【导入/导出方式】routine load入库
【背景】做过哪些操作?集群正在进行资源调整,有BE的扩容缩容操作
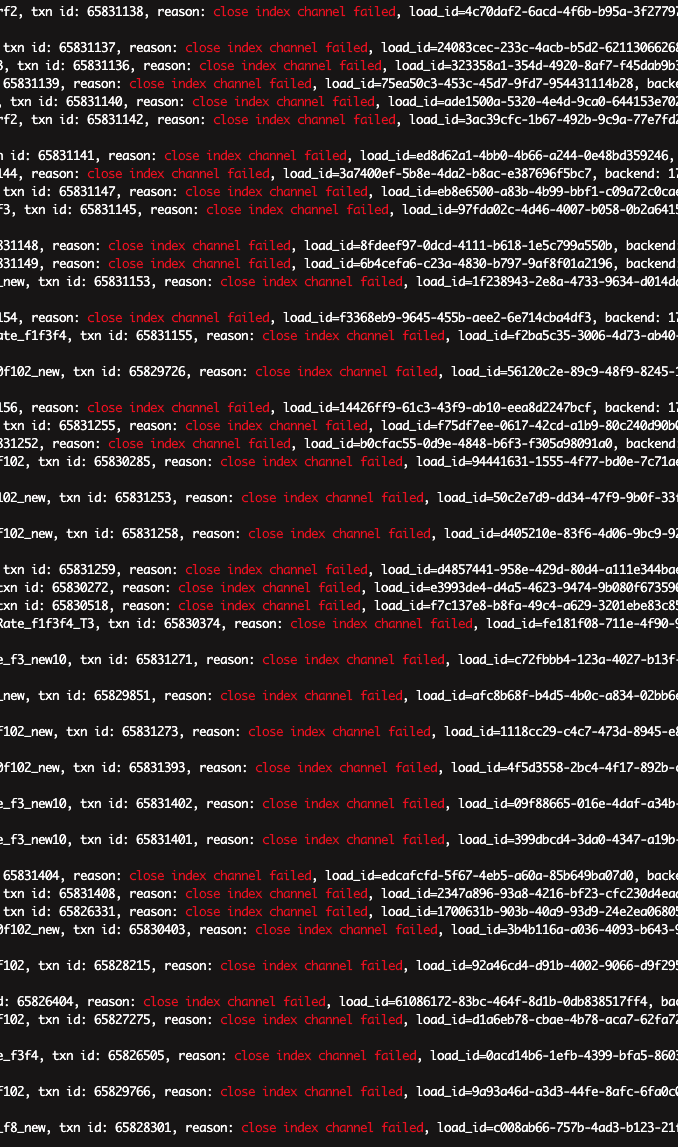
【业务影响】routine load基本都在abort
【StarRocks版本】例如:1.18.2
【集群规模】例如:6FE(16 follower)+10be(fe与be混部)
【机器信息】64C/512G/万兆
【附件】
- fe.warn.log/be.warn.log/相应截图

下掉的be有drop掉吗,show backends看下还有几台信息,可能是指向之前的节点了?
