
【现象】查询慢,BE 节点的负载不均衡
【数据规模】库数量:80 表数量:几百张 最大表的数据量: 1.5 亿
【应用场景】smartbi 直连查询,帆软 bi 直连查询, 离线跑批SQL任务读写
【主键表】 有大量的主键表,通过 show tablet from 查看不是每个主键表 每个 be节点都有
【背景】扩容 2 个 BE 节点,重启过多次
【业务影响】BI 查询慢
【是否存算分离】否
【StarRocks版本】2.5.13
【集群规模】3fe(2 follower + 1 leader)+ 5be(fe与be混部)
【机器信息】16C/64G/万兆
【联系方式】滴普与StarRocks项目技术支持群 (微信群)
【详情】 见附件文档StarRocks问题汇总.docx (541.7 KB) be_log20240701.tar.gz (74.0 MB)
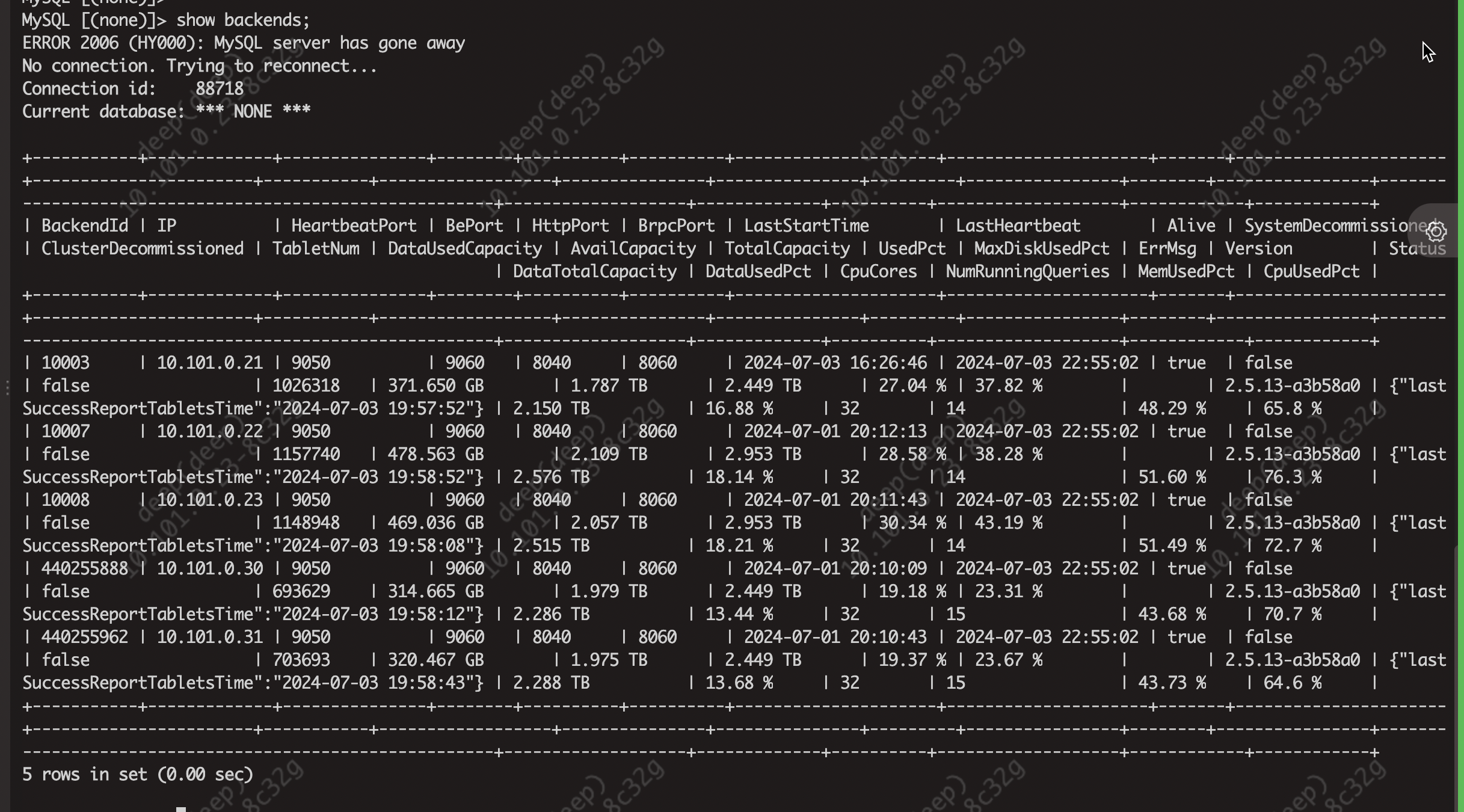
所有的查询都慢吗?麻烦提供下完整的show backends;信息?在mysql客户端直接查询也慢吗?方便提供一下查询慢的profile吗?
