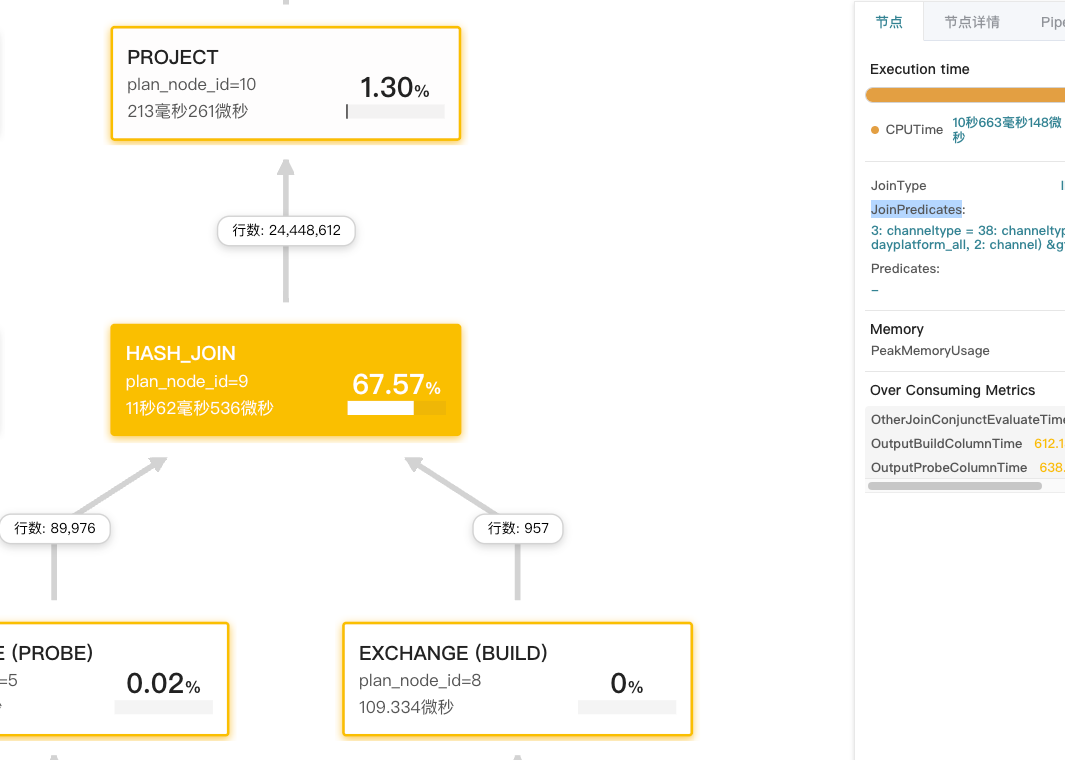
秀秀老师, 还有一个case , join + row_number 窗口排序函数的, 相对trino来说是个明显的
profile 文件:
badcase080901.profile (216.4 KB)
SELECT vbi.name, t2.qqPlayTimes, t2.mangguoPlayTimes, t2.letvPlayTimes, t2.sohuPlayTimes, t2.pptvPlayTimes, t2.iqiyiPlayTimes, t2.youkuPlayTimes, t2.xiguaPlayTimes, t2.qqPlayTimesPredicted, t2.mangguoPlayTimesPredicted, t2.letvPlayTimesPredicted, t2.sohuPlayTimesPredicted, t2.pptvPlayTimesPredicted, t2.iqiyiPlayTimesPredicted, t2.youkuPlayTimesPredicted, t2.xiguaPlayTimesPredicted, t2.totalPlayTimes, t2.totalPlayTimesPredicted, t2.qqserialnum, t2.mangguoserialnum, t2.letvserialnum, t2.sohuserialnum, t2.pptvserialnum, t2.iqiyiserialnum, t2.youkuserialnum, t2.xiguaserialnum, t2.maxserialnum, vbi.tags, vbi.releasetime, vbi.network, vbi.dayPlatform, vbi.hpURL, vbi.area, vbi.bcType, vbi.directorinfo, vbi.screenwriterinfo, vbi.actorinfo, vbi.producerinfo, vbi.productioncompanyinfo, vbi.db_rating, vbi.db_ratingtimes, coalesce(vbi.episodenum_bilibili, cast(vbi.episodenum as varchar)) as episodenum, vbi.totalepisodenum, vbi.presenterinfo, vbi.guestinfo, vbi.originalid, vbi.duration, vbi.dayplatform_start, vbi.editedflag, vbi.dayplatform_all, t2.bilibiliPlayTimes, t2.bilibiliPlayTimesPredicted, vbi.offlinetime, vbi.ismemberfree, vbi.copyright, vbi.isvip, vbi.notvipdowntime FROM ( SELECT name, sum(playtimespredicted) AS totalPlayTimesPredicted FROM ( SELECT *, row_number() over (partition BY name,channel,channelType ORDER BY DAY DESC) R FROM ( SELECT B.name AS name, A.channel AS channel, A.channelType AS channelType, play_times, A.playtimespredicted_avg as playtimespredicted, DAY, serialnum FROM default_catalog.enlightent_daily.rank_view_days A JOIN hive_old.mysql_prod_enlightent_daily.video_basic_info_extra B ON lower(A.name) = lower(B.name) AND A.channelType=B.channelType WHERE DAY<='2020-12-24' AND vn=30 AND A.channelType='tv' AND instr(B.dayplatform_all, A.channel) > 0 AND B.releasetime BETWEEN '2020-01-01' AND '2020-12-24' ) T ) T_R WHERE R=1 GROUP BY name ) t2 RIGHT JOIN hive_old.mysql_prod_enlightent_daily.video_basic_info_extra vbi ON lower(vbi.name) = lower(t2.name) WHERE vbi.channelType = 'tv' AND vbi.releasetime BETWEEN '2020-01-01' and '2020-12-24' AND vbi.editedflag >=0 AND vbi.editedflag !=2 AND vbi.dayplatform_all != 'NULL' AND vbi.dayplatform_all != '' ORDER BY t2.totalPlayTimesPredicted DESC
这个join + row_number 的数据结果有点炸裂