
原文 https://mp.weixin.qq.com/s/aaYnuRSSwVPLvuzUhfr6gA
本文主要分享基于Kerberos认证的StarRocks Hive Catalog最佳实践。本文是基于订单的一个场景展开。
基础环境
| 组件 | 版本 |
|---|---|
| Kerberos | 1.15.1 |
| Zookeeper | 3.5.7 |
| HDFS | 3.3.4 |
| Hive | 3.1.2 |
| StarRocks | 3.3.0 |
| 节点 | 服务 | 机器规格 |
|---|---|---|
| cs01.starrocks.com | StarRocks-BE Zookeeper DataNode JournalNode NameNode |
8C32G 2T 高效云盘 |
| cs02.starrocks.com | StarRocks-FE StarRocks-BE Zookeeper DataNode JournalNode NameNode HiveServer HiveMetaStore |
8C64G 2T 高效云盘 |
| cs03.starrocks.com | StarRocks-BE Zookeeper DataNode JournalNode NameNode |
8C64G 1T 高效云盘 |
数据模型
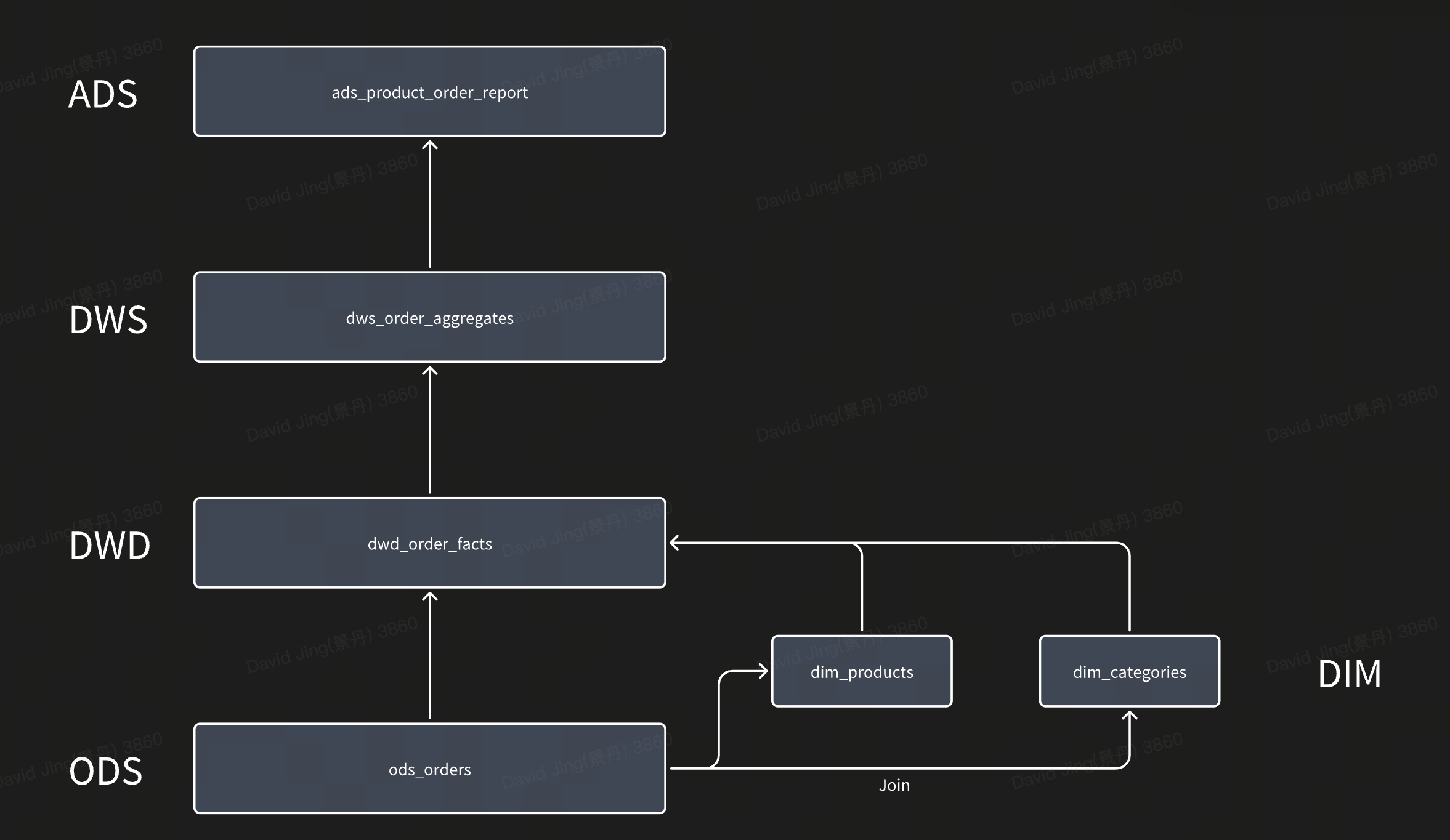
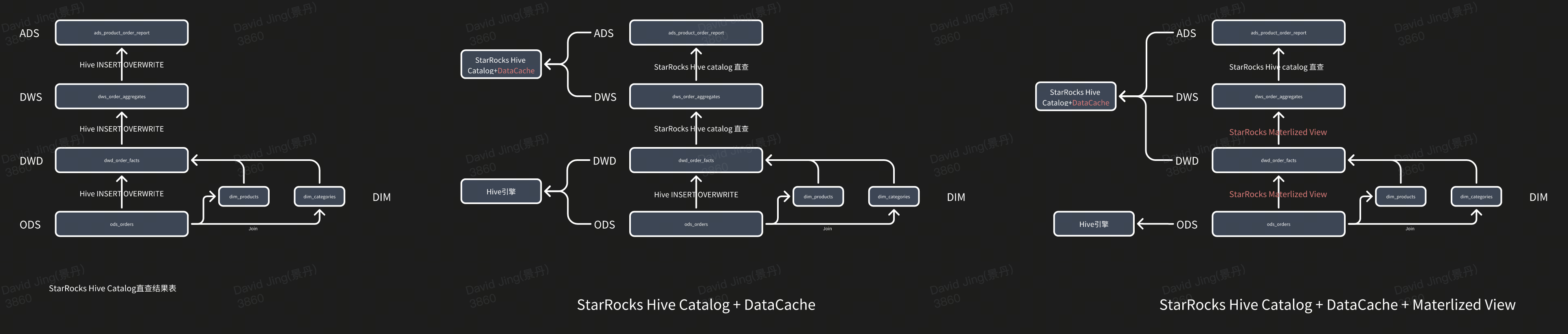
技术架构演进
- StarRocks Hive Catalog直接查结果集
- 所有ETL都是在Hive中完成,StarRocks利用Hive Catalog查询DWD、DWS和ADS的结果集
- 利用StarRocks Hive Catalog + datacache现查
- 只有ODS和DWD是在Hive中完成,后续DWS和ADS都是利用StarRocks的Hive Catalog现查(现计算)
- 异步物化视图加速
- 只有ODS在Hive侧,DWD和DWS都是利用StarRocks异步物化视图构建,ADS直
最佳实践
1. Hive建表
create database orders;
--ODS
--用于导入本地生成的测试数据过渡用的
CREATE EXTERNAL TABLE IF NOT EXISTS ods_orders_text(
order_id STRING,
user_id STRING,
order_time STRING,
product_id STRING,
quantity INT,
price DECIMAL(10, 2),
order_status STRING
)
COMMENT '订单操作数据存储表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
CREATE TABLE IF NOT EXISTS ods_orders (
order_id INT,
user_id INT,
order_time STRING,
product_id INT,
quantity INT,
price DOUBLE,
order_status STRING
