为了更快的定位您的问题,请提供以下信息,谢谢
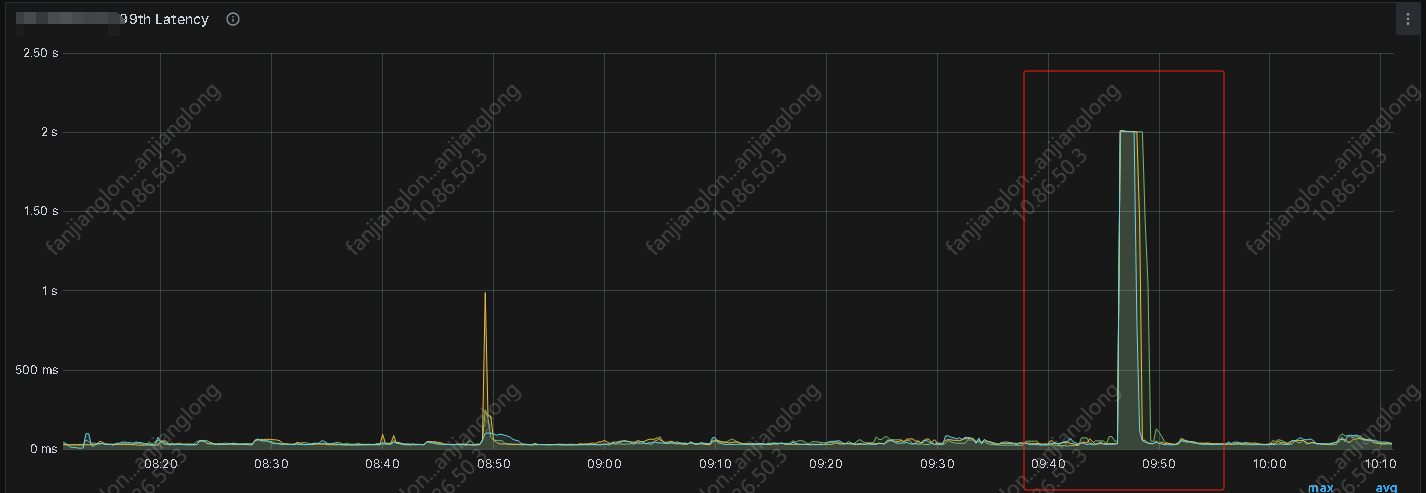
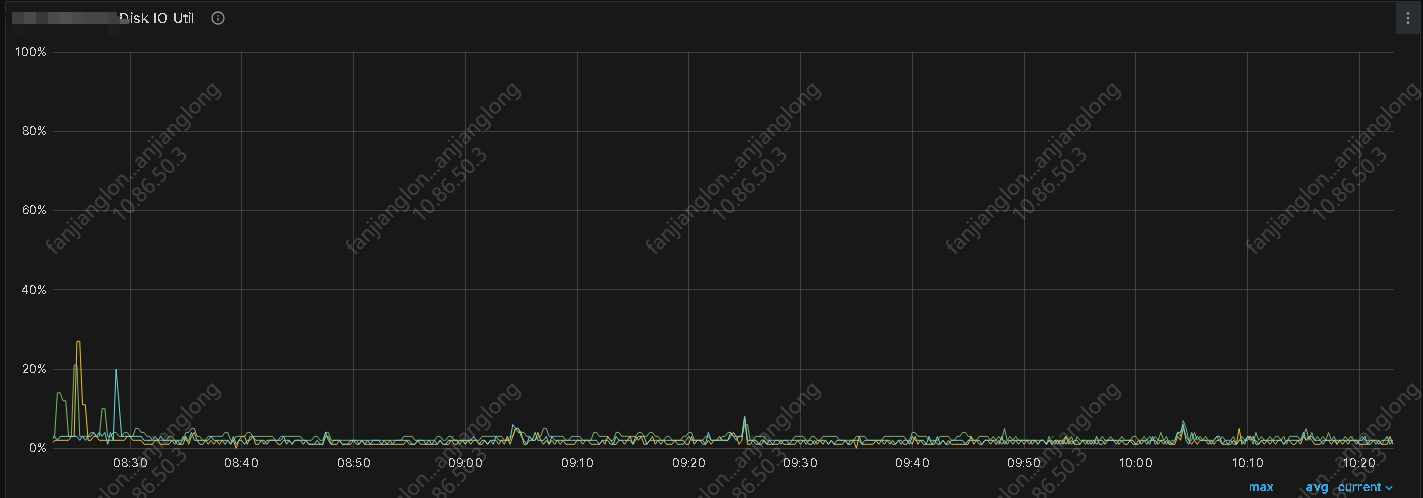
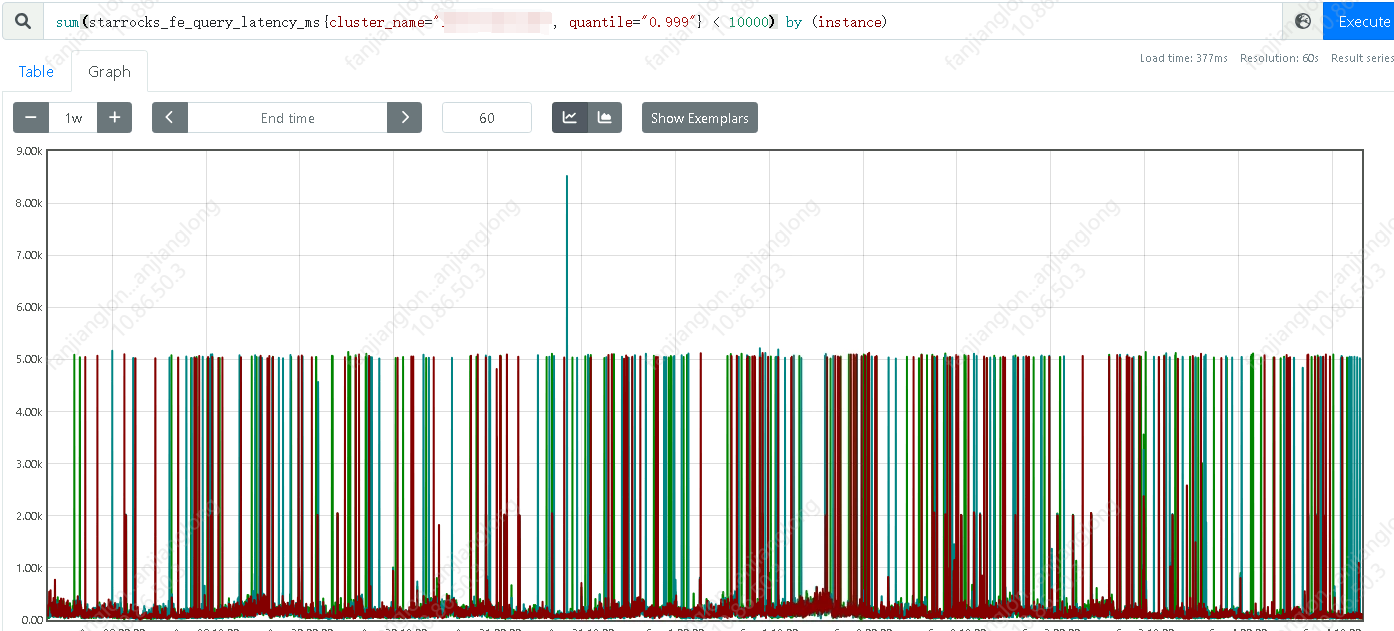
【详述】平时连接查询均在毫秒级别,但不定时出现耗时达到秒级别,影响业务正常查询,但从监控看没看到有什么其它大查询影响,查询日志只看到BE.warn在毛刺的时间段出现大量的 (starrocks-mysql-nio-pool-22611|174202) [Coordinator.endProfile():2602] failed to get profile within 2 seconds 日志,除此外无其它警告或报错日志
【背景】正常查询
【业务影响】
【是否存算分离】否
【StarRocks版本】例如:2.5.21 dc2bcdb
【集群规模】例如:3fe(1 follower+2observer)+3be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:32C/128G/万兆
【联系方式】为了在解决问题过程中能及时联系到您获取一些日志信息,请补充下您的联系方式,例如:社区群4-小李或者邮箱,谢谢
【附件】
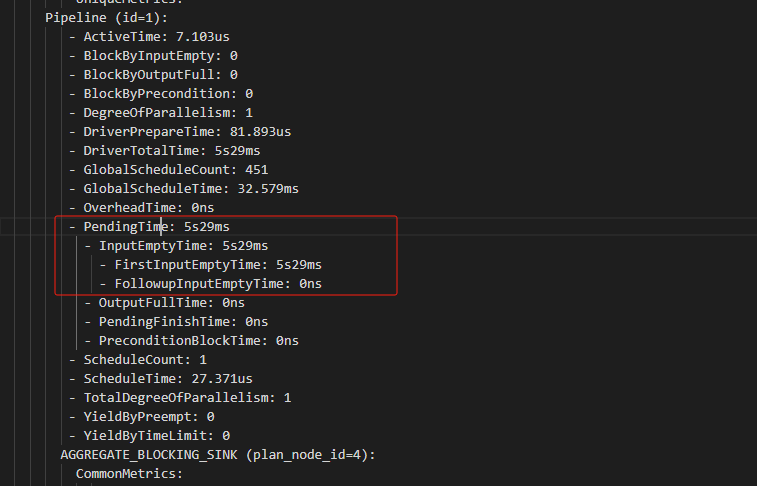
