
为了更快的定位您的问题,请提供以下信息,谢谢
【详述】问题详细描述
建表时指定了时间分区字段和自增列做为主键
CREATE TABLE `ods_api_jingdong_adv_report_sku_zntf_info_du` (
`dt` datetime NOT NULL COMMENT "日分区",
`__id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT "__id",
`origin_data` varchar(1048576) NULL COMMENT "原始数据",
`shop_id` varchar(1048576) NULL COMMENT "店铺标识"
) ENGINE=OLAP
PRIMARY KEY(`dt`, `__id`)
COMMENT "ODS_京东广告API"
PARTITION BY date_trunc('day', dt)
DISTRIBUTED BY HASH(`dt`, `__id`)
PROPERTIES (
"replication_num" = "3",
"in_memory" = "false",
"enable_persistent_index" = "true",
"replicated_storage" = "true",
"fast_schema_evolution" = "true",
"compression" = "LZ4"
);
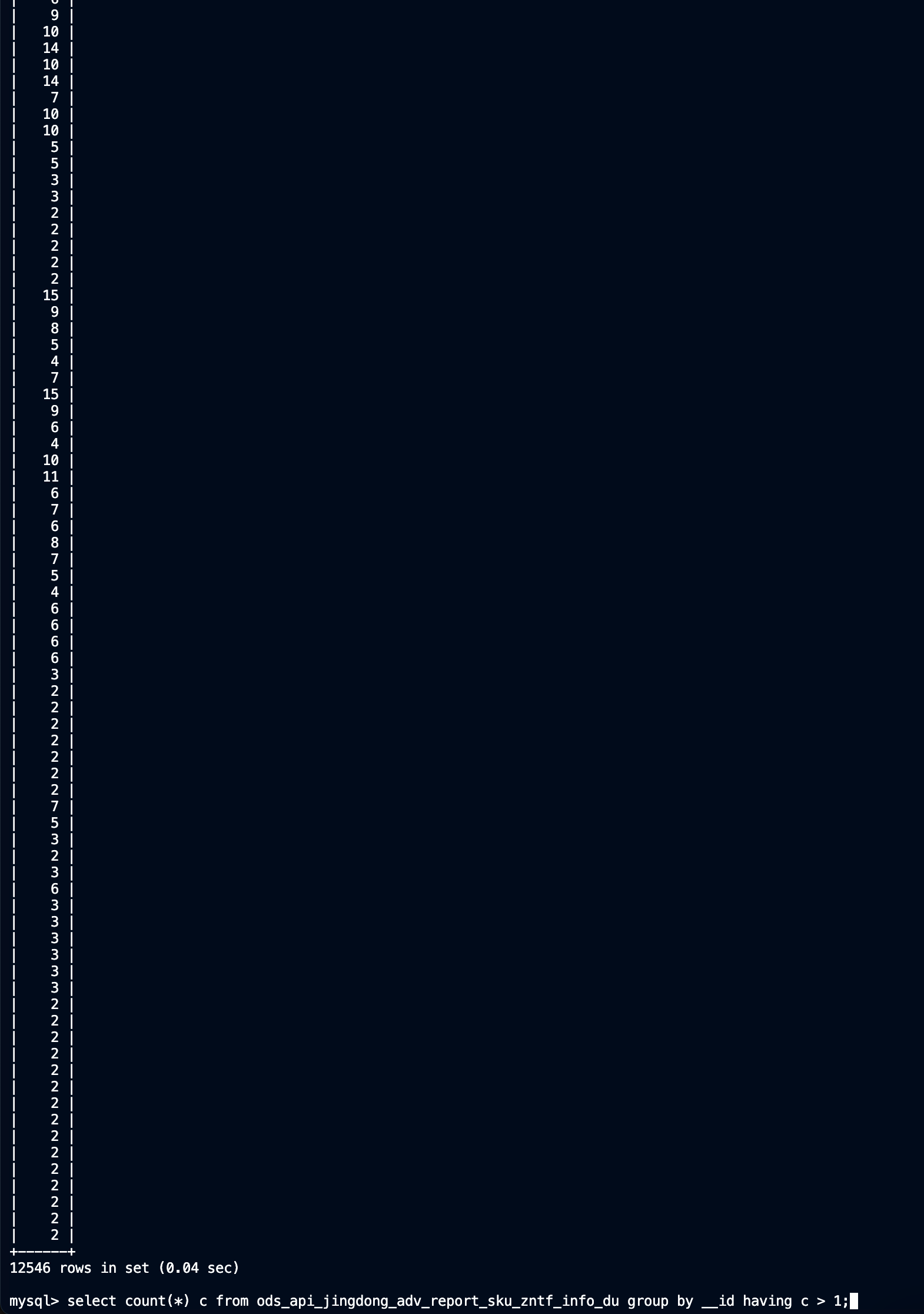
查一下id重复数大于1的有1万多条, 之前从来没有出现过这种情况, id发号都是全局唯一的不会出现重复的问题
也没有手动插入过数据
select count(*) c from ods_api_jingdong_adv_report_sku_zntf_info_du group by __id having c > 1;
【背景】做过哪些操作?
没有特殊操作
【业务影响】
【是否存算分离】 否
【StarRocks版本】例如:3.2.3
【集群规模】例如:3fe(3 follower)+3be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:48C/64G/万兆
【联系方式】为了在解决问题过程中能及时联系到您获取一些日志信息,请补充下您的联系方式,例如:社区群16-可乐鸡或者邮箱,谢谢
【附件】
- fe.log/beINFO/相应截图
- 慢查询:
- Profile信息
- 并行度:show variables like ‘%parallel_fragment_exec_instance_num%’;
- pipeline是否开启:show variables like ‘%pipeline%’;
- be节点cpu和内存使用率截图
- 查询报错:
- query_dump,怎么获取query_dump文件
- be crash
- be.out
- 外表查询报错
- be.out和fe.warn.log