【详述】使用httpclient进行查询,
sql为selectt * from table where timeId >= ‘xxx’ and timeId < ‘yyy’ order by column1 limit 1000。
【背景】查询数据表为大宽表,380列,背景数据量60亿,表大小9T
【业务影响】sql查询很久之后失败,查看FE日志原因为“ Cancel query [2e20e1bd-321a-11ef-b190-286ed4905829], because some related backend is not alive”,查看对应BE节点日志,并没有相关异常
【是否存算分离】否。存算一体。
【StarRocks版本】3.2.6
【集群规模】例如:3fe(1 follower+2observer)+9be(fe与be混部)
【机器信息】每台机器 32C/136G/万兆/starrocks磁盘1.5T
【联系方式】
【附件】
- fe.log/beINFO/相应截图
2024-06-24 19:33:57.504+08:00 WARN (heartbeat-mgr-pool-3|141) [HeartbeatMgr$BackendHeartbeatHandler.call():325] backend heartbeat got exception, addr: 76.65.27.20:9050
org.apache.thrift.transport.TTransportException: java.net.SocketTimeoutException: Read timed out
at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:127) ~[libthrift-0.13.0.jar:0.13.0]
at org.apache.thrift.transport.TTransport.readAll(TTransport.java:86) ~[libthrift-0.13.0.jar:0.13.0]
at org.apache.thrift.protocol.TBinaryProtocol.readAll(TBinaryProtocol.java:455) ~[libthrift-0.13.0.jar:0.13.0]
at org.apache.thrift.protocol.TBinaryProtocol.readI32(TBinaryProtocol.java:354) ~[libthrift-0.13.0.jar:0.13.0]
at org.apache.thrift.protocol.TBinaryProtocol.readMessageBegin(TBinaryProtocol.java:243) ~[libthrift-0.13.0.jar:0.13.0]
at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:77) ~[libthrift-0.13.0.jar:0.13.0]
at com.starrocks.thrift.HeartbeatService$Client.recv_heartbeat(HeartbeatService.java:61) ~[starrocks-fe.jar:?]
at com.starrocks.thrift.HeartbeatService$Client.heartbeat(HeartbeatService.java:48) ~[starrocks-fe.jar:?]
at com.starrocks.system.HeartbeatMgr$BackendHeartbeatHandler.call(HeartbeatMgr.java:283) ~[starrocks-fe.jar:?]
at com.starrocks.system.HeartbeatMgr$BackendHeartbeatHandler.call(HeartbeatMgr.java:260) ~[starrocks-fe.jar:?]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_382]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_382]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_382]
at java.lang.Thread.run(Thread.java:750) ~[?:1.8.0_382]
Caused by: java.net.SocketTimeoutException: Read timed out
at java.net.SocketInputStream.socketRead0(Native Method) ~[?:1.8.0_382]
at java.net.SocketInputStream.socketRead(SocketInputStream.java:116) ~[?:1.8.0_382]
at java.net.SocketInputStream.read(SocketInputStream.java:171) ~[?:1.8.0_382]
at java.net.SocketInputStream.read(SocketInputStream.java:141) ~[?:1.8.0_382]
at java.io.BufferedInputStream.fill(BufferedInputStream.java:246) ~[?:1.8.0_382]
at java.io.BufferedInputStream.read1(BufferedInputStream.java:286) ~[?:1.8.0_382]
at java.io.BufferedInputStream.read(BufferedInputStream.java:345) ~[?:1.8.0_382]
at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:125) ~[libthrift-0.13.0.jar:0.13.0]
... 13 more
2024-06-24 19:33:57.505+08:00 WARN (heartbeat mgr|26) [HeartbeatMgr.runAfterCatalogReady():166] get bad heartbeat response: type: BACKEND, status: BAD, msg: java.net.SocketTimeoutException: Read timed out
2024-06-24 19:34:02.520+08:00 WARN (heartbeat-mgr-pool-4|142) [HeartbeatMgr$BackendHeartbeatHandler.call():325] backend heartbeat got exception, addr: 76.65.27.20:9050
org.apache.thrift.transport.TTransportException: java.net.SocketTimeoutException: Read timed out
at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:127) ~[libthrift-0.13.0.jar:0.13.0]
at org.apache.thrift.transport.TTransport.readAll(TTransport.java:86) ~[libthrift-0.13.0.jar:0.13.0]
at org.apache.thrift.protocol.TBinaryProtocol.readAll(TBinaryProtocol.java:455) ~[libthrift-0.13.0.jar:0.13.0]
at org.apache.thrift.protocol.TBinaryProtocol.readI32(TBinaryProtocol.java:354) ~[libthrift-0.13.0.jar:0.13.0]
at org.apache.thrift.protocol.TBinaryProtocol.readMessageBegin(TBinaryProtocol.java:243) ~[libthrift-0.13.0.jar:0.13.0]
at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:77) ~[libthrift-0.13.0.jar:0.13.0]
at com.starrocks.thrift.HeartbeatService$Client.recv_heartbeat(HeartbeatService.java:61) ~[starrocks-fe.jar:?]
