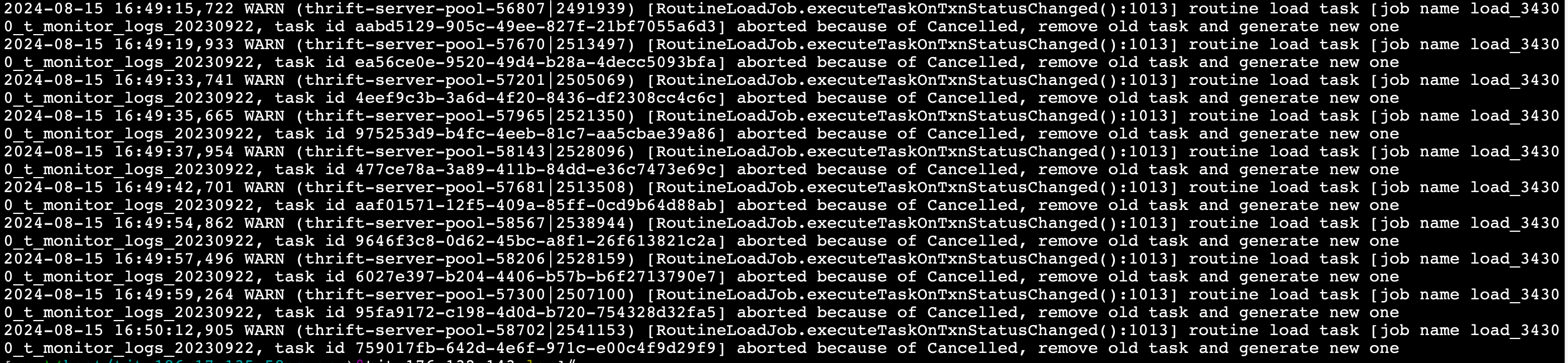
@jingdan 将fe参数routine_load_task_consume_second调整为15之后,fe leader的fe.log又出现了大量的关于timeout by txn manager的日志, 请问这个是什么原因呢?有什么解决方案呢?
grep 78442349 fe.log
2024-08-16 13:49:50,028 INFO (pool-17-thread-8|666) [DatabaseTransactionMgr.beginTransaction():301] begin transaction: txn_id: 78442349 with label 3fd6cf18-1505-435f-bc91-88aab6a8c0bc from coordinator FE: 10.176.132.143, listner id: 67422
2024-08-16 13:50:05,032 INFO (txnTimeoutChecker|83) [DatabaseTransactionMgr.abortTimeoutTxns():1525] transaction [78442349] is timeout, abort it by transaction manager
2024-08-16 13:50:05,405 INFO (thrift-server-pool-58706|2541157) [FrontendServiceImpl.loadTxnCommit():936] receive txn commit request. db: default_cluster:beidou_rslog_database, tbl: t_monitor_logs_date, txn_id: 78442349, backend: 10.176.137.14
2024-08-16 13:50:05,405 WARN (thrift-server-pool-58706|2541157) [FrontendServiceImpl.loadTxnCommit():958] failed to commit txn_id: 78442349: timeout by txn manager
2024-08-16 13:50:05,405 INFO (thrift-server-pool-58206|2528159) [FrontendServiceImpl.loadTxnRollback():1046] receive txn rollback request. db: default_cluster:beidou_rslog_database, tbl: t_monitor_logs_date, txn_id: 7844234, reason: timeout by txn manager, backend: 10.176.137.14
2024-08-16 13:50:05,406 WARN (thrift-server-pool-58206|2528159) [FrontendServiceImpl.loadTxnRollback():1064] failed to rollback txn 78442349: transaction not found
grep 3fd6cf18-1505-435f-bc91-88aab6a8c0bc be.INFO
I0816 13:49:50.023895 128493 routine_load_task_executor.cpp:221] submit a new routine load task: id=3fd6cf181505435f-bc9188aab6a8c0bc, job_id=67422, txn_id: 78442349, label=load_34300_t_monitor_logs_date-67422-3fd6cf18-1505-435f-bc91-88aab6a8c0bc-78442349, db=default_cluster:beidou_rslog_database, current tasks num: 4
I0816 13:49:50.023911 620331 routine_load_task_executor.cpp:238] begin to execute routine load task: id=3fd6cf181505435f-bc9188aab6a8c0bc, job_id=67422, txn_id: 78442349, label=load_34300_t_monitor_logs_date-67422-3fd6cf18-1505-435f-bc91-88aab6a8c0bc-78442349, db=default_cluster:beidou_rslog_database
I0816 13:49:50.024528 620331 stream_load_executor.cpp:57] begin to execute job. label=load_34300_t_monitor_logs_date-67422-3fd6cf18-1505-435f-bc91-88aab6a8c0bc-78442349, txn_id: 78442349, query_id=3fd6cf18-1505-435f-bc91-88aab6a8c0bc
I0816 13:49:50.024559 620331 plan_fragment_executor.cpp:68] Prepare(): query_id=3fd6cf18-1505-435f-bc91-88aab6a8c0bc fragment_instance_id=3fd6cf18-1505-435f-bc91-88aab6a8c0bd backend_num=0
I0816 13:49:50.025877 620331 data_consumer_group.cpp:101] start consumer group: 1646ff65fd091cdb-2d7ad5d4ef6c5893. max time(ms): 15000, batch size: 524288000. id=3fd6cf181505435f-bc9188aab6a8c0bc, job_id=67422, txn_id: 78442349, label=load_34300_t_monitor_logs_date-67422-3fd6cf18-1505-435f-bc91-88aab6a8c0bc-78442349, db=default_cluster:beidou_rslog_database
I0816 13:50:05.396423 620234 tablet_sink.cpp:1071] Olap table sink statistics. load_id: 3fd6cf18-1505-435f-bc91-88aab6a8c0bc, txn_id: 78442349, add chunk time(ms)/wait lock time(ms)/num: {10729:(354)(0)(2)} {10002:(13)(0)(2)} {10584:(11)(0)(2)} {10831:(35)(0)(3)} {10787:(23)(0)(3)} {10670:(16)(0)(2)} {10004:(10)(0)(2)} {62765:(13)(0)(2)} {103038:(25)(0)(3)} {10003:(11)(0)(2)}
W0816 13:50:05.398897 620331 stream_load_executor.cpp:201] commit transaction failed, errmsg=timeout by txn managerid=3fd6cf181505435f-bc9188aab6a8c0bc, job_id=67422, txn_id: 78442349, label=load_34300_t_monitor_logs_date-67422-3fd6cf18-1505-435f-bc91-88aab6a8c0bc-78442349, db=default_cluster:beidou_rslog_database
I0816 13:50:05.399330 620331 routine_load_task_executor.cpp:207] finished routine load task id=3fd6cf181505435f-bc9188aab6a8c0bc, job_id=67422, txn_id: 78442349, label=load_34300_t_monitor_logs_date-67422-3fd6cf18-1505-435f-bc91-88aab6a8c0bc-78442349, db=default_cluster:beidou_rslog_database, status: timeout by txn manager, current tasks num: 2