)
COMMENT '订单操作数据存储表'
PARTITIONED BY (order_date STRING)
STORED AS PARQUET;
CREATE TABLE IF NOT EXISTS dim_products (
product_id INT,
product_name STRING,
category_id INT,
price DECIMAL(10, 2),
product_description STRING
)
COMMENT '产品维度表'
STORED AS PARQUET;
CREATE TABLE IF NOT EXISTS dim_categories (
category_id INT,
category_name STRING,
category_description STRING
)
COMMENT '分类维度表'
STORED AS PARQUET;
--DWD
CREATE TABLE IF NOT EXISTS dwd_order_facts (
order_id STRING,
user_id STRING,
order_time STRING,
product_id STRING,
quantity INT,
price DECIMAL(10, 2),
order_status STRING,
product_name STRING,
category_id STRING,
category_name STRING
)
COMMENT '订单事实表'
PARTITIONED BY (order_date DATE)
STORED AS PARQUET;
2. 数据构造
构造维表数据
#用于生成随机数
CREATE TABLE aux_order_data (seq_num INT);
#!/usr/bin/env python3
with open('aux_order_data.txt', 'w') as f:
for i in range(1, 10000001):
f.write("{}\n".format(i))
LOAD DATA LOCAL INPATH '/home/disk1/sr/aux_order_data.txt' INTO TABLE aux_order_data;
INSERT INTO dim_products
SELECT
floor(RAND() * 10000) + 1 AS product_id,
CONCAT('产品名称', floor(RAND() * 10000) + 1) AS product_name,
floor(RAND() * 1000) + 1 AS category_id,
ROUND(100 + RAND() * 5000, 2) AS price,
CONCAT('产品描述', floor(RAND() * 100)) AS product_description
FROM aux_order_data a
CROSS JOIN aux_order_data b
LIMIT 10000;
INSERT INTO dim_categories
SELECT
floor(RAND() * 1000) + 1 AS category_id,