at com.starrocks.thrift.HeartbeatService$Client.heartbeat(HeartbeatService.java:48) ~[starrocks-fe.jar:?]
at com.starrocks.system.HeartbeatMgr$BackendHeartbeatHandler.call(HeartbeatMgr.java:283) ~[starrocks-fe.jar:?]
at com.starrocks.system.HeartbeatMgr$BackendHeartbeatHandler.call(HeartbeatMgr.java:260) ~[starrocks-fe.jar:?]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_382]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_382]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_382]
at java.lang.Thread.run(Thread.java:750) ~[?:1.8.0_382]
Caused by: java.net.SocketTimeoutException: Read timed out
at java.net.SocketInputStream.socketRead0(Native Method) ~[?:1.8.0_382]
at java.net.SocketInputStream.socketRead(SocketInputStream.java:116) ~[?:1.8.0_382]
at java.net.SocketInputStream.read(SocketInputStream.java:171) ~[?:1.8.0_382]
at java.net.SocketInputStream.read(SocketInputStream.java:141) ~[?:1.8.0_382]
at java.io.BufferedInputStream.fill(BufferedInputStream.java:246) ~[?:1.8.0_382]
at java.io.BufferedInputStream.read1(BufferedInputStream.java:286) ~[?:1.8.0_382]
at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:125) ~[libthrift-0.13.0.jar:0.13.0]
... 13 more
2024-06-24 19:34:02.521+08:00 WARN (heartbeat mgr|26) [HeartbeatMgr.runAfterCatalogReady():166] get bad heartbeat response: type: BACKEND, status: BAD, msg: java.net.SocketTimeoutException: Read timed out
2024-06-24 19:34:02.680+08:00 INFO (tablet scheduler|46) [ClusterLoadStatistic.classifyBackendByLoad():163] classify backend by load. medium: HDD, avg load score: 1.0057171045652251, low/mid/high: 0/9/0
2024-06-24 19:34:02.681+08:00 INFO (tablet scheduler|46) [TabletScheduler.updateClusterLoadStatistic():484] update cluster load statistic:
{"beId":23495,"clusterName":"default_cluster","isAvailable":true,"cpuCores":32,"memLimit":38654705664,"memUsed":22417056800,"mediums":[{"medium":"HDD","replica":430,"used":1189313450577,"total":"1.4TB","score":0.9674601428499784},{"medium":"SSD","replica":0,"used":0,"total":"0B","score":NaN}],"paths":[{"beId":23495,"path":"/dbdata/hdfs/starrocks","pathHash":-911221383916378900,"storageMedium":"HDD","total":1581055930961,"used":1189313450577}]}
{"beId":23489,"clusterName":"default_cluster","isAvailable":true,"cpuCores":32,"memLimit":38654705664,"memUsed":23713332576,"mediums":[{"medium":"HDD","replica":434,"used":1199676189667,"total":"1.4TB","score":0.9715428010530057},{"medium":"SSD","replica":0,"used":0,"total":"0B","score":NaN}],"paths":[{"beId":23489,"path":"/dbdata/hdfs/starrocks","pathHash":-6347946421233345028,"storageMedium":"HDD","total":1586567633891,"used":1199676189667}]}
{"beId":23493,"clusterName":"default_cluster","isAvailable":true,"cpuCores":32,"memLimit":38654705664,"memUsed":23398619264,"mediums":[{"medium":"HDD","replica":431,"used":1195971714606,"total":"1.4TB","score":0.974530696854858},{"medium":"SSD","replica":0,"used":0,"total":"0B","score":NaN}],"paths":[{"beId":23493,"path":"/dbdata/hdfs/starrocks","pathHash":5387200276665703296,"storageMedium":"HDD","total":1576109014574,"used":1195971714606}]}
{"beId":23490,"clusterName":"default_cluster","isAvailable":true,"cpuCores":32,"memLimit":38654705664,"memUsed":23011640832,"mediums":[{"medium":"HDD","replica":435,"used":1197950818072,"total":"1.4TB","score":0.9751407862225633},{"medium":"SSD","replica":0,"used":0,"total":"0B","score":NaN}],"paths":[{"beId":23490,"path":"/dbdata/hdfs/starrocks","pathHash":2669929127906401838,"storageMedium":"HDD","total":1577193056024,"used":1197950818072}]}