先decommssion,然后再dropp掉,存在的都是在用的BE节点,从查询看BE都已经是不存在了,我担心是不是内部还在指向已经下掉的BE节点
https://docs.starrocks.com/zh-cn/main/sql-reference/sql-statements/data-manipulation/SHOW%20ROUTINE%20LOAD
看下任务很多吗。SHOW ROUTINE LOAD
再fe目录下执行java -jar lib/je-7.3.7.jar DbGroupAdmin -helperHosts xxx.xxx.xxx.xxx:port -groupName PALO_JOURNAL_GROUP -dumpGroup
看看返回结果和当前fe一致吗。改下相应的ip和port,port为EditLogPort
看了下,fe是一致的,然后routine load的任务在接近70个,BE从13个缩容到8个了
下面是fe的部分日志,
2022-01-18 11:36:08,655 WARN (thrift-server-pool-8200|212555) [FrontendServiceImpl.loadTxnRollback():770] failed to rollback txn 65791133: transaction not found
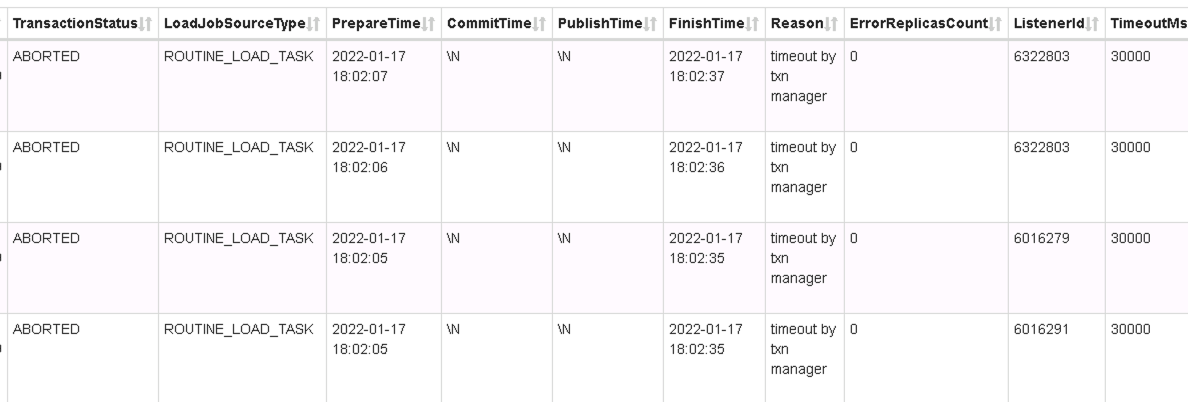
2022-01-18 11:36:09,058 WARN (txnCleaner|77) [RoutineLoadJob.executeTaskOnTxnStatusChanged():973] routine load task [job name ***, task id 5a054e4a-cf3d-4d65-9c70-58ac2afcb2ce] aborted because of timeout by txn manager, remove old task and generate new one
2022-01-18 11:36:09,753 WARN (pool-10-thread-7|342) [RoutineLoadTaskScheduler.scheduleOneTask():258] failed to submit routine load task 8733f357-340b-46bf-adb5-061ea26815ef to BE: 743500
2022-01-18 11:36:10,363 WARN (pool-10-thread-2|294) [RoutineLoadTaskScheduler.scheduleOneTask():258] failed to submit routine load task 4808dc85-30c9-4b2c-a38b-0bb0954397a0 to BE: 10250
2022-01-18 11:36:11,482 WARN (pool-10-thread-9|344) [RoutineLoadTaskScheduler.scheduleOneTask():258] failed to submit routine load task ae4f9f6e-219d-4d3e-b08f-23c99b98499a to BE: 6310274
2022-01-18 11:36:11,529 WARN (txnCleaner|77) [RoutineLoadJob.executeTaskOnTxnStatusChanged():973] routine load task [job name kfc_ph_H5Duration_f1, task id 147c58b3-5b1e-41ad-b145-56032e00b10a] aborted because of timeout by txn manager, remove old task and generate new one
2022-01-18 11:36:13,183 WARN (pool-10-thread-3|295) [RoutineLoadTaskScheduler.scheduleOneTask():258] failed to submit routine load task a3e74386-be2b-4b04-88a3-9a4ca7f6c3c6 to BE: 743500
这是FE master的gc日志。
: 3355548.363: [ParNew: 581279K->18566K(629120K), 0.0170010 secs] 20991805K->20434729K(26442512K), 0.0172496 secs] [Times: user=0.54 sys=0.00, real=0.02 secs]
2022-01-18T12:52:11.413+0800: 3355589.168: [GC (Allocation Failure) 2022-01-18T12:52:11.413+0800: 3355589.168: [ParNew: 577798K->18577K(629120K), 0.0138436 secs] 20993961K->20435747K(26442512K), 0.0140848 secs] [Times: user=0.46 sys=0.00, real=0.01 secs]
2022-01-18T12:53:00.038+0800: 3355637.793: [GC (Allocation Failure) 2022-01-18T12:53:00.038+0800: 3355637.793: [ParNew: 577809K->22158K(629120K), 0.0198740 secs] 20994979K->20440246K(26442512K), 0.0201243 secs] [Times: user=0.35 sys=0.26, real=0.02 secs]
2022-01-18T12:53:59.186+0800: 3355696.941: [GC (Allocation Failure) 2022-01-18T12:53:59.186+0800: 3355696.941: [ParNew: 581390K->20653K(629120K), 0.0153021 secs] 20999478K->20439541K(26442512K), 0.0155507 secs] [Times: user=0.24 sys=0.27, real=0.01 secs]