CONCAT('分类名称', floor(RAND() * 1000) + 1) AS category_name,
CONCAT('分类描述', floor(RAND() * 100)) AS category_description
FROM aux_order_data a
CROSS JOIN aux_order_data b
LIMIT 1000;
构造ODS数据
分别构造2024年8月3号到8月5号的数
#!/usr/bin/env python3
import random
import time
def generate_order_data(num_records):
with open('ods_orders.txt', 'w') as f:
for i in range(1, num_records + 1):
order_id = i
user_id = random.randint(1, 1000)
order_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(random.randint(1722614400, 1722700800))) #替换开始和结束时间戳分别为8月3、4、5号
product_id = random.randint(1, 10000)
quantity = random.randint(1, 10)
price = round(random.uniform(10, 1000), 2)
order_status = '已完成' if random.random() < 0.9 else '已取消'
f.write(f"{order_id},{user_id},{order_time},{product_id},{quantity},{price},{order_status}\n")
generate_order_data(10000000)
LOAD DATA LOCAL INPATH '/home/disk1/sr/ods_orders.txt' INTO TABLE ods_orders_text;
insert
overwrite table ods_orders PARTITION (order_date)
select
order_id,
user_id,
order_time,
product_id,
quantity,
price,
order_status,
substr(order_time, 1, 10) as order_date
from
ods_orders_text;
构造DWD数据
INSERT OVERWRITE table dwd_order_facts PARTITION (order_date)
SELECT
o.order_id,
o.user_id,
o.order_time,
o.product_id,
o.quantity,
o.price,
COALESCE(o.order_status,'UNKNOWN'),
p.product_name,
p.category_id,
c.category_name,
o.order_date
FROM ods_orders o
