为了更快的定位您的问题,请提供以下信息,谢谢
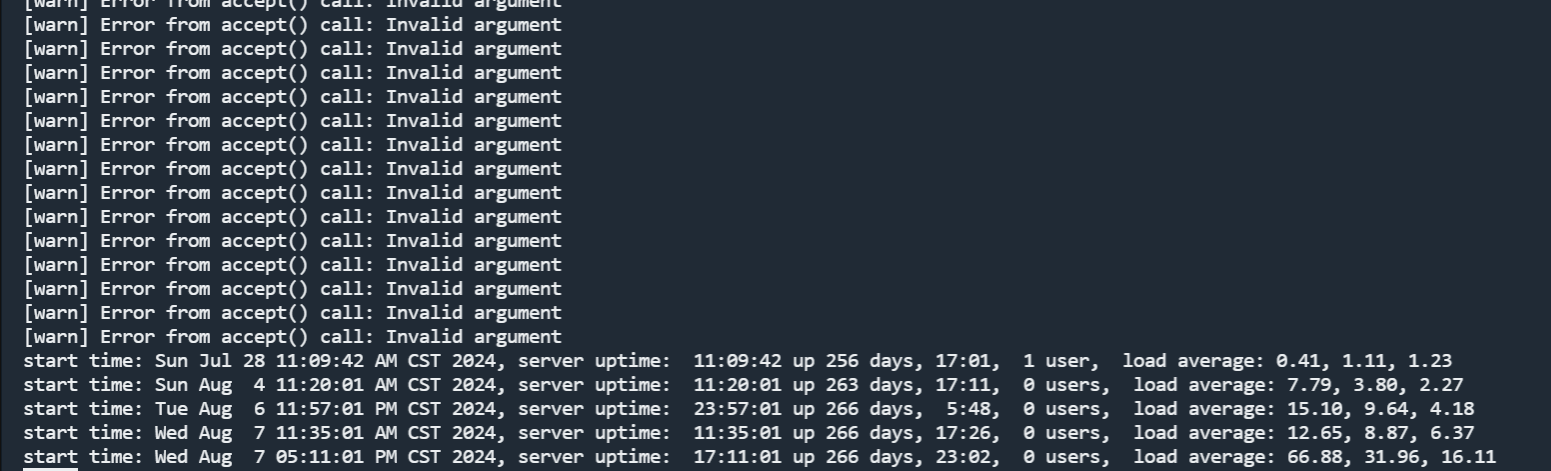
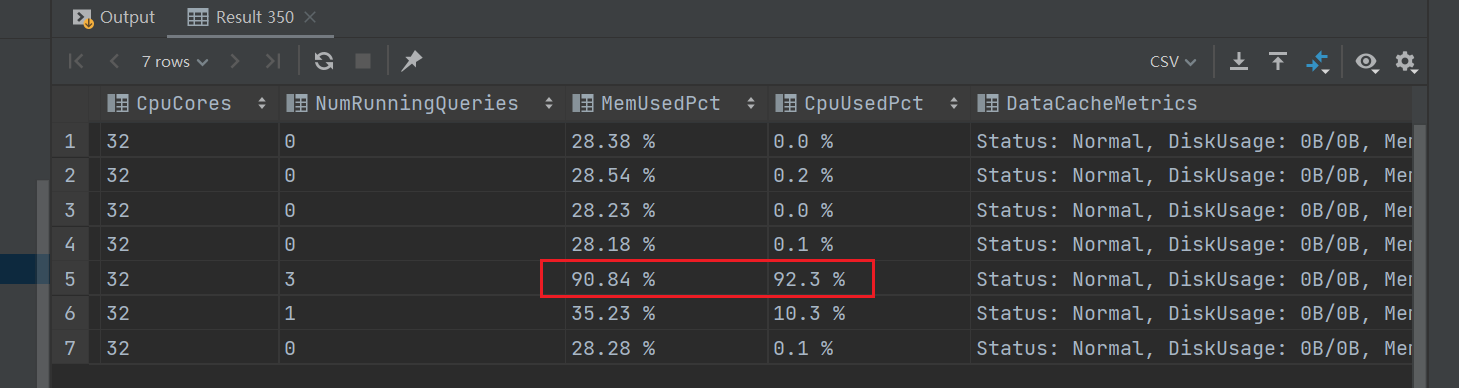
【详述】在正常使用时,发现CN集群的部分节点CPU和内存占用过高,90%以上,cn.INFO显示大量的 pipeline_driver.cpp:552] begin to cancel operators for query_id=3f41fdc7-549e-11ef-b730-fa163e0f068b driver=driver_5_47, status=PENDING_FINISH 相关信息
【背景】正常结合BI系统使用,不排除有大查询操作
【业务影响】查询数据缓慢,CN节点存在因为CPU占用过高导致Crash的情况
【是否存算分离】是
【StarRocks版本】3.3.0
【集群规模】3fe + 7cn(cn单独部署)
【机器信息】CPU虚拟核/内存/网卡,例如:32C/128G/万兆
【联系方式】tanheyuan@outlook.com
【附件】
- cn.INFO相应截图
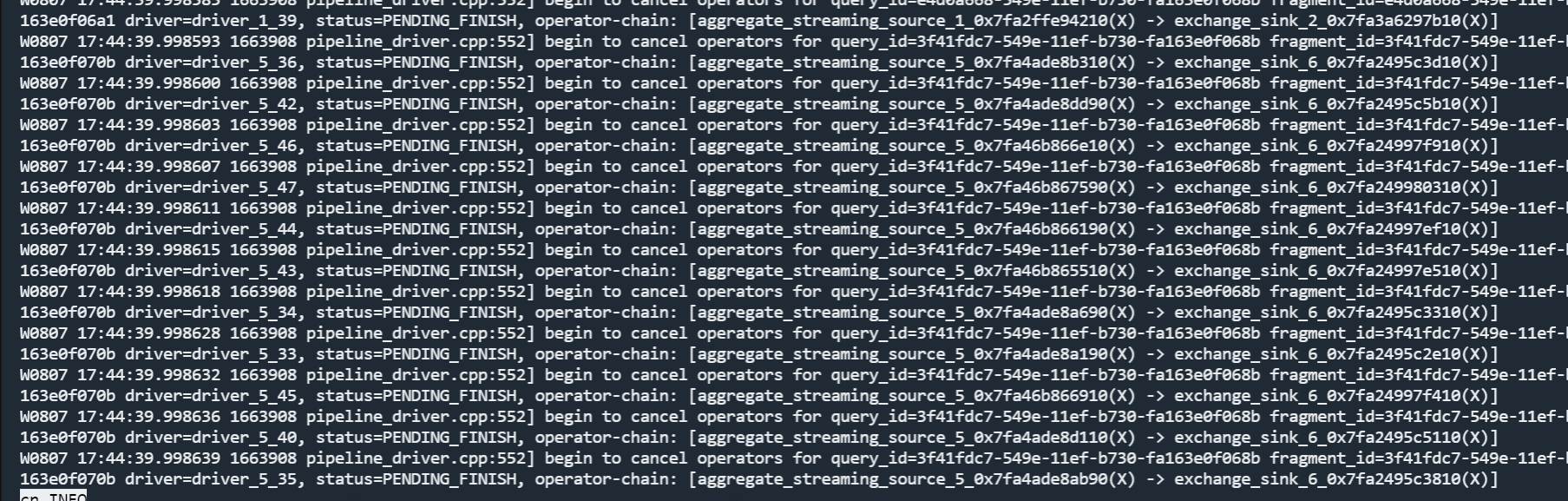
【期望结果】确定是否是正常的文件Pending_Finish过程导致的,如果是,有什么相关参数可以优化调整
【补充信息】
今天从对应的pipeline_driver.cpp代码中看到:
Status PipelineDriver::_mark_operator_cancelled(OperatorPtr& op, RuntimeState* state) {
Status res = _mark_operator_finished(op, state);
if (!res.ok()) {
LOG(WARNING) << fmt::format("fragment_id {} driver {} cancels operator {} with finished error {}",
print_id(state->fragment_instance_id()), to_readable_string(), op->get_name(),
res.message());
}
auto& op_state = _operator_stages[op->get_id()];
if (op_state >= OperatorStage::CANCELLED) {
return Status::OK();
}
VLOG_ROW << strings::Substitute("[Driver] cancelled operator [fragment_id=$0] [driver=$1] [operator=$2]",
print_id(state->fragment_instance_id()), to_readable_string(), op->get_name());
{
SCOPED_THREAD_LOCAL_OPERATOR_MEM_TRACKER_SETTER(op);