所有的查询都慢吗?
不是, 我们有三个 fe 节点,目前发现出现查询慢的时候是连接 fe leader 节点查询慢(稍微复杂点的 sql直接卡住,只有 select 1 这种能返回结果),连接 fe follower 节点能正常查询。
麻烦提供下完整的show backends;信息?
在mysql客户端直接查询也慢吗?
是的, 跟第一个问题一样,也是 MySQL 客户端连接到 follower fe 节点查询正常,连接到 leader 节点查询会卡住。
方便提供一下查询慢的profile吗?
在 web ui 上看不到 profile 内容。

我们的使用场景:
1. smart bi 直连,连接信息填的是 fe 的一个节点地址,我们在出现问题之后重启 sr 服务,如果这个 fe 节点被设置为 leader 节点了,过一天左右就会出现卡住的问题。
2. 另外还有其他平台服务直连,连接信息填的是 三个 fe 地址,用 jdbc 负载均衡的方式连接,因为需要写入数据,所以必须包含 fe leader节点地址。 目前观察也是当 leader 节点卡住之后就不能正常查询了。
目前我们临时的解决办法: 当出现卡住现象之后,重启卡住的那个 fe 节点,这时 leader 节点可能变了,我们又重新调整下 smart bi 的连接地址,目前重启之后大概能维持 1 天左右的时间能正常查询。
leader节点的meta目录所在盘有和其他服务混用吗?麻烦发一下leader节点的fe.log(有出现卡住现象的完整的日志)
如果有配置监控项的话,麻烦再提供下fe jvm监控指标的信息。fe.conf的jvm配置的多大? 参考官网文档在出现查询慢的时候,获取对应的profile。查看分析 Query Profile | StarRocks (mirrorship.cn)
leader节点的fe.gc.log也麻烦您发一下
fe的jvm配置的太小了