JOIN dim_products p ON o.product_id = p.product_id
JOIN dim_categories c ON p.category_id = c.category_id
where o.price > 0;
构造DWS数据
CREATE TABLE IF NOT EXISTS dws_order_aggregates (
user_id STRING,
category_name STRING,
order_date DATE,
total_quantity INT,
total_revenue DECIMAL(10, 2),
total_orders INT
)
COMMENT '订单聚合服务表'
STORED AS PARQUET;
INSERT OVERWRITE table dws_order_aggregates
SELECT
user_id,
category_name,
order_date,
SUM(quantity) AS total_quantity,
SUM(price * quantity) AS total_revenue,
COUNT(DISTINCT order_id) AS total_orders
FROM dwd_order_facts WHERE order_status= "已完成"
GROUP BY user_id, category_name, order_date;
构造ADS数据
CREATE TABLE IF NOT EXISTS ads_product_order_report (
category_name STRING,
report_date STRING,
total_orders INT,
total_quantity INT,
total_revenue DECIMAL(10, 2)
)
COMMENT 'TOP商品报告表'
STORED AS PARQUET;
WITH ranked_category_sales AS (
SELECT
category_name,
order_date,
total_quantity,
total_revenue,
total_orders,
ROW_NUMBER() OVER (PARTITION BY order_date ORDER BY total_revenue DESC) AS revenue_rank
FROM
dws_order_aggregates
)
INSERT OVERWRITE table ads_product_order_report
SELECT
category_name,
order_date,
total_quantity,
total_revenue,
total_orders
FROM
ranked_category_sales
WHERE
revenue_rank <= 10;
3. Hive Catalog打通
Hive配置和Hadoop配置
scp hive-site.xml hdfs-site.xml core-site.xml sr@node:/home/disk1/sr/fe/conf
scp hdfs-site.xml core-site.xml sr@node:/home/disk1/sr/be/conf