2022-01-18T12:54:57.670+0800: 3355755.426: [GC (Allocation Failure) 2022-01-18T12:54:57.671+0800: 3355755.426: [ParNew: 579885K->26760K(629120K), 0.0250530 secs] 20998773K->20446637K(26442512K), 0.0253099 secs] [Times: user=0.56 sys=0.00, real=0.03 secs]
2022-01-18T12:55:39.215+0800: 3355796.970: [GC (Allocation Failure) 2022-01-18T12:55:39.215+0800: 3355796.970: [ParNew: 585992K->24703K(629120K), 0.0189435 secs] 21005869K->20445574K(26442512K), 0.0191782 secs] [Times: user=0.35 sys=0.15, real=0.02 secs]
2022-01-18T12:56:39.547+0800: 3355857.302: [GC (Allocation Failure) 2022-01-18T12:56:39.547+0800: 3355857.302: [ParNew: 583935K->18415K(629120K), 0.0326732 secs] 21004806K->20442513K(26442512K), 0.0329135 secs] [Times: user=0.18 sys=0.72, real=0.03 secs]
2022-01-18T12:57:28.615+0800: 3355906.370: [GC (Allocation Failure) 2022-01-18T12:57:28.615+0800: 3355906.371: [ParNew: 577647K->18050K(629120K), 0.0186979 secs] 21001745K->20442978K(26442512K), 0.0189456 secs] [Times: user=0.57 sys=0.00, real=0.02 secs]
2022-01-18T12:58:31.511+0800: 3355969.266: [GC (Allocation Failure) 2022-01-18T12:58:31.511+0800: 3355969.266: [ParNew: 577282K->17629K(629120K), 0.0204188 secs] 21002210K->20446854K(26442512K), 0.0206831 secs] [Times: user=0.36 sys=0.12, real=0.02 secs]
2022-01-18T12:59:27.319+0800: 3356025.074: [GC (Allocation Failure) 2022-01-18T12:59:27.319+0800: 3356025.074: [ParNew: 576861K->12793K(629120K), 0.0154998 secs] 21006086K->20444880K(26442512K), 0.0157404 secs] [Times: user=0.19 sys=0.36, real=0.02 secs]
2022-01-18T13:00:05.661+0800: 3356063.416: [GC (Allocation Failure) 2022-01-18T13:00:05.661+0800: 3356063.417: [ParNew: 572025K->12915K(629120K), 0.0138704 secs] 21004112K->20445681K(26442512K), 0.0141807 secs] [Times: user=0.45 sys=0.00, real=0.02 secs]
2022-01-18T13:00:47.322+0800: 3356105.077: [GC (Allocation Failure) 2022-01-18T13:00:47.322+0800: 3356105.077: [ParNew: 572147K->14273K(629120K), 0.0140979 secs] 21004913K->20447889K(26442512K), 0.0143533 secs] [Times: user=0.47 sys=0.00, real=0.02 secs]
2022-01-18T13:01:36.057+0800: 3356153.812: [GC (Allocation Failure) 2022-01-18T13:01:36.057+0800: 3356153.812: [ParNew: 573505K->17755K(629120K), 0.0108847 secs] 21007121K->20451860K(26442512K), 0.0111388 secs] [Times: user=0.21 sys=0.18, real=0.01 secs]
2022-01-18T13:02:30.462+0800: 3356208.217: [GC (Allocation Failure) 2022-01-18T13:02:30.462+0800: 3356208.217: [ParNew: 576987K->19837K(629120K), 0.0170792 secs] 21011092K->20454639K(26442512K), 0.0173584 secs] [Times: user=0.21 sys=0.24, real=0.02 secs]
2022-01-18T13:03:32.154+0800: 3356269.910: [GC (Allocation Failure) 2022-01-18T13:03:32.155+0800: 3356269.910: [ParNew: 579069K->25949K(629120K), 0.0166233 secs] 21013871K->20461406K(26442512K), 0.0168961 secs] [Times: user=0.52 sys=0.00, real=0.01 secs]
