StarRocks升级文档(存算一体):
前言:
1.Starrocks升级,整体而言比较平滑,支持不停集群滚动升级.由本次经验铺垫,建议后续升级尽量在夜间进行,如此不影响业务方使用.
2.如果要大版本升级(3.x(大版本).xxx),比如从3.1.13升级到3.2,升级路线为:3.1.13--->3.1.max--->3.2目标版本.
不建议跨多个大版本升级,容易导致很多不确定因素.
3.Starrocks升级要注重:
1.停掉上游同步程序.
2.停掉物化视图.(unactive)
3.升级时,重点关注 show proc '/statistic'; 中unhealthyTablet是否为0.
4.show backends;show frontends; 查看升级版本是否出现了版本更替(例如be原来3.1.13,升级后 show backends中看到是3.1.14)
5.清单方式列举停掉的调度流.
6.注意先BE,确认每个节点都没有unhealthy tablet,再升级FE(fllower-->leader)
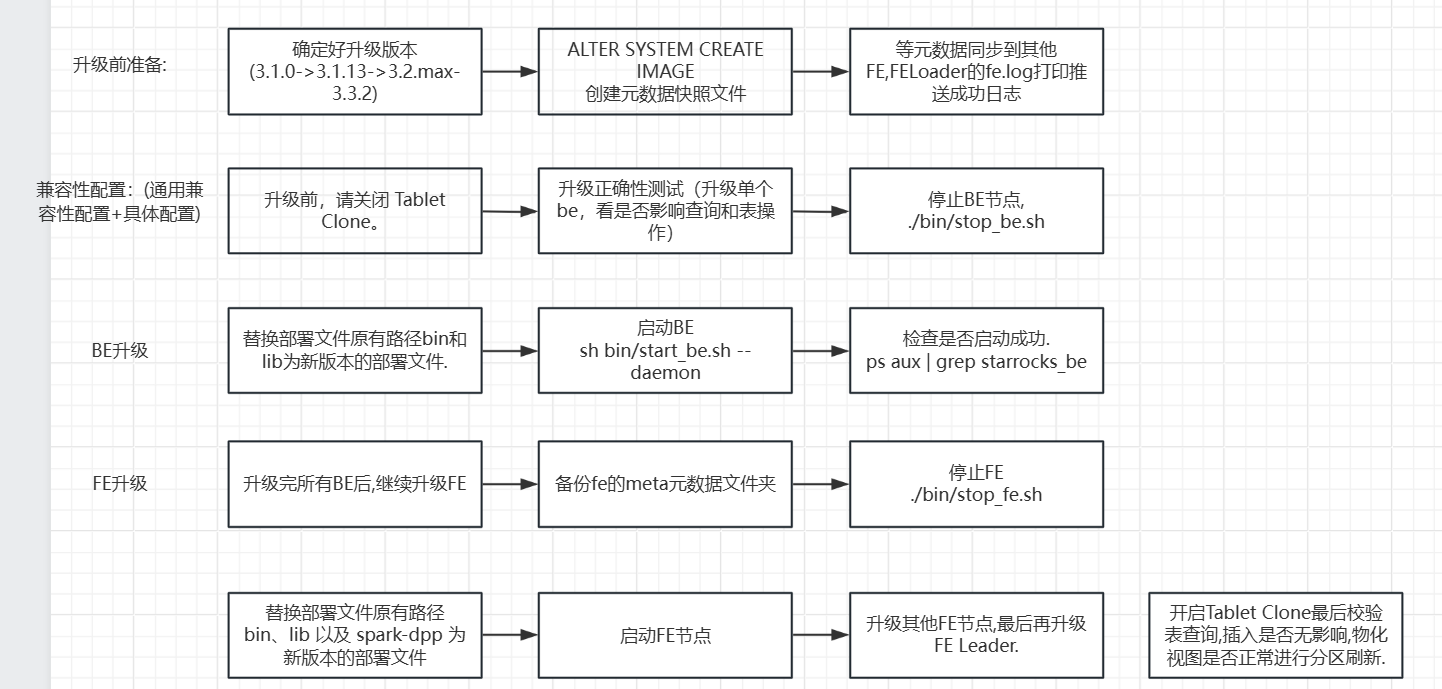
升级流程图:
![image-20240830143911116]()
升级步骤:
step1:备份元数据快照
1.在编译器执行 ALTER SYSTEM CREATE IMAGE 创建新的元数据快照文件.
2.要等元数据同步到其他FE.
通过Leader FE节点日志文件fe.log确认元数据快照文件是否推送完成.