Kerberos客户端配置
scp krb5.conf sr@node:/etc/krb5.conf
FE配置
JAVA_OPTS = "-Dlog4j2.formatMsgNoLookups=true -Xmx8192m -XX:+UseG1GC -Xlog:gc*:${LOG_DIR}/fe.gc.log.$DATE:time -XX:ErrorFile=${LOG_DIR}/hs_err_pid%p.log -Djava.security.policy=${STARROCKS_HOME}/conf/udf_security.policy -Djava.security.krb5.conf=/etc/krb5.conf"
BE配置
JAVA_OPTS_FOR_JDK_9_AND_LATER = "-Djava.security.krb5.conf=/etc/krb5.conf"
重启BE和FE加载配置
./bin/stop_be.sh
./bin/start_be.sh --daemon
./bin/stop_fe.sh
./bin/start_fe.sh --daemon
4. 湖分析
4.1 Hive Catalog查Hive结果集
DWS
set catalog hive_catalog_krb5;
use orders;
SELECT * from dws_order_aggregates;
ADS
SELECT * from ads_product_order_report;
4.2 利用StarRocks Hive Catalog + datacache现查
--打开datacache
SET enable_scan_datacache = true;
be配置(be.conf)开启datacache
datacache_disk_path = /data2/datacache
datacache_enable = true
datacache_disk_size = 200G
--cache预加载
cache select * from hive_catalog_krb5.orders.dwd_order_facts;
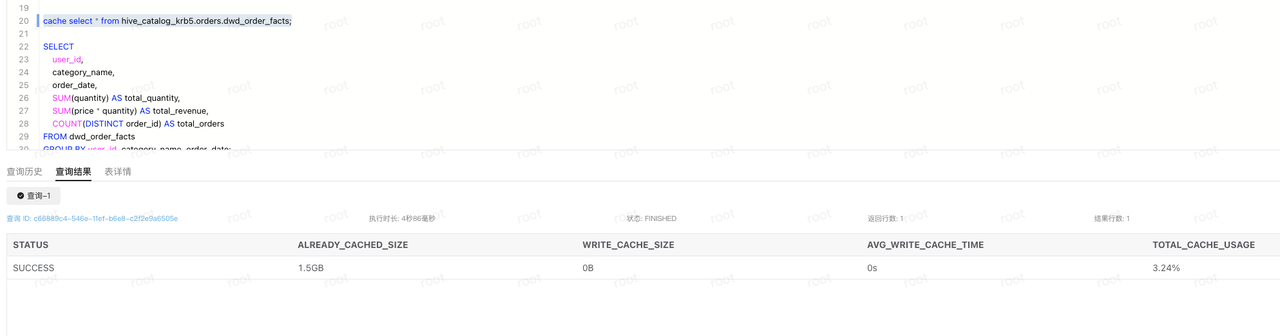
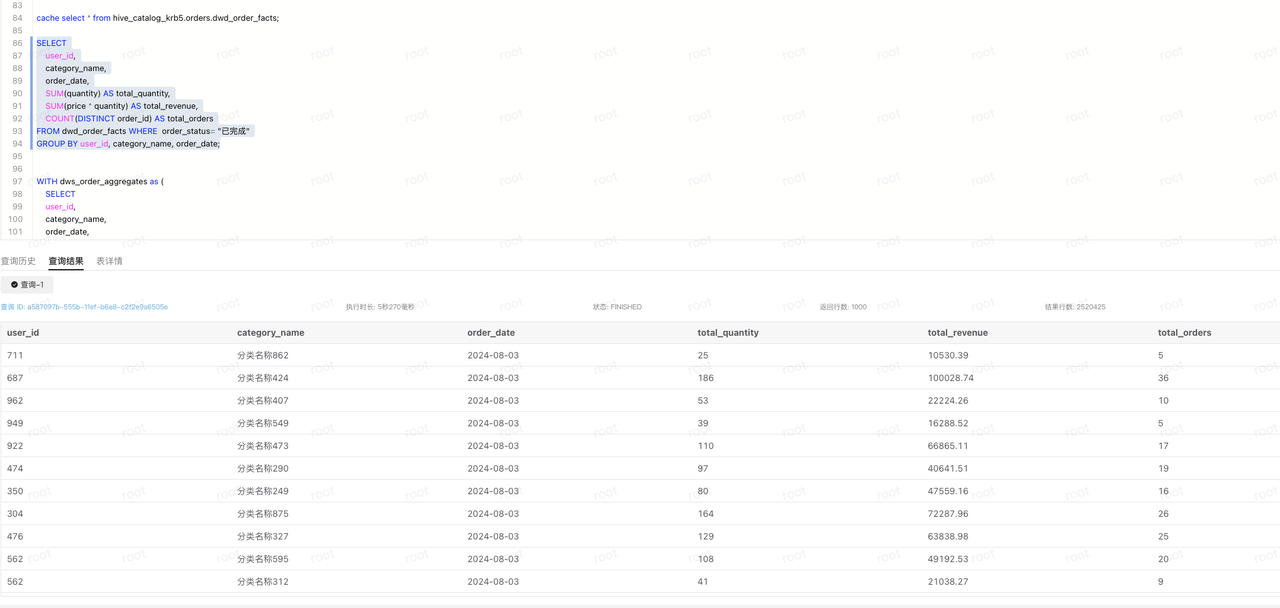
DWS
set catalog hive_catalog_krb5;
use orders;
SELECT
user_id,
category_name,
order_date,
SUM(quantity) AS total_quantity,
SUM(price * quantity) AS total_revenue,
COUNT(DISTINCT order_id) AS total_orders
FROM dwd_order_facts WHERE order_status= "已完成"
GROUP BY user_id, category_name, order_date;
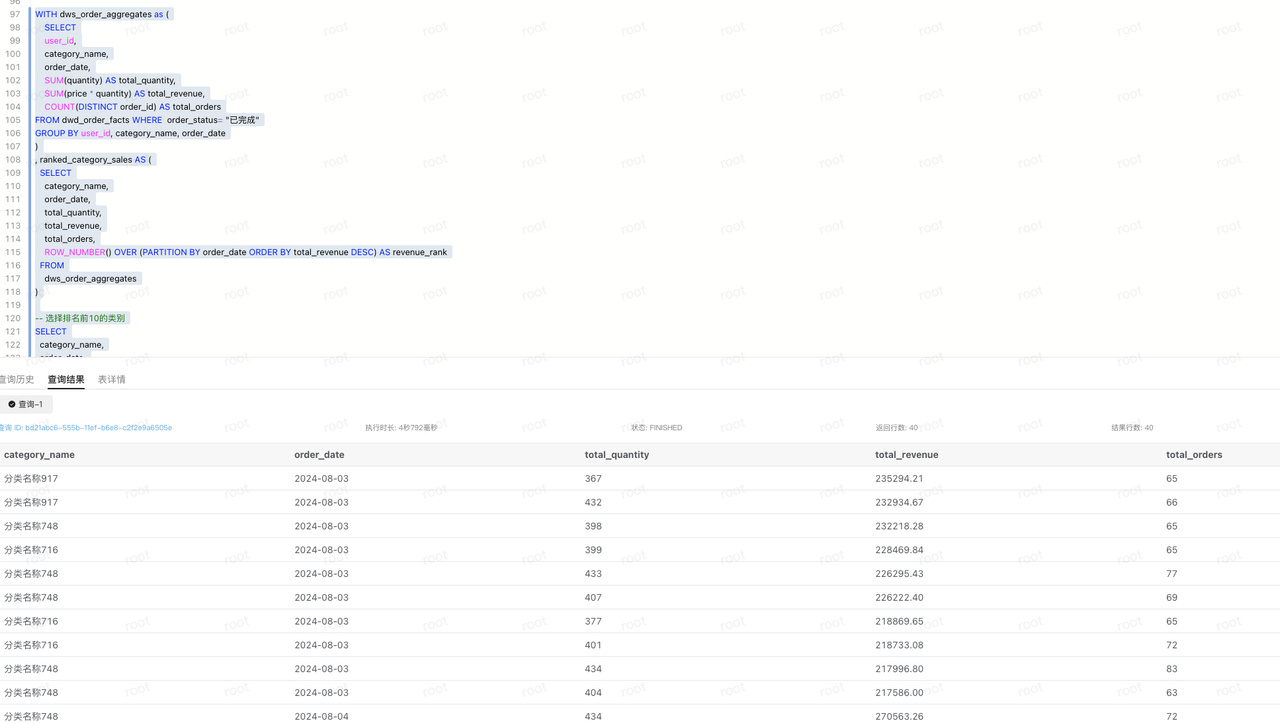
ADS
set catalog hive_catalog_krb5;