- Profile信息,如何获取profile
由于profile时间过短,而毛刺观测延后,导致无法获取到实际耗时较高的profile - 并行度:show variables like ‘%parallel_fragment_exec_instance_num%’;
- parallel_fragment_exec_instance_num 1
show variables like ‘%pipeline_dop%’; - pipeline_dop 0
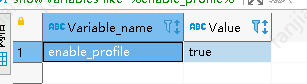
- pipeline是否开启:show variables like ‘%pipeline%’;

- 执行计划:explain costs + sql
日常耗时:

- pipeline是否开启:show variables like ‘%pipeline%’;
PLAN FRAGMENT 0
OUTPUT EXPRS:23: sum
PARTITION: UNPARTITIONED
RESULT SINK
4:AGGREGATE (merge finalize)
| output: sum(23: sum)
| group by:
|
3:EXCHANGE
PLAN FRAGMENT 1
OUTPUT EXPRS:
PARTITION: RANDOM
STREAM DATA SINK
EXCHANGE ID: 03
UNPARTITIONED
2:AGGREGATE (update serialize)
| output: sum(20: cash)
| group by:
|
1:Project
| <slot 20> : 20: cash
|
0:OlapScanNode
TABLE: t_app_pub_user_payment_ri
PREAGGREGATION: OFF. Reason: Aggregate Operator not match: SUM <--> REPLACE
PREDICATES: 1: gameid = 291, 3: recharge_user = '9_89185540', 2: logtime >= '2024-08-29 18:47:54', 2: logtime <= '2024-09-12 04:00:00'
partitions=2/63
rollup: t_app_pub_user_payment_ri
tabletRatio=30/30
tabletList=1907671,1907675,1907679,1907683,1907687,1907691,1907695,1907699,1907703,1907707 ...
cardinality=1
avgRowSize=30.730707
numNodes=0
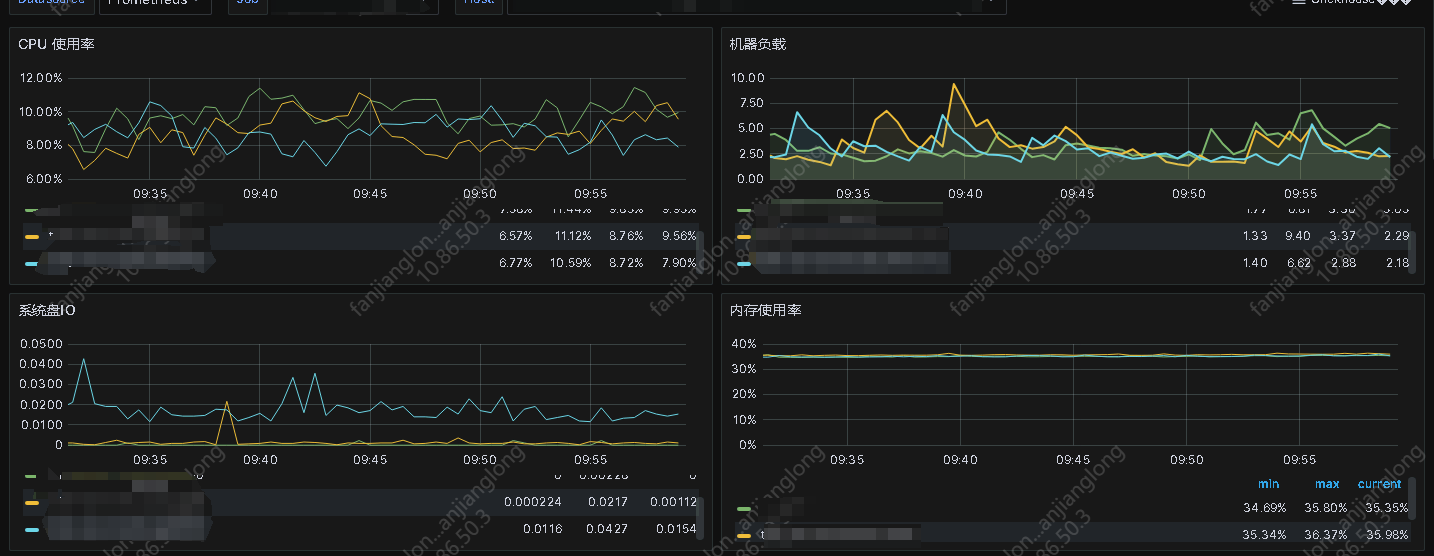
- be节点cpu和内存使用率截图