op_state = OperatorStage::CANCELLED;
return op->set_cancelled(state);
}
}
根据代码,查看cn.WARN文件发现有以下警告信息:
W0808 14:44:48.458113 2254786 pipeline_driver.cpp:791] fragment_id b0fe6a9a-5551-11ef-b730-fa163e0f06cf driver query_id=b0fe6a9a-5551-11ef-b730-fa163e0f068b fragment_id=
b0fe6a9a-5551-11ef-b730-fa163e0f06cf driver=driver_45_39, status=PRECONDITION_BLOCK(), operator-chain: [aggregate_blocking_source_45_0x7f54ac8de710(O) -> hash_join_probe
_51_0x7f54ac8dec10(X)(HashJoiner=0x7f561e965f10) -> chunk_accumulate_51_0x7f54ac8dee90(X) -> project_52_0x7f5914e4b910(X) -> hash_join_build_53_0x7f54ac8df390(X)(HashJoi
ner=0x7f54ac8df110)] cancels operator hash_join_build_53_0x7f54ac8df390(X)(HashJoiner=0x7f54ac8df110) with finished error runtime state is cancelled
W0808 14:44:48.457201 2254786 pipeline_driver.cpp:791] fragment_id b0fe6a9a-5551-11ef-b730-fa163e0f06cf driver query_id=b0fe6a9a-5551-11ef-b730-fa163e0f068b fragment_id=b0fe6a9a-5551-11ef-b730-fa163e0f06cf driver=driver_50_14, status=INPUT_EMPTY, operator-chain: [exchange_source_50_0x7f561eea6690(O) -> hash_join_build_51_0x7f561eea6b90(
X)(HashJoiner=0x7f561eea6910)] cancels operator hash_join_build_51_0x7f561eea6b90(X)(HashJoiner=0x7f561eea6910) with finished error runtime state is cancelled
对应着状态:INPUT_EMPTY和PRECONDITION_BLOCK()