use orders;
WITH dws_order_aggregates as (
SELECT
user_id,
category_name,
order_date,
SUM(quantity) AS total_quantity,
SUM(price * quantity) AS total_revenue,
COUNT(DISTINCT order_id) AS total_orders
FROM dwd_order_facts WHERE order_status= "已完成"
GROUP BY user_id, category_name, order_date
)
, ranked_category_sales AS (
SELECT
category_name,
order_date,
total_quantity,
total_revenue,
total_orders,
ROW_NUMBER() OVER (PARTITION BY order_date ORDER BY total_revenue DESC) AS revenue_rank
FROM
dws_order_aggregates
)
-- 选择排名前10的类别
SELECT
category_name,
order_date,
total_quantity,
total_revenue,
total_orders
FROM
ranked_category_sales
WHERE
revenue_rank <= 10;
4.2 异步物化视图加速
set catalog default_catalog;
use orders;
CREATE MATERIALIZED VIEW dwd_order_facts_mv PARTITION BY str2date(order_date,'%Y-%m-%d') DISTRIBUTED BY HASH(`order_id`) BUCKETS 12 PROPERTIES ("replication_num" = "3") REFRESH ASYNC START('2024-08-01 01:00:00') EVERY (interval 1 day) as
SELECT
o.order_date,
o.order_id,
o.user_id,
o.order_time,
o.product_id,
o.quantity,
o.price,
COALESCE(o.order_status,'UNKNOWN') as order_status,
p.product_name,
p.category_id,
c.category_name
FROM hive_catalog_krb5.orders.ods_orders o
JOIN hive_catalog_krb5.orders.dim_products p ON o.product_id = p.product_id
JOIN hive_catalog_krb5.orders.dim_categories c ON p.category_id = c.category_id
where o.price > 0;
新分区自动感知
新增8月6号的数据(hive侧),构造数据