2022-01-18T13:04:29.487+0800: 3356327.242: [GC (Allocation Failure) 2022-01-18T13:04:29.487+0800: 3356327.242: [ParNew: 585181K->25421K(629120K), 0.0140371 secs] 21020638K->20461547K(26442512K), 0.0143070 secs] [Times: user=0.47 sys=0.00, real=0.01 secs]
max_routine_load_task_num_per_be/max_routine_load_job_num这些参数改过吗,可以看下https://docs.starrocks.com/zh-cn/main/administration/Configuration这里关于参数的说明,应该是任务过多超过默认限制了,另外确认下be743500/10250/6310274的状态
max_routine_load_task_num_per_be=30
max_routine_load_task_concurrent_num=20,这些参数是修改过的值,三个BE的状态是正常的,这三个BE是混部CDH的,正在一个一个下掉,节点的磁盘比较繁忙
好的,看下日志除了这三be有别的节点任务报错么。没有的话可以逐台下掉这三be再观察下
tablet_sink.cpp:995] close channel failed. channel_name=NodeChannel[2064053-6310274], load_info=load_id=9a6d58d0-fb1b-4f1f-a4a5-b6d302870b30, txn_id=65833197, errror_msg=close wait failed coz rpc error
tablet_sink.cpp:194] NodeChannel[3075327-6310274] add batch req success but status isn’t ok, load_id=cec2c427-9681-4c16-93fe-4c063d18091c, txn_id=65832416, node=***, errmsg=fail to add batch in load channel. unknown load_id=cec2c42796814c16-93fe4c063d18091c
tablet_sink.h:121] failed to send brpc batch, error=RPC call is timed out, error_text=[E1008]Reached timeout=150000ms
还发现上面几种报错。
这个看着是导入频次太高了,把并发调低点,导入时间间隔调大以及单次导入数据量调整大点
,可以在be.WARNING里搜索too many tablet versions看到相应信息。具体的表可以根据相应tabletid去反查,show tablet tabletid会有对应表名。 tabletid可以通过在be.WARNING里检索Fail to init delta writer这个信息,类似如下,Fail to init delta writer. tablet=4990308.891563309.464b7a556e85129d-f1eedcfe96517bac, version count=1003, limit=1000
too many这个错误不多,目前主要是一个节点的be warn日志
W0118 16:17:49.727891 160625 internal_service.cpp:190] tablet writer add chunk failed, message=fail to add batch in load channel. unknown load_id=8d0fa59a4a634d20-90b425288914e8f6, id=8d0fa59a-4a63-4d20-90b4-25288914e8f6, index_id=1558176, sender_id=0
W0118 16:17:50.186133 160619 internal_service.cpp:190] tablet writer add chunk failed, message=fail to add batch in load channel. unknown load_id=c437de5bd73544ce-86055ea34649b0ef, id=c437de5b-d735-44ce-8605-5ea34649b0ef, index_id=5346196, sender_id=0
W0118 16:17:50.186357 160656 tablet_sink.cpp:194] NodeChannel[5346196-6310274] add batch req success but status isn’t ok, load_id=c437de5b-d735-44ce-8605-5ea34649b0ef, txn_id=65848993, node=****, errmsg=fail to add batch in load channel. unknown load_id=c437de5bd73544ce-86055ea34649b0ef
W0118 16:17:50.216580 160619 internal_service.cpp:190] tablet writer add chunk failed, message=fail to add batch in load channel. unknown load_id=c43571de896449f8-a1b136fc46e01e9a, id=c43571de-8964-49f8-a1b1-36fc46e01e9a, index_id=1558176, sender_id=0
W0118 16:17:50.224328 160619 internal_service.cpp:190] tablet writer add chunk failed, message=fail to add batch in load channel. unknown load_id=d7cdf5bb21be4581-80b1c1561cd0ecb1, id=d7cdf5bb-21be-4581-80b1-c1561cd0ecb1, index_id=5346196, sender_id=0
W0118 16:17:51.316535 160614 internal_service.cpp:190] tablet writer add chunk failed, message=fail to add batch in load channel. unknown load_id=0eaec395e62a4a00-90de552f1e53bb5a, id=0eaec395-e62a-4a00-90de-552f1e53bb5a, index_id=2475346, sender_id=0
W0118 16:17:51.341246 160433 fragment_mgr.cpp:183] Fail to open fragment 904f9da5-b3ce-440c-a9d9-f2c309075c8f: Cancelled: Cancelled FileScanNode::get_next
W0118 16:17:51.348873 160433 stream_load_executor.cpp:88] fragment execute failed, query_id=904f9da5b3ce440c-a9d9f2c309075c8e, err_msg=Cancelled FileScanNode::get_next, id=904f9da5b3ce440c-a9d9f2c309075c8e, job_id=6423649, txn_id=65849174, label=kfc_RnRequestDuration_f6-6423649-904f9da5-b3ce-440c-a9d9-f2c309075c8e-65849174
W0118 16:17:51.348982 160511 routine_load_task_executor.cpp:323] consume failed
W0118 16:17:54.266247 160612 internal_service.cpp:190] tablet writer add chunk failed, message=fail to add batch in load channel. unknown load_id=3957a15c98704667-91e2acdad9720ade, id=3957a15c-9870-4667-91e2-acdad9720ade, index_id=3075327, sender_id=0
W0118 16:17:54.288913 160612 internal_service.cpp:190] tablet writer add chunk failed, message=fail to add batch in load channel. unknown load_id=086f32e8c82b4a48-85e27c09fc4a3e32, id=086f32e8-c82b-4a48-85e2-7c09fc4a3e32, index_id=1654242, sender_id=0
W0118 16:17:54.323433 160612 internal_service.cpp:190] tablet writer add chunk failed, message=fail to add batch in load channel. unknown load_id=53c1784c8f324e33-9429fb4c8f5c1c40, id=53c1784c-8f32-4e33-9429-fb4c8f5c1c40, index_id=2586428, sender_id=0
W0118 16:17:54.326995 160612 internal_service.cpp:190] tablet writer add chunk failed, message=fail to add batch in load channel. unknown load_id=f0a824b960ee44b4-bd25be7c3263090f, id=f0a824b9-60ee-44b4-bd25-be7c3263090f, index_id=5824967, sender_id=0
W0118 16:17:55.048873 160617 internal_service.cpp:190] tablet writer add chunk failed, message=fail to add batch in load channel. unknown load_id=816d9a4b554145ea-b2008a57e094a0f0, id=816d9a4b-5541-45ea-b200-8a57e094a0f0, index_id=5188688, sender_id=0
W0118 16:17:55.073283 160617 internal_service.cpp:190] tablet writer add chunk failed, message=fail to add batch in load channel. unknown load_id=b6f3015690bd4279-aa09c4fddfdc84e3, id=b6f30156-90bd-4279-aa09-c4fddfdc84e3, index_id=2577421, sender_id=0
升级下把,这个1.19.5改善过
请问我可以先调下thrift_rpc_timeout_ms这个参数吗,看源码说是要Make publish timeout is less than thrift_rpc_timeout_ms,thrift_rpc_timeout_ms默认值5000,publish_version_interval_ms默认10,publish_version_timeout_second默认20,另外routine_load_thread_pool_size是不是也可以从10调大点,现在是使用的物理机节点。
默认参数的时间够了,这个是任务很多竞争比较大,理论上18.2调整后不会又很大改善,建议升级比较1.19.5+这版本做了很大的优化。