目前集群已经有470w的tablet了,按照tablet个数,fe的jvm应该设置在64G
tablet个数和jvm关系:
100w以下16G
100w-200w 32G
200w-500w 64G
500w-1000w 128gG
调整jvm之后再观察下
目前我们环境找不到 gc 日志诶。
fe.conf脱敏发下
我们三台 FE 的内存,每台就 64G,目前我把 JVM 改成 16G 了。
重启之后, gc 日志有了。 我传附件。 fe.gc.log.20240705-113521 (536.6 KB) fe.gc.log.20240705-114233 (64.4 KB) fe.gc.log.20240705-113825 (273.4 KB)
jvm不是最大32吗
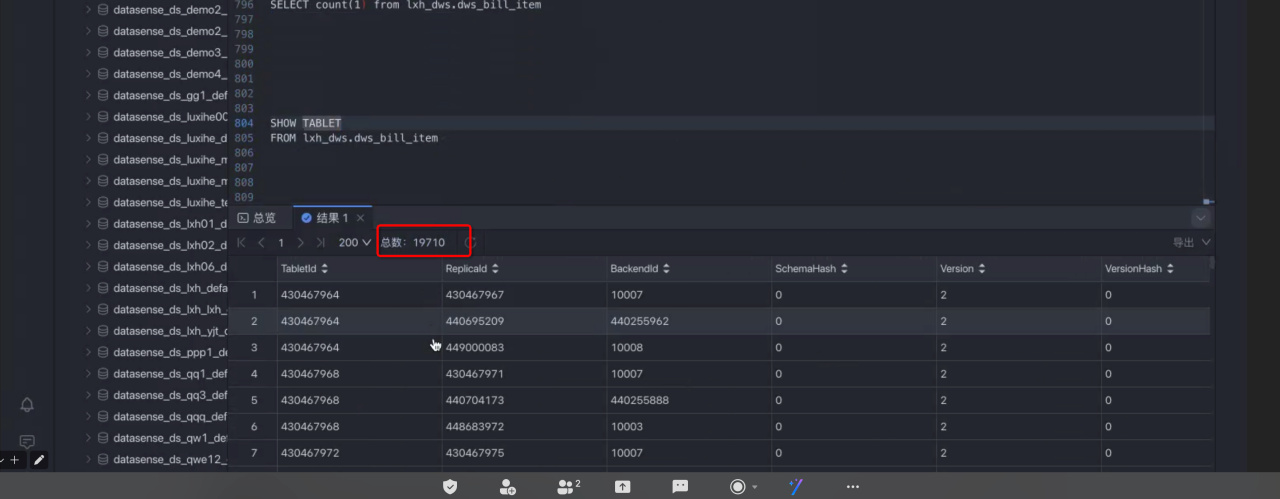
tablet 设置不合理具体是指什么? tablet 数量太多了是吗? 如何让 tablet 数量降下来,有没有更详细一点的操作文档。
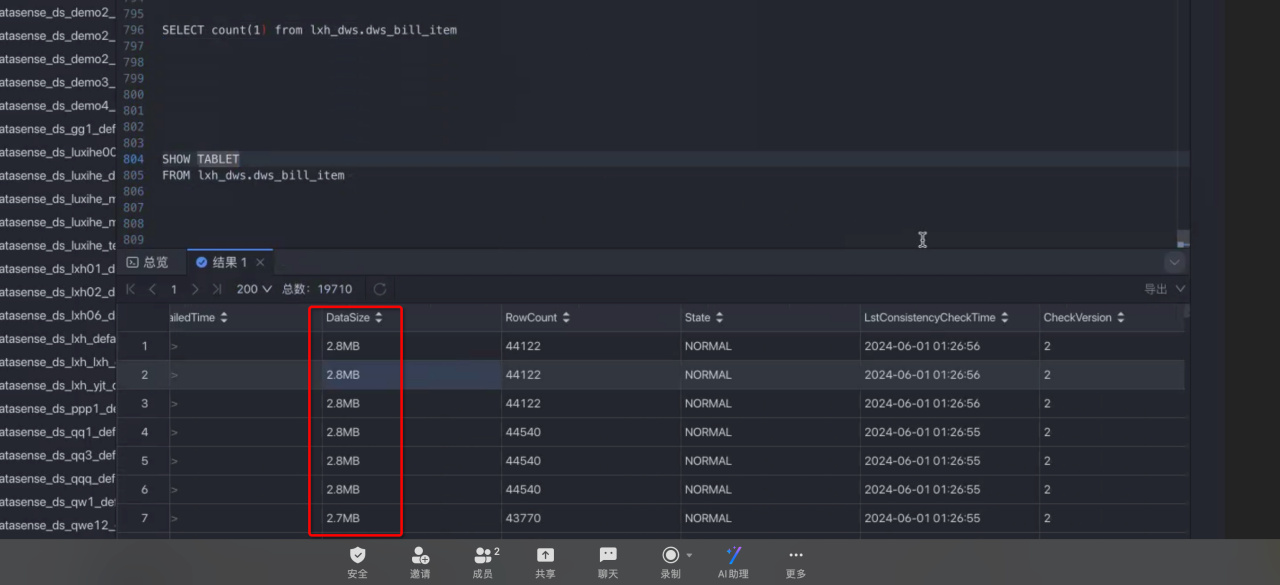
数量太多,就手动设置表的分桶方式,把bucket手动设置,而不是用系统推荐的,建议每个tablet在500M~1G
ALTER TABLE details DISTRIBUTED BY HASH(user_id) BUCKETS 10;
https://docs.mirrorship.cn/zh/docs/sql-reference/sql-statements/data-definition/ALTER_TABLE/你的版本我预计可能不太支持,而且感觉alter bucket num好像在3.2.8版本无效,我修改了bucket ,但是后续导入数据,bucket num还是原来的样子,建议您重新建表,建表时指定bucketNum的数量会比较好,我看你的tablet size都太小了
是 2.5 版本无效?