#!/usr/bin/env python3
import random
import time
def generate_order_data(num_records):
with open('ods_orders_0806.txt', 'w') as f:
for i in range(1, num_records + 1):
order_id = i
user_id = random.randint(1, 1000)
order_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(random.randint(1722873600, 1722959999)))
product_id = random.randint(1, 10000)
quantity = random.randint(1, 10)
price = round(random.uniform(10, 1000), 2)
order_status = '已完成' if random.random() < 0.9 else '已取消'
f.write(f"{order_id},{user_id},{order_time},{product_id},{quantity},{price},{order_status}\n")
generate_order_data(10000000)
--hive侧执行
LOAD DATA LOCAL INPATH '/home/disk1/sr/ods_orders_0806.txt' INTO TABLE ods_orders_text;
INSERT OVERWRITE table ods_orders PARTITION (order_date="2024-08-06") select * from ods_orders_text where order_date >= "2024-08-06 00:00:00";
--手动触发一次物化视图刷新
REFRESH MATERIALIZED VIEW dwd_order_facts_mv;
--查看对应的物化视图刷新状态为SUCCESS后,即可进行后续的查询
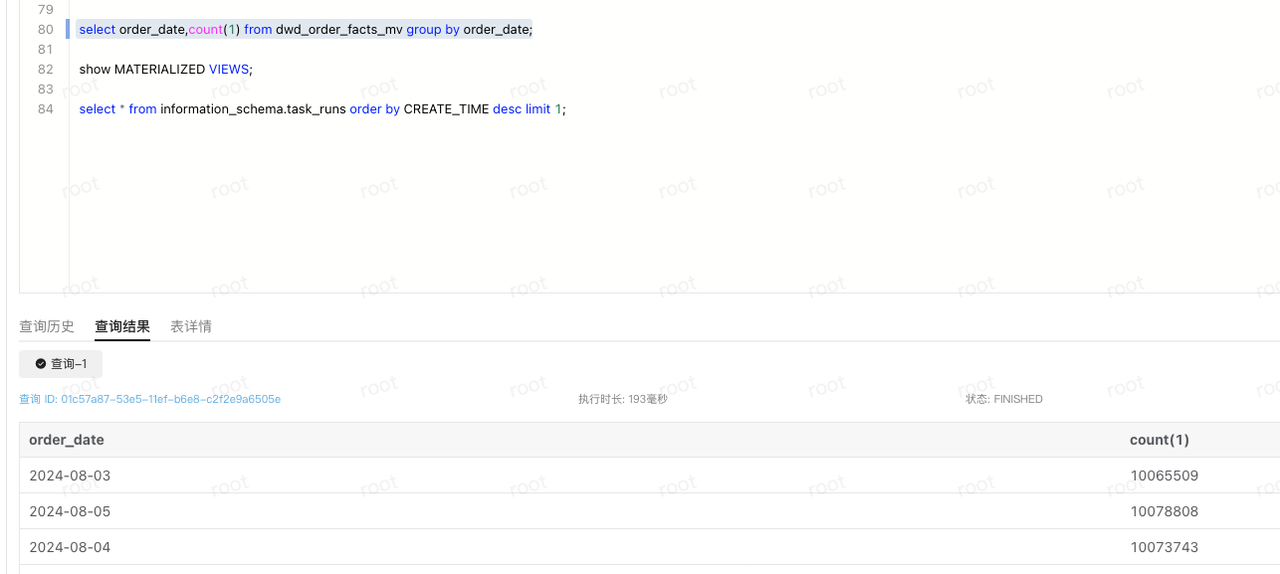
select * from information_schema.task_runs order by CREATE_TIME desc limit 1;
--查看物化视图是否感知到新的数据
select order_date,count(1) from dwd_order_facts_mv group by order_date;
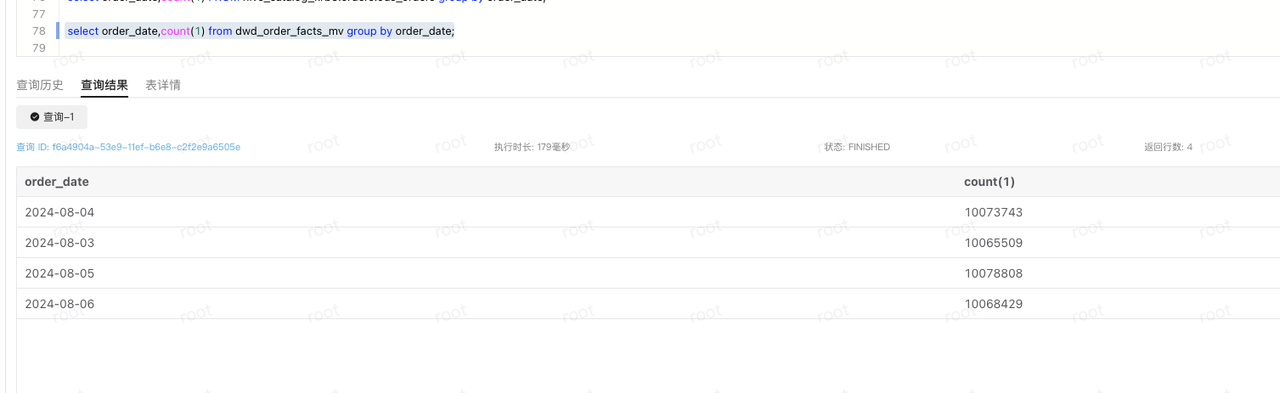
DWS
set catalog default_catalog;
use orders;
SELECT
user_id,
category_name,
order_date,
SUM(quantity) AS total_quantity,
SUM(price * quantity) AS total_revenue,
COUNT(DISTINCT order_id) AS total_orders