{"beId":23492,"clusterName":"default_cluster","isAvailable":true,"cpuCores":32,"memLimit":38654705664,"memUsed":23766838336,"mediums":[{"medium":"HDD","replica":435,"used":1201273132516,"total":"1.4TB","score":0.979292759654694},{"medium":"SSD","replica":0,"used":0,"total":"0B","score":NaN}],"paths":[{"beId":23492,"path":"/dbdata/hdfs/starrocks","pathHash":1523735257628543257,"storageMedium":"HDD","total":1573644592612,"used":1201273132516}]}
{"beId":23491,"clusterName":"default_cluster","isAvailable":true,"cpuCores":32,"memLimit":38654705664,"memUsed":23679839840,"mediums":[{"medium":"HDD","replica":442,"used":1219597649906,"total":"1.4TB","score":0.986342000340271},{"medium":"SSD","replica":0,"used":0,"total":"0B","score":NaN}],"paths":[{"beId":23491,"path":"/dbdata/hdfs/starrocks","pathHash":-615129396628447825,"storageMedium":"HDD","total":1583185278962,"used":1219597649906}]}
{"beId":23494,"clusterName":"default_cluster","isAvailable":true,"cpuCores":32,"memLimit":38654705664,"memUsed":20310327968,"mediums":[{"medium":"HDD","replica":320,"used":865581422539,"total":"983.9GB","score":1.0542333234625618},{"medium":"SSD","replica":0,"used":0,"total":"0B","score":NaN}],"paths":[{"beId":23494,"path":"/dbdata/hdfs/starrocks","pathHash":-4050302138593708488,"storageMedium":"HDD","total":1056535685067,"used":865581422539}]}
{"beId":23487,"clusterName":"default_cluster","isAvailable":true,"cpuCores":32,"memLimit":38654705664,"memUsed":19829017552,"mediums":[{"medium":"HDD","replica":323,"used":873363533123,"total":"982.3GB","score":1.06552414916916},{"medium":"SSD","replica":0,"used":0,"total":"0B","score":NaN}],"paths":[{"beId":23487,"path":"/dbdata/hdfs/starrocks","pathHash":5928258772759042216,"storageMedium":"HDD","total":1054738357571,"used":873363533123}]}
{"beId":23488,"clusterName":"default_cluster","isAvailable":true,"cpuCores":32,"memLimit":38654705664,"memUsed":20284573992,"mediums":[{"medium":"HDD","replica":325,"used":881494411568,"total":"980.5GB","score":1.0773872814799335},{"medium":"SSD","replica":0,"used":0,"total":"0B","score":NaN}],"paths":[{"beId":23488,"path":"/dbdata/hdfs/starrocks","pathHash":68600672985287524,"storageMedium":"HDD","total":1052835940656,"used":881494411568}]}
2024-06-24 19:34:07.219+08:00 INFO (colocate group clone checker|111) [ColocateTableBalancer.matchGroups():903] finished to match colocate group. cost: 0 ms, in lock time: 0 ms
2024-06-24 19:34:07.261+08:00 INFO (AutoStatistic|38) [StatisticAutoCollector.runAfterCatalogReady():70] auto collect full statistic on all databases start
2024-06-24 19:34:07.262+08:00 INFO (AutoStatistic|38) [StatisticAutoCollector.runAfterCatalogReady():88] auto collect full statistic on all databases end
2024-06-24 19:34:07.532+08:00 WARN (heartbeat-mgr-pool-6|144) [HeartbeatMgr$BackendHeartbeatHandler.call():325] backend heartbeat got exception, addr: 76.65.27.20:9050
org.apache.thrift.transport.TTransportException: java.net.SocketTimeoutException: Read timed out
at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:127) ~[libthrift-0.13.0.jar:0.13.0]
at org.apache.thrift.transport.TTransport.readAll(TTransport.java:86) ~[libthrift-0.13.0.jar:0.13.0]
at org.apache.thrift.protocol.TBinaryProtocol.readAll(TBinaryProtocol.java:455) ~[libthrift-0.13.0.jar:0.13.0]
at org.apache.thrift.protocol.TBinaryProtocol.readI32(TBinaryProtocol.java:354) ~[libthrift-0.13.0.jar:0.13.0]
at org.apache.thrift.protocol.TBinaryProtocol.readMessageBegin(TBinaryProtocol.java:243) ~[libthrift-0.13.0.jar:0.13.0]
at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:77) ~[libthrift-0.13.0.jar:0.13.0]
at com.starrocks.thrift.HeartbeatService$Client.recv_heartbeat(HeartbeatService.java:61) ~[starrocks-fe.jar:?]
at com.starrocks.thrift.HeartbeatService$Client.heartbeat(HeartbeatService.java:48) ~[starrocks-fe.jar:?]
at com.starrocks.system.HeartbeatMgr$BackendHeartbeatHandler.call(HeartbeatMgr.java:283) ~[starrocks-fe.jar:?]
