
【详述】
insert into file() 导出 40G 的表时一切正常, 1 分钟左右就可以导出完成
insert into file() 将 300 多 G 的数据导出到 HDFS 卡住了
hdfs 目标目录上有部分数据, 但是不全,
insert into file() 一直运行状态, 直到超时, 期间查看日志无报错
导出到 S3 也遇到同样的问题
(我们用的 oracle 云的对象存储, 支持 S3协议)
经过测试,发现可以通过缩容再扩容的方式, 暂时解决这个问题, 但有时也会卡住
操作过程如下:
- 集群由 5 个 CN 节点, 扩容到 20 个节点, 开始跑批任务.
(等批任务结束后, 此时使用 insert into file() 导出到 hdfs 必然卡住, 每次必复现) - 任务跑完后将集群 CN 节点由 20 台, 缩容到 5 台(剩余的 CN 节点保证 routine load 任务运行)
- 等待 30 分钟(k8s 底层的 node 服务器彻底关闭需要 15 分钟左右)
- 重新将 CN 节点扩容到 20 个,
- 再次执行 insert into file() 导出任务, 数据再 8 分钟左右正常导出完毕
【背景】
【业务影响】
无法导导出大量数据, 类似很多算法需要的基础统计数据
hadoop 版本 3.1.1
【是否存算分离】
是, ON K8S 部署
【StarRocks版本】3.2.8
【集群规模】
3fe(1 follower+2observer)+ (5 ~ 20) CN 扩缩
【机器信息】
16C/64G/万兆
【联系方式】
StarRocks 3.0-存算分离用户群: 可以自然点嘛
【附件】
表结构:
CREATE TABLE `rtb_ml` (
`__d` date NOT NULL COMMENT "",
`ifa` varchar(1048576) NULL COMMENT "",
`media_bundle_array` array<varchar(65533)> NULL COMMENT "",
`make` varchar(1048576) NULL COMMENT "",
`model` varchar(1048576) NULL COMMENT "",
`os_version` varchar(1048576) NULL COMMENT "",
`lang_code` varchar(1048576) NULL COMMENT "",
`region` varchar(1048576) NULL COMMENT "",
`max_rating` decimal(7, 4) NULL COMMENT "",
`min_rating` decimal(7, 4) NULL COMMENT "",
`latest_day` int(11) NULL COMMENT "",
`country` varchar(65533) NULL COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`__d`)
COMMENT "OLAP"
PARTITION BY date_trunc('day', __d)
DISTRIBUTED BY HASH(`ifa`) BUCKETS 100
PROPERTIES (
"replication_num" = "1",
"datacache.enable" = "false",
"storage_volume" = "builtin_storage_volume",
"enable_async_write_back" = "false",
"enable_persistent_index" = "false",
"partition_live_number" = "3",
"compression" = "LZ4"
);
导出语句:
SET session query_timeout=10800;
SET session spill_mode = 'force';
INSERT INTO
FILES(
"path" = "hdfs://adt/apps/starrocks/transfer/rtb_ml/d=20240731/",
"format" = "parquet",
"compression" = "lz4",
"partition_by" = "country",
"target_max_file_size" = "1073741824"
)
SELECT *
from dms.rtb_ml WHERE __d = '20240731';
spill_mode 是否开启, 都是同样的结果
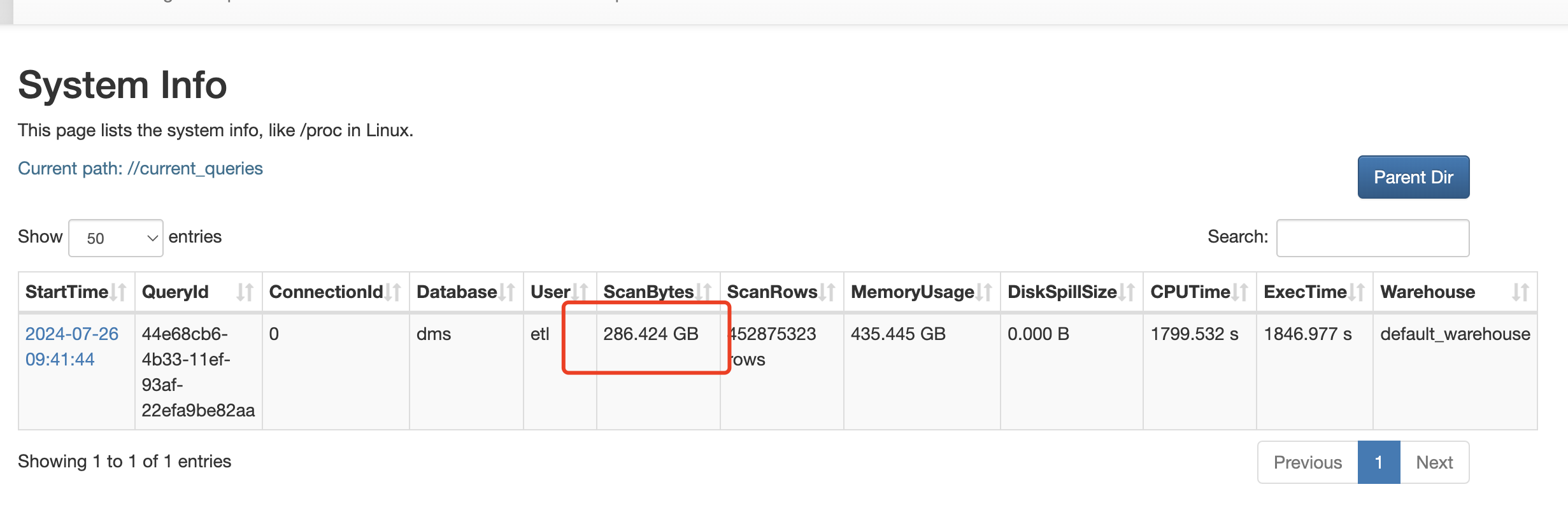
如上图所示, 就卡在这个状态, 不在变化了. 扫描数据量, 行数都不变化, 只有执行时间在增长