如果日志打印: “push image.xxx from subdir [] to other nodes. totally xx nodes, push succeeded xx nodes”
则表示快照文件推送成功.
step2: 关闭Tablet Clone:
ADMIN SET FRONTEND CONFIG ("tablet_sched_max_scheduling_tablets" = "0");
ADMIN SET FRONTEND CONFIG ("tablet_sched_max_balancing_tablets" = "0");
ADMIN SET FRONTEND CONFIG ("disable_balance"="true");
ADMIN SET FRONTEND CONFIG ("disable_colocate_balance"="true");
step3: 升级BE节点:
1.进入BE节点工作路径,停止该节点:
# 将<be_dir> 替换为 BE 节点的部署目录.
cd <be_dir>/be
./bin/stop_be.sh
2.替换部署文件原有路径 bin 和 lib 为新版本的部署文件。
mv lib lib.bak
mv bin bin.bak
cp -r /tmp/StarRocks-x.x.x/be/lib .
cp -r /tmp/StarRocks-x.x.x/be/bin .
3.启动BE
sh bin/start_be.sh --daemon
4.查看BE是否启动成功:
ps aux | grep starrocks_be
在mysql客户端:
mysql -h 172.16.0.170 -P 9030 -u root -p'xxx'
show backends\G
==> 1.Version为升级后版本.
==> 2.Alive为true.
==> 3.show proc '/statistic'; (需要关注两个指标:UnhealthyTabletNum和InconsistentTabletNum 都为0才可以升级下一个节点.)
异常Tbalet修复:
step1:
show proc '/statistic' 找到是否存在不健康的tabelt.
step2:
SHOW PROC '/statistic/15004'
step3:
如果出现UnhealthyTabletNum 一直不为0.
在确定表为3副本的情况下,手动设置副本状态为Bad,然后:
1.ADMIN SET REPLICA STATUS PROPERTIES ("key" = "value", ...);
ADMIN SET REPLICA STATUS PROPERTIES("tablet_id" = "17156", "backend_id" = "10004", "status" = "bad");
2.ADMIN REPAIR TABLE table_name[ PARTITION (p1,...)]
最后要达到的效果是: UnhealthyTabletNum 必须为0.
升级异常后回滚:
如果升级后BE立刻出现问题,直接在bin中停止当前BE进程,将当前bin和lib重命名为bin.new和lib.new,再将bin.bak和lib.bak改为bin和lib,重新执行bin中的启动脚本可完成回滚.
升级FE步骤:(在升级所有BE后,升级fe follower节点,最后升级Leader节点)
先备份元数据,然后再操作FE.
cp -r /opt/module/meta /opt/module/meta2203051617(可以带本次操作时间,方便排查)=
1.停止FE节点:
# 将 <fe_dir> 替换为FE节点的部署目录:
cd <fe_dir>/fe
./bin/stop_fe.sh
2.替换文件
mv lib lib.bak
mv bin bin.bak
mv spark-dpp spark-dpp.bak
cp -r /tmp/StarRocks-x.x.x/fe/lib .
cp -r /tmp/StarRocks-x.x.x/fe/bin .
cp -r /tmp/StarRocks-x.x.x/fe/spark-dpp .
3.启动新的FE进程:
./bin/start_fe.sh --daemon
4.show frontends; 查看alive状态和fe版本号是否改变.并且show proc '/statistic'; 查看是否unhealthy tablet是否为0
假设FE出现异常,就需要立刻停止新版本FE进程,重命名新版本的bin和lib为bin.new和lib.new,将旧版本的bin.bak和lib.bak恢复命 名为bin和lib.然后,删除新版本的元数据目录meta,然后将本分的元数据拷贝一份命名为meta,最后使用老版本的FE程序文件启动.
step6:
1.在3FE fllower情况下,假设一个FE出现了无法解决的问题,一种应急的做法是立刻停止这个FE进程,清空其元数据目录meta,然后将这个FE视为新实例,指定 --helper 再次添加到新集群.
2.在升级3 Follower集群,升级前FE会做切主,不需要关注.连接SR客户端可以随意指定FE的ip进行查询或导入.
升级后:
查看FE leader 的 fe.log日志,看是否有异常error日志,如果没有,本次基本升级成功.
1.校验是否可以正常查询,聚合,join.(读正常)
2.启动datax同步脚本,看是否能正常同步数据.(写正常)
升级失败回滚:
step1.每一步都会先使用一个节点升级,一旦出现问题,可以按照之前的回滚操作进行回滚.(单点回滚)
step2.如果集群升级后,有功能异常.(升级前正常的业务系统升级后无法正常运行.)如果不能快速定位就得立刻回滚.(集群回滚)
回滚顺序:
FE Leader---> FE Follower ---> FE Observer ---> Broker.(和升级顺序完全相反)
FE元数据备份:
FE回滚前,需要备份一份元数据.
回滚版本:
一般正常升级,就能正常回滚.