FROM dwd_order_facts_mv WHERE order_status= "已完成"
GROUP BY user_id, category_name, order_date;
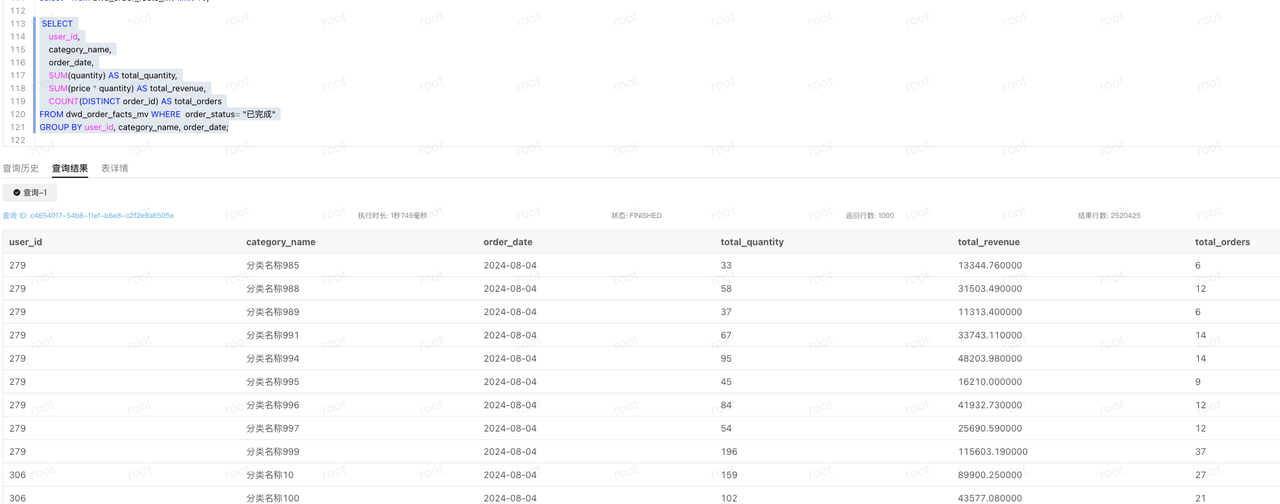
ADS
set catalog default_catalog;
use orders;
CREATE MATERIALIZED VIEW dws_order_aggregates_mv PARTITION BY str2date(order_date,'%Y-%m-%d') DISTRIBUTED BY HASH(`user_id`) BUCKETS 12 PROPERTIES ("replication_num" = "3") REFRESH ASYNC START('2024-08-01 04:00:00') EVERY (interval 1 day) as
SELECT
user_id,
category_name,
order_date,
SUM(quantity) AS total_quantity,
SUM(price * quantity) AS total_revenue,
COUNT(DISTINCT order_id) AS total_orders
FROM dwd_order_facts_mv WHERE order_status= "已完成"
GROUP BY user_id, category_name, order_date;
--手动触发一次刷新
REFRESH MATERIALIZED VIEW dws_order_aggregates_mv;
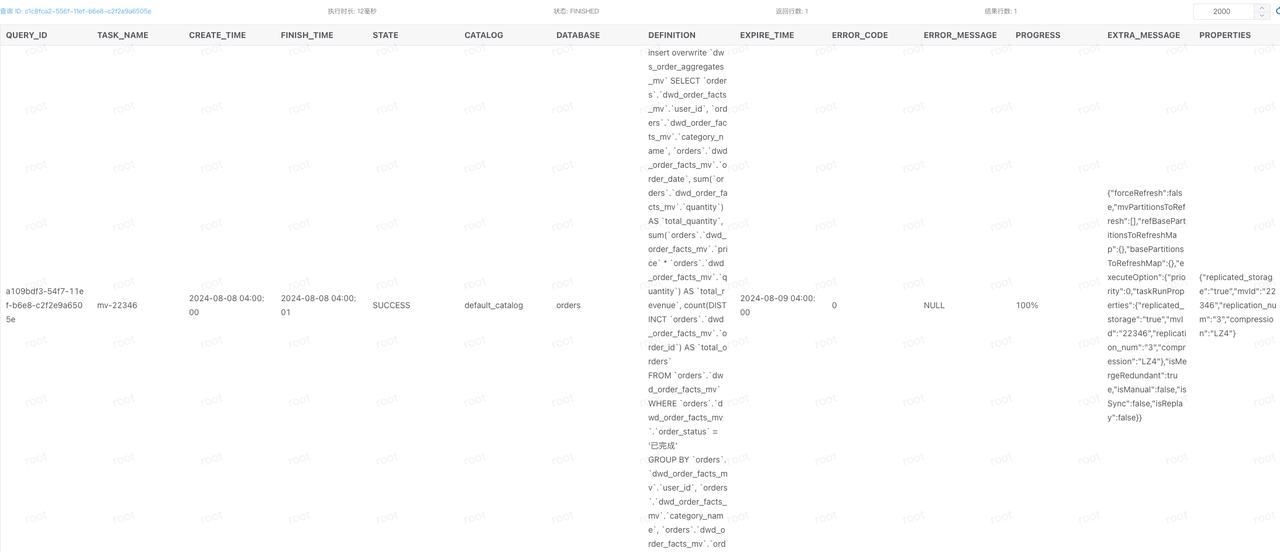
--查看对应的物化视图刷新状态为SUCCESS后,即可进行后续的查询
select * from information_schema.task_runs order by CREATE_TIME desc limit 1;
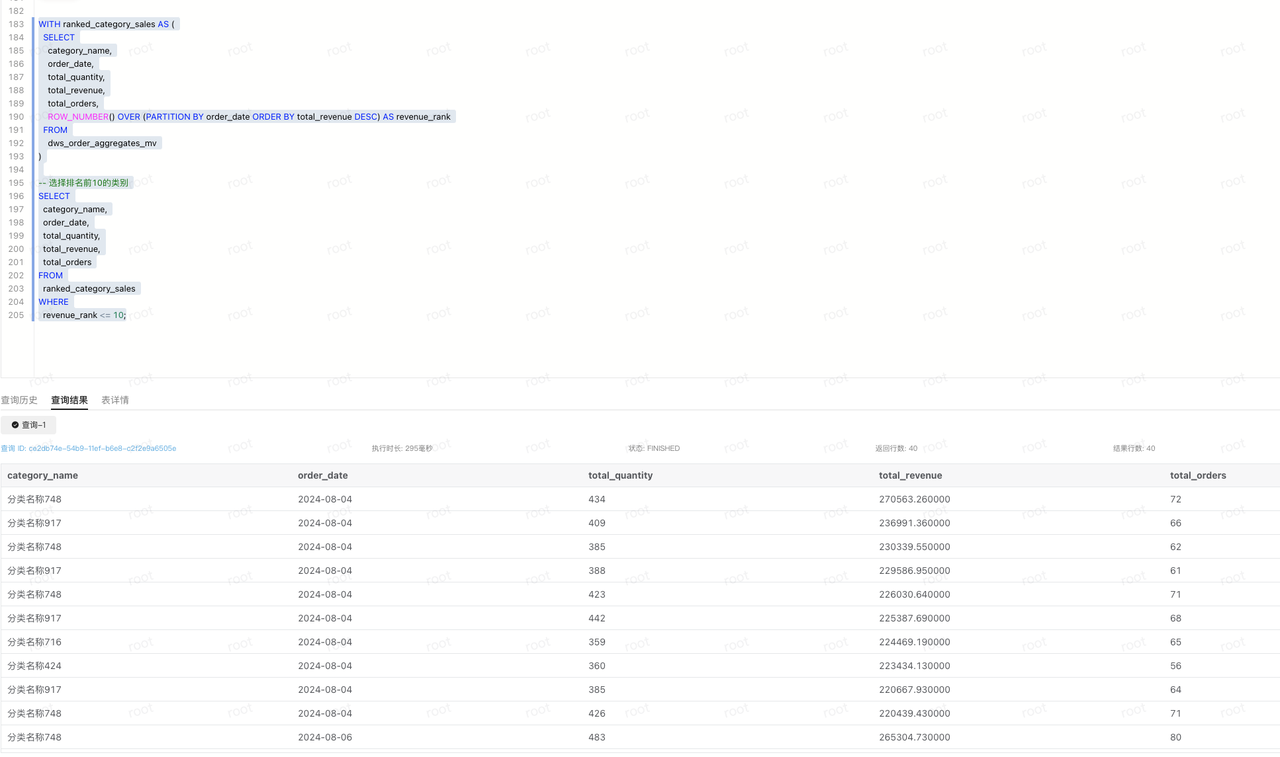
WITH ranked_category_sales AS (
SELECT
category_name,
order_date,
total_quantity,
total_revenue,
total_orders,
ROW_NUMBER() OVER (PARTITION BY order_date ORDER BY total_revenue DESC) AS revenue_rank
FROM
dws_order_aggregates_mv
)
-- 选择排名前10的类别
SELECT
category_name,
order_date,
total_quantity,
total_revenue,
total_orders
FROM
ranked_category_sales
WHERE
revenue_rank <= 10;
结论
- 大部分场景利用StarRocks Hive Catalog + DataCache 可以满足湖分析的诉求.
- 利用 StarRocks 异步物化视图可以简化ETL,降低业务使用复杂度,同时也能满足查询的性能诉求.