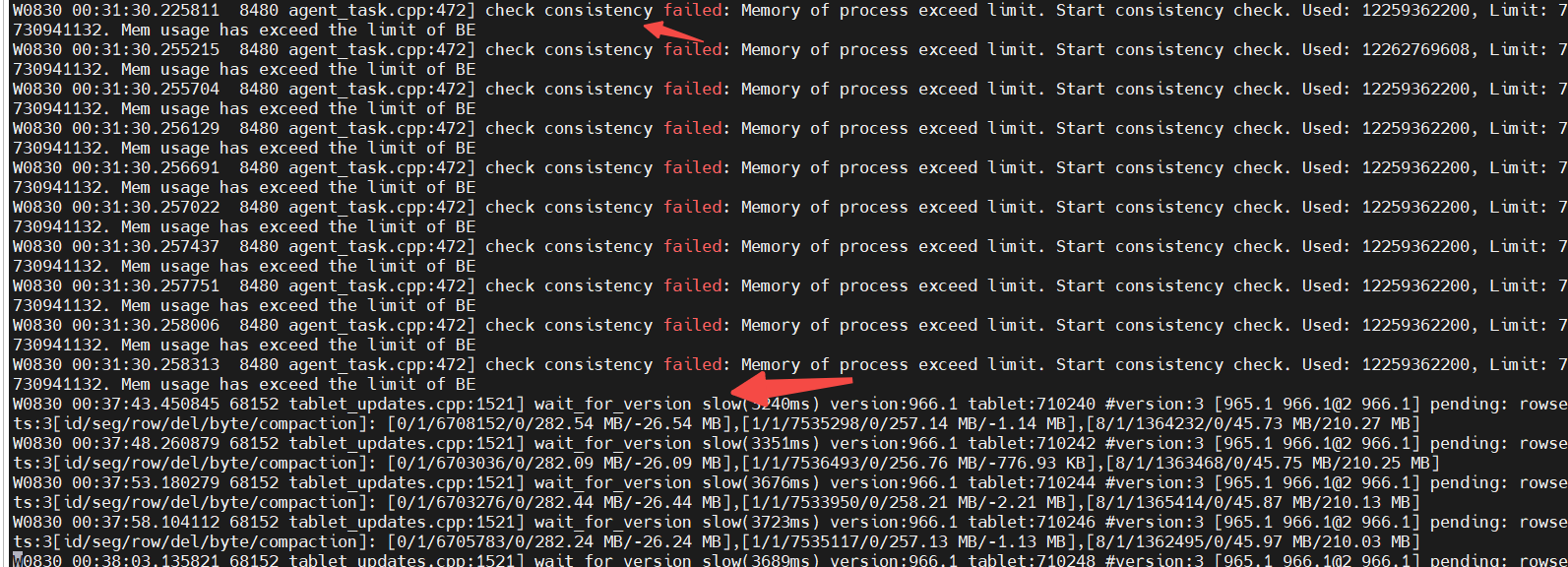
【详述】flink-sql实时写入starrocks主键表中,每天凌晨报错be内存不足
【背景】
【业务影响】
【是否存算分离】无
【StarRocks版本】3.15
【集群规模】3be+3fe混合部署
【机器信息】16c64g
【联系方式】vx: sun7891011
flink-jobmanager报错:
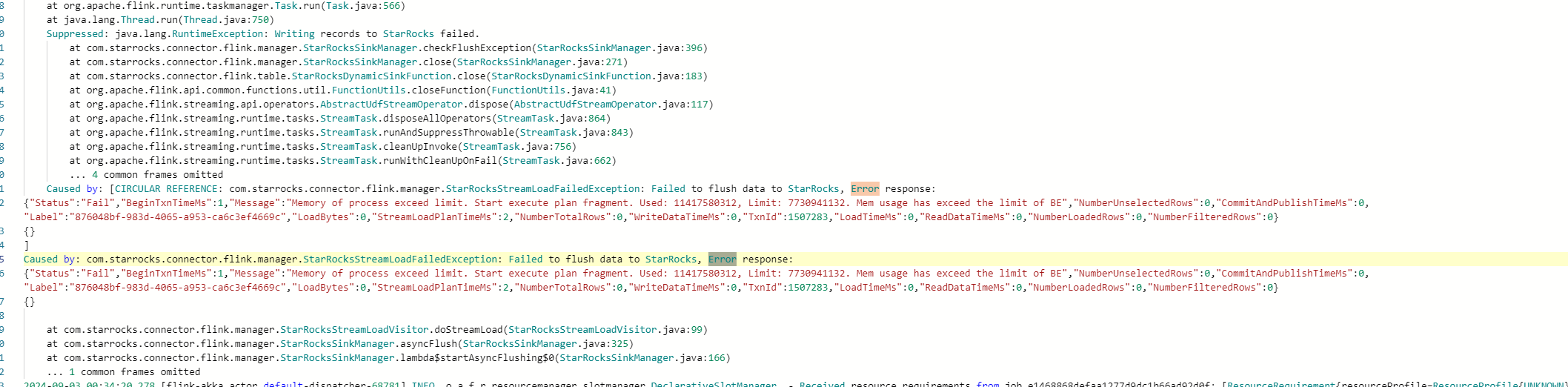
sql如下:
CREATE TABLE ods_base_trade_trade_order (
action string,
timestamp STRING ,
schema STRING ,
table STRING ,
columns ARRAY<ROW<name STRING,type STRING,value STRING>>
) WITH (
‘connector’ = ‘kafka’, --kafka连接器
‘topic’ = ‘ods_base_trade’,
‘properties.bootstrap.servers’ = ‘cdh01:9092’,
‘properties.group.id’ = ‘group0820’,
‘scan.startup.mode’ = ‘earliest-offset’,
‘format’ = ‘json’, --指定格式
‘json.ignore-parse-errors’ = ‘true’
);
CREATE TABLE rt_base_trade_trade_order (
id varchar not null ,
actions varchar(10),
loaded_time timestamp,
PRIMARY KEY (id) NOT ENFORCED
)WITH (
‘jdbc-url’ = ‘jdbc:mysql://xxxx:9030’,
‘connector’ = ‘starrocks’,
‘database-name’ = ‘xxx’,
‘table-name’ = ‘xxx’,
‘password’ = ‘xxx23’,
‘load-url’ = ‘xxx:8036’,
‘username’ = ‘xx’,
‘sink.properties.format’ = ‘json’,
‘sink.properties.strip_outer_array’ = ‘true’,
‘sink.max-retries’ = ‘10’,
‘sink.buffer-flush.interval-ms’ = ‘3000’,
‘sink.parallelism’ = ‘5’
);