at com.starrocks.system.HeartbeatMgr$BackendHeartbeatHandler.call(HeartbeatMgr.java:260) ~[starrocks-fe.jar:?]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_382]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_382]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_382]
at java.lang.Thread.run(Thread.java:750) ~[?:1.8.0_382]
Caused by: java.net.SocketTimeoutException: Read timed out
at java.net.SocketInputStream.socketRead0(Native Method) ~[?:1.8.0_382]
at java.net.SocketInputStream.socketRead(SocketInputStream.java:116) ~[?:1.8.0_382]
at java.net.SocketInputStream.read(SocketInputStream.java:171) ~[?:1.8.0_382]
at java.net.SocketInputStream.read(SocketInputStream.java:141) ~[?:1.8.0_382]
at java.io.BufferedInputStream.fill(BufferedInputStream.java:246) ~[?:1.8.0_382]
at java.io.BufferedInputStream.read1(BufferedInputStream.java:286) ~[?:1.8.0_382]
at java.io.BufferedInputStream.read(BufferedInputStream.java:345) ~[?:1.8.0_382]
at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:125) ~[libthrift-0.13.0.jar:0.13.0]
... 13 more
2024-06-24 19:34:07.533+08:00 WARN (heartbeat mgr|26) [HeartbeatMgr.runAfterCatalogReady():166] get bad heartbeat response: type: BACKEND, status: BAD, msg: java.net.SocketTimeoutException: Read timed out
2024-06-24 19:34:07.533+08:00 INFO (heartbeat mgr|26) [ComputeNode.handleHbResponse():549] Backend [id=23493, host=76.65.27.20, heartbeatPort=9050, alive=false] is dead due to exceed heartbeatRetryTimes
2024-06-24 19:34:07.533+08:00 INFO (heartbeat mgr|26) [CoordinatorMonitor.addDeadBackend():57] add backend 23493 to dead backend queue
2024-06-24 19:34:07.535+08:00 WARN (Thread-55|101) [CoordinatorMonitor$DeadBackendAndComputeNodeChecker.run():91] Cancel query [2e20e1bd-321a-11ef-b190-286ed4905829], because some related backend is not alive
2024-06-24 19:34:07.535+08:00 WARN (Thread-55|101) [DefaultCoordinator.cancel():809] cancel execState of query, this is outside invoke
2024-06-24 19:34:07.540+08:00 INFO (Thread-55|101) [QueryRuntimeProfile.finishAllInstances():212] unfinished instances: [2e20e1bd-321a-11ef-b190-286ed490582e, 2e20e1bd-321a-11ef-b190-286ed4905831, 2e20e1bd-321a-11ef-b190-286ed4905830, 2e20e1bd-321a-11ef-b190-286ed4905833, 2e20e1bd-321a-11ef-b190-286ed4905832, 2e20e1bd-321a-11ef-b190-286ed490582b, 2e20e1bd-321a-11ef-b190-286ed490582a, 2e20e1bd-321a-11ef-b190-286ed490582d, 2e20e1bd-321a-11ef-b190-286ed490582c, 2e20e1bd-321a-11ef-b190-286ed490582f]
2024-06-24 19:34:07.540+08:00 INFO (Thread-55|101) [DefaultCoordinator.cancel():817] count down profileDoneSignal since backend has crashed, query id: 2e20e1bd-321a-11ef-b190-286ed4905829
2024-06-24 19:34:07.554+08:00 WARN (starrocks-http-nio-pool-0|310) [DefaultCoordinator.getNext():739] get next fail, need cancel. status errorCode CANCELLED InternalError, query id: 2e20e1bd-321a-11ef-b190-286ed4905829
2024-06-24 19:34:07.554+08:00 WARN (thrift-server-pool-25|252) [DefaultCoordinator.updateFragmentExecStatus():898] exec state report failed status=errorCode CANCELLED InternalError, query_id=2e20e1bd-321a-11ef-b190-286ed4905829, instance_id=2e20e1bd-321a-11ef-b190-286ed490582a, backend_id=23488
2024-06-24 19:34:07.554+08:00 WARN (starrocks-http-nio-pool-0|310) [DefaultCoordinator.getNext():765] query failed: Backend node not found. Check if any backend node is down.
2024-06-24 19:34:07.588+08:00 INFO (starrocks-http-nio-pool-0|310) [StmtExecutor.execute():698] execute Exception, sql: select * from tbl_data_res_2080_15 where timeId>='2024-06-18 00:00:00' and timeId<'2024-06-19 00:00:00' order by r2080_i10005 desc limit 1000, error: Backend node not found. Check if any backend node is down.
2024-06-24 19:34:07.589+08:00 INFO (starrocks-http-nio-pool-0|310) [QueryRuntimeProfile.finishAllInstances():212] unfinished instances: [2e20e1bd-321a-11ef-b190-286ed490582e, 2e20e1bd-321a-11ef-b190-286ed4905831, 2e20e1bd-321a-11ef-b190-286ed4905830, 2e20e1bd-321a-11ef-b190-286ed4905833, 2e20e1bd-321a-11ef-b190-286ed4905832, 2e20e1bd-321a-11ef-b190-286ed490582b, 2e20e1bd-321a-11ef-b190-286ed490582d, 2e20e1bd-321a-11ef-b190-286ed490582c, 2e20e1bd-321a-11ef-b190-286ed490582f]
2024-06-24 19:34:07.589+08:00 INFO (starrocks-http-nio-pool-0|310) [DefaultCoordinator.cancel():817] count down profileDoneSignal since backend has crashed, query id: 2e20e1bd-321a-11ef-b190-286ed4905829
2024-06-24 19:34:07.589+08:00 INFO (starrocks-http-nio-pool-0|310) [ResourceGroupMetricMgr.createQueryResourceGroupMetrics():123] Add query_resource_group_err metric, resource group name is default_wg
2024-06-24 19:34:07.591+08:00 INFO (nioEventLoopGroup-8-3|309) [ExecuteSqlAction.handleChannelInactive():250] Netty channel is closed
2024-06-24 19:34:07.591+08:00 INFO (nioEventLoopGroup-8-3|309) [ConnectScheduler.unregisterConnection():155] Connection closed. remote=, connectionId=1
2024-06-24 19:34:07.601+08:00 INFO (profile-worker-0|253) [QeProcessorImpl.unregisterQuery():150] deregister query id = 2e20e1bd-321a-11ef-b190-286ed4905829
2024-06-24 19:34:07.719+08:00 INFO (thrift-server-pool-77|379) [QeProcessorImpl.reportExecStatus():191] ReportExecStatus() failed, query does not exist, fragment_instance_id=2e20e1bd-321a-11ef-b190-286ed490582b, query_id=2e20e1bd-321a-11ef-b190-286ed4905829,
2024-06-24 19:34:07.721+08:00 INFO (thrift-server-pool-33|265) [QeProcessorImpl.reportExecStatus():191] ReportExecStatus() failed, query does not exist, fragment_instance_id=2e20e1bd-321a-11ef-b190-286ed4905833, query_id=2e20e1bd-321a-11ef-b190-286ed4905829,
2024-06-24 19:34:07.744+08:00 INFO (tablet checker|47) [TabletChecker.doCheck():426] finished to check tablets. isUrgent: true, unhealthy/total/added/in_sched/not_ready: 0/0/0/0/0, cost: 0 ms, in lock time: 0 ms, wait time: 0ms
2024-06-24 19:34:07.756+08:00 INFO (thrift-server-pool-49|283) [QeProcessorImpl.reportExecStatus():191] ReportExecStatus() failed, query does not exist, fragment_instance_id=2e20e1bd-321a-11ef-b190-286ed490582d, query_id=2e20e1bd-321a-11ef-b190-286ed4905829,
2024-06-24 19:34:07.757+08:00 INFO (tablet checker|47) [TabletChecker.doCheck():426] finished to check tablets. isUrgent: false, unhealthy/total/added/in_sched/not_ready: 8/2618/0/0/0, cost: 12 ms, in lock time: 12 ms, wait time: 0ms
- 慢查询:
- Profile信息
- 并行度:2
- pipeline是否开启:true
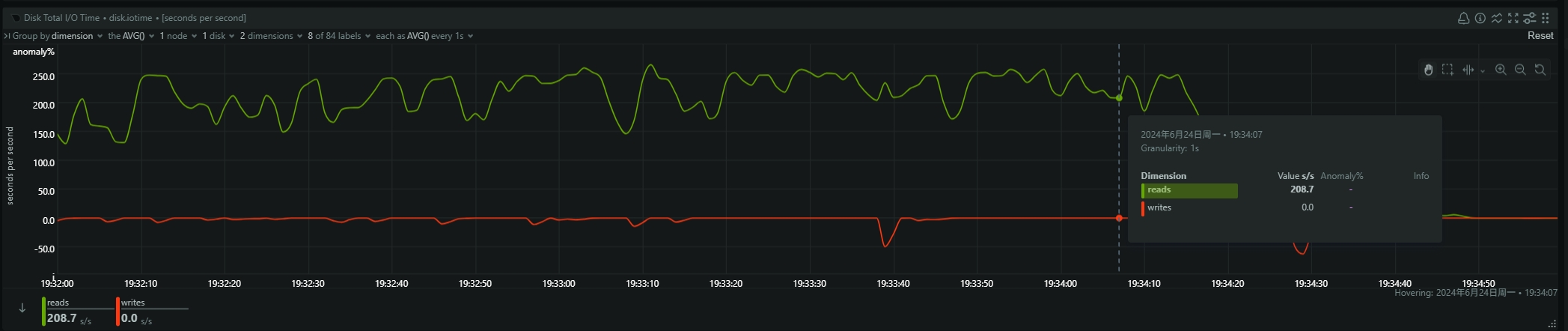
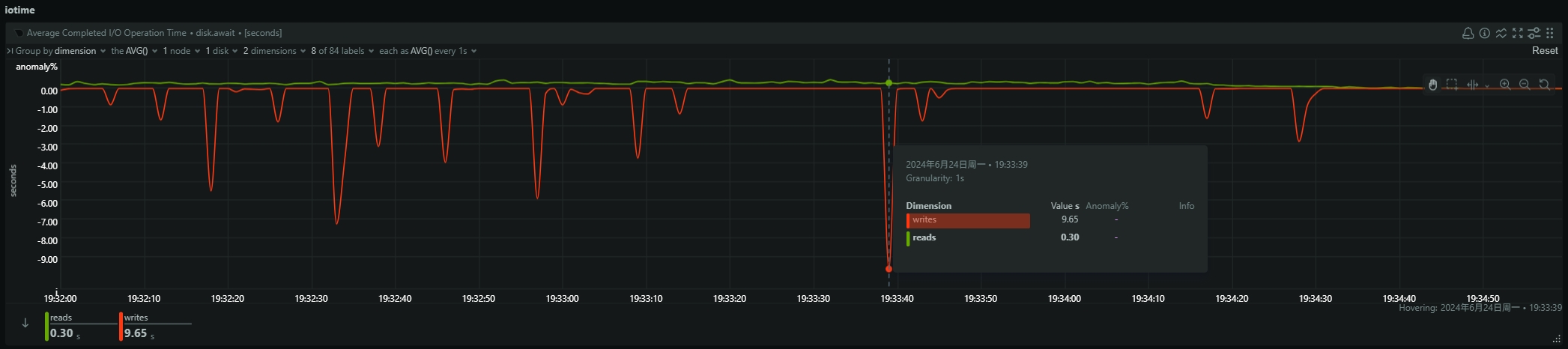
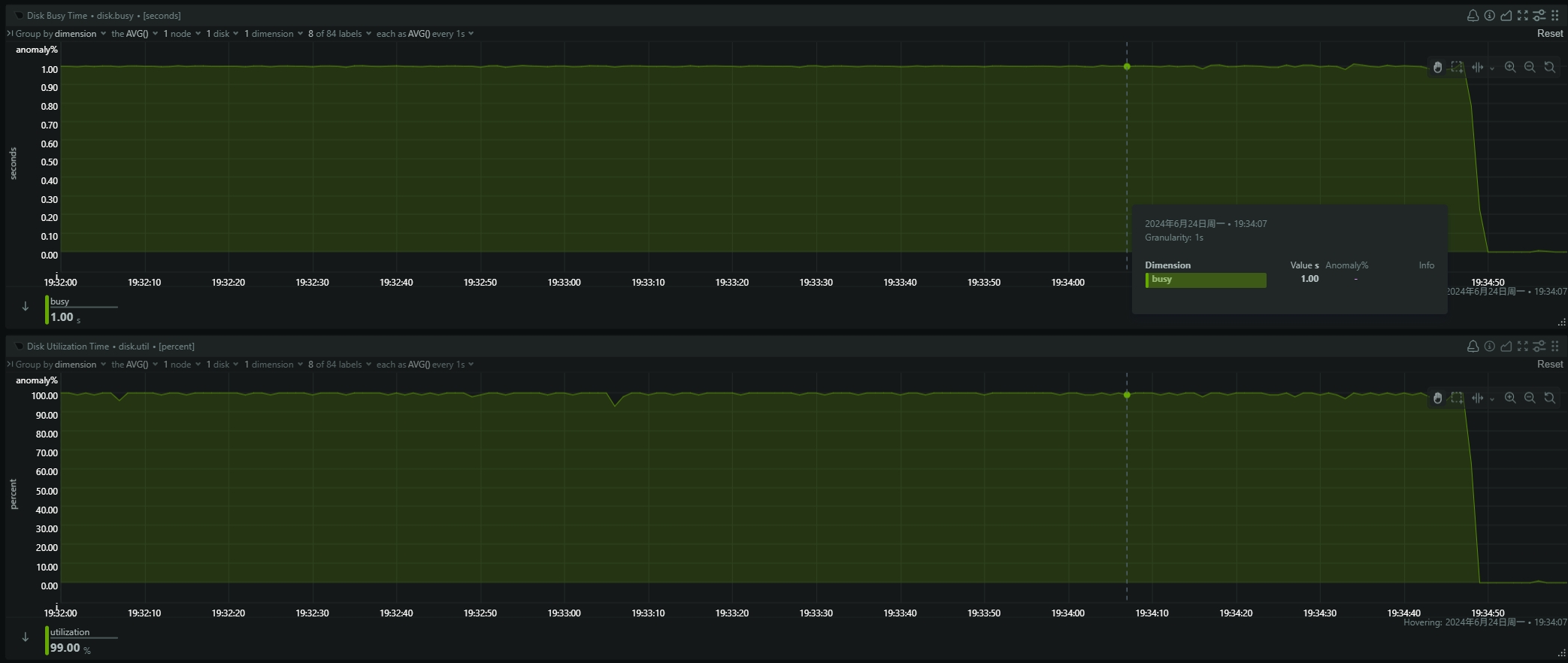
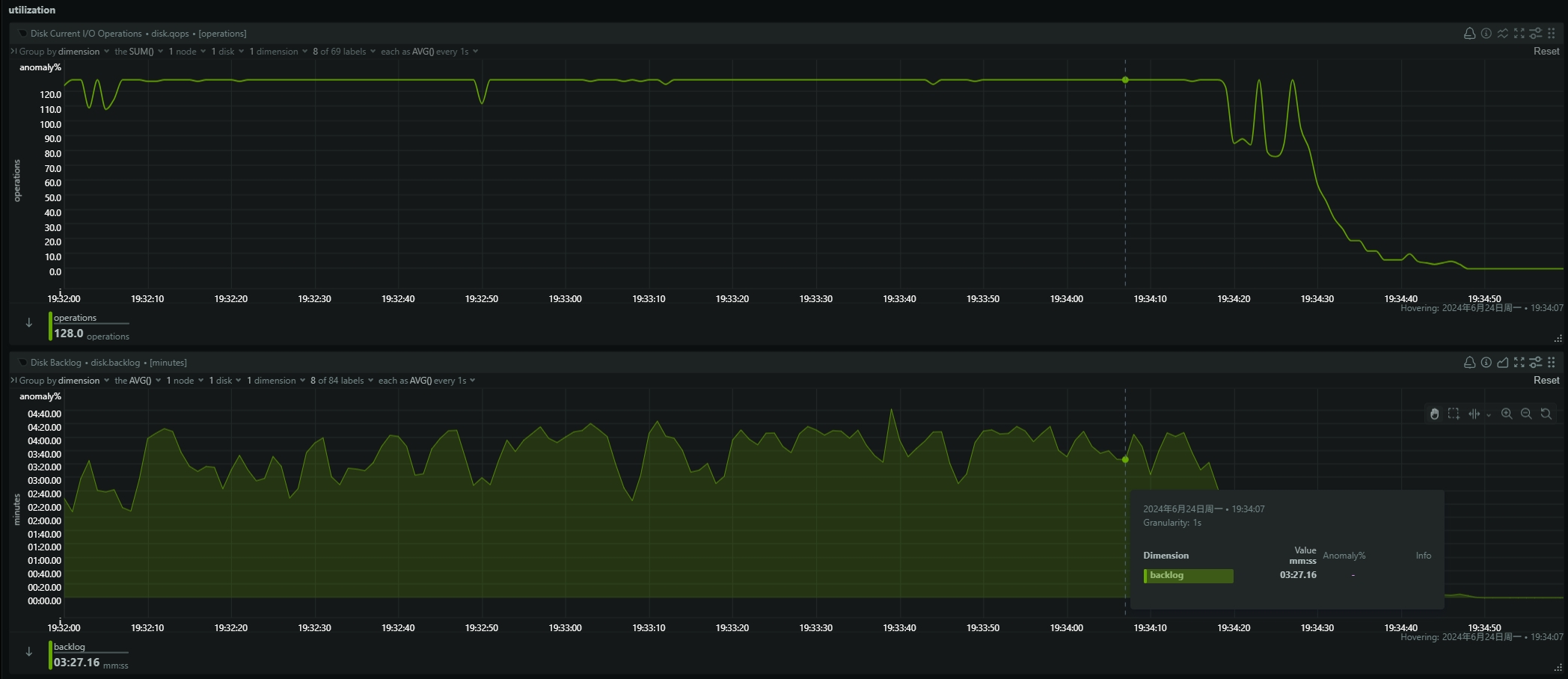
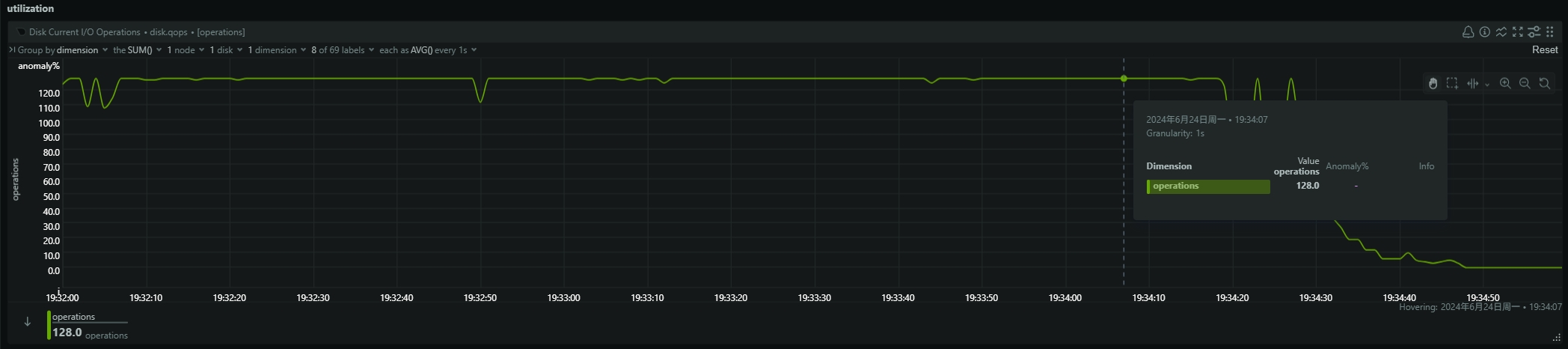
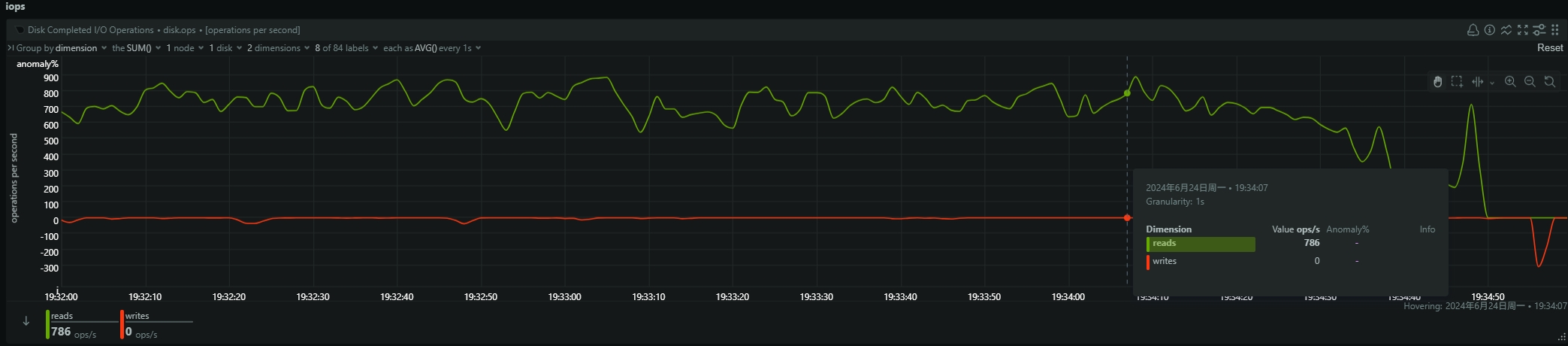
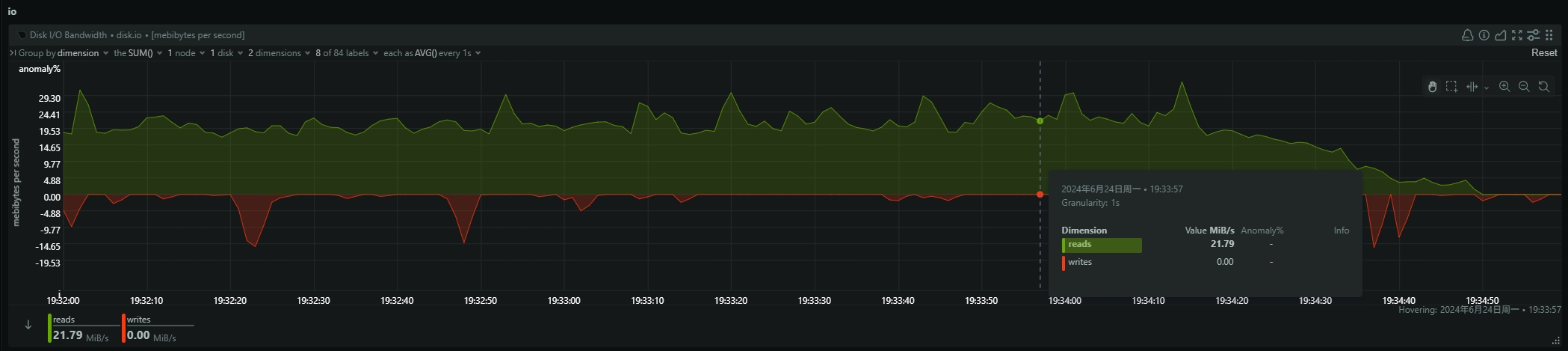
