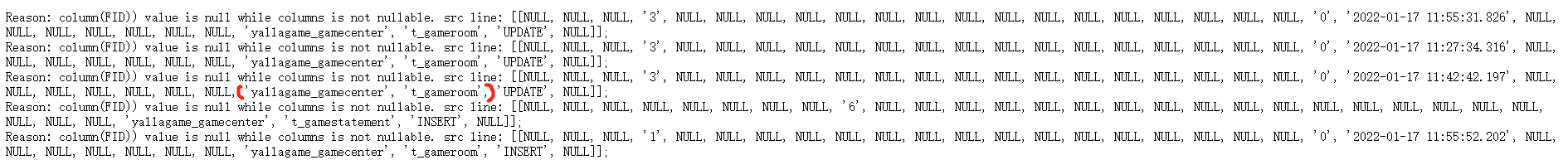kafka数据格式:内有4个数据库下的8个表的binlog数据
{
“data”:{
“FID”:“xxxxx”
“FName”:“xxxxx”
“FNationalityID”:“xxxxx”
“FHeaderUrl”:“xxxxx”
“FStatus”:“xxxxx”
“FLanguage”:“xxxxx”
“FAge”:“xxxxx”
“FSex”:“xxxxx”
“FBirthday”:“xxxxx”
“FExperience”:“xxxxx”
“FCurrency”:“xxxxx”
“FDiamond”:“xxxxx”
“FLevelID”:“xxxxx”
“FSkinID”:“xxxxx”
“FVipID”:“xxxxx”
“FRegisterSource”:“xxxxx”
“FRegisterIP”:“xxxxx”
“FRegisterTime”:“xxxxx”
“FDevice”:“xxxxx”
“FDeviceType”:“xxxxx”
“FDownLoadChannelID”:“xxxxx”
“FIsDeleted”:“xxxxx”
“FModifyTime”:“xxxxx”
“FIsUsed”:“xxxxx”
“FAccountType”:“xxxxx”
“FVipValue”:“xxxxx”
“FIsRecharged”:“xxxxx”
“FPushToken”:“xxxxx”
“FPrettyId”:“xxxxx”
“FDeleteStatus”:“xxxxx”
},
“database”:“test_db1”,
“table”:“test_tb1”,
“type”:“INSERT”
}
我的starrocks端建表语句:
CREATE TABLE IF NOT EXISTS ods.test_tb1 (
FID STRING NOT NULL COMMENT “”,
FName STRING,
FNationalityID STRING,
FHeaderUrl STRING,
FStatus STRING,
FLanguage STRING,
FAge STRING,
FSex STRING,
FBirthday STRING,
FExperience STRING,
FCurrency STRING,
FDiamond STRING,
FLevelID STRING,
FSkinID STRING,
FVipID STRING,
FRegisterSource STRING,
FRegisterIP STRING,
FRegisterTime STRING,
FDevice STRING,
FDeviceType STRING,
FDownLoadChannelID STRING,
FIsDeleted STRING,
FModifyTime STRING,
FIsUsed STRING,
FAccountType STRING,
FVipValue STRING,
FIsRecharged STRING,
FPushToken STRING,
FPrettyId STRING,
FDeleteStatus STRING,
database STRING,
table STRING
) ENGINE=olap
PRIMARY KEY(FID)
COMMENT “”
DISTRIBUTED BY HASH(FID) BUCKETS 12
PROPERTIES (
“replication_num” = “3”
);
我的routine load任务语句:
CREATE ROUTINE LOAD job_test_tb1 ON test_tb1
COLUMNS(FID,FName,FNationalityID,FHeaderUrl,FStatus,FLanguage,FAge,FSex,FBirthday,FExperience,FCurrency,FDiamond,FLevelID,FSkinID,FVipID,FRegisterSource,FRegisterIP,FRegisterTime,FDevice,FDeviceType,FDownLoadChannelID,FIsDeleted,FModifyTime,FIsUsed,FAccountType,FVipValue,FIsRecharged,FPushToken,FPrettyId,FDeleteStatus,database,table,temp,__op=(CASE temp WHEN “DELETE” THEN 1 ELSE 0 END)),where database = ‘test_db1’ and table = ‘test_tb1’
PROPERTIES
(
“desired_concurrent_number”=“3”,
“max_batch_interval” = “20”,
“strict_mode” = “false”,
“max_error_number”=“1000”,
“format” = “json”,
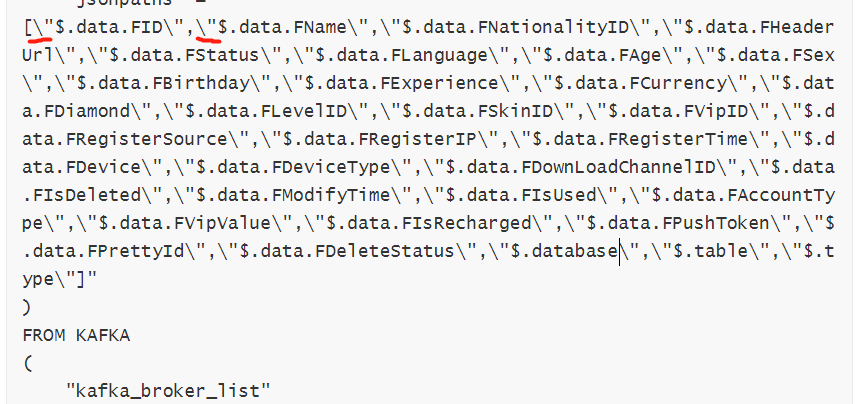
“jsonpaths” = “[”$.data.FID","$.data.FName","$.data.FNationalityID","$.data.FHeaderUrl","$.data.FStatus","$.data.FLanguage","$.data.FAge","$.data.FSex","$.data.FBirthday","$.data.FExperience","$.data.FCurrency","$.data.FDiamond","$.data.FLevelID","$.data.FSkinID","$.data.FVipID","$.data.FRegisterSource","$.data.FRegisterIP","$.data.FRegisterTime","$.data.FDevice","$.data.FDeviceType","$.data.FDownLoadChannelID","$.data.FIsDeleted","$.data.FModifyTime","$.data.FIsUsed","$.data.FAccountType","$.data.FVipValue","$.data.FIsRecharged","$.data.FPushToken","$.data.FPrettyId","$.data.FDeleteStatus","$.database","$.table","$.type"]"
)
FROM KAFKA
(
“kafka_broker_list” =“xxxxxx:9092,xxxxxx:9092,xxxxxxxx:9092”,
“kafka_topic” = “test_binlog_explode”,
“property.group.id” = “SR_test_tb1”,
“property.client.id” = “starrocks-client”,
“property.kafka_default_offsets” = “OFFSET_END”
);
任务运行一段时间后报错,报错信息为:
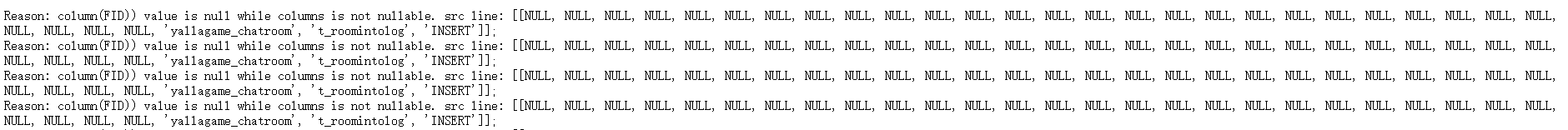
routine load报错信息为:

current error rows is more than max error num,因为我的最大错误条数为1000条,也就是说超过了最大的报错条数。
但是我在routine load任务中设置了where database = ‘test_db1’ and table = ‘test_tb1’,看报错截图的话也就是过滤条件没有生效。把database = yallagame_chatroom, table='t_roomintolog’的数据也导过来了,因为字段不匹配所以所有的字段都变成了null,而FID主键是not null…
所以很疑惑,是过滤条件不应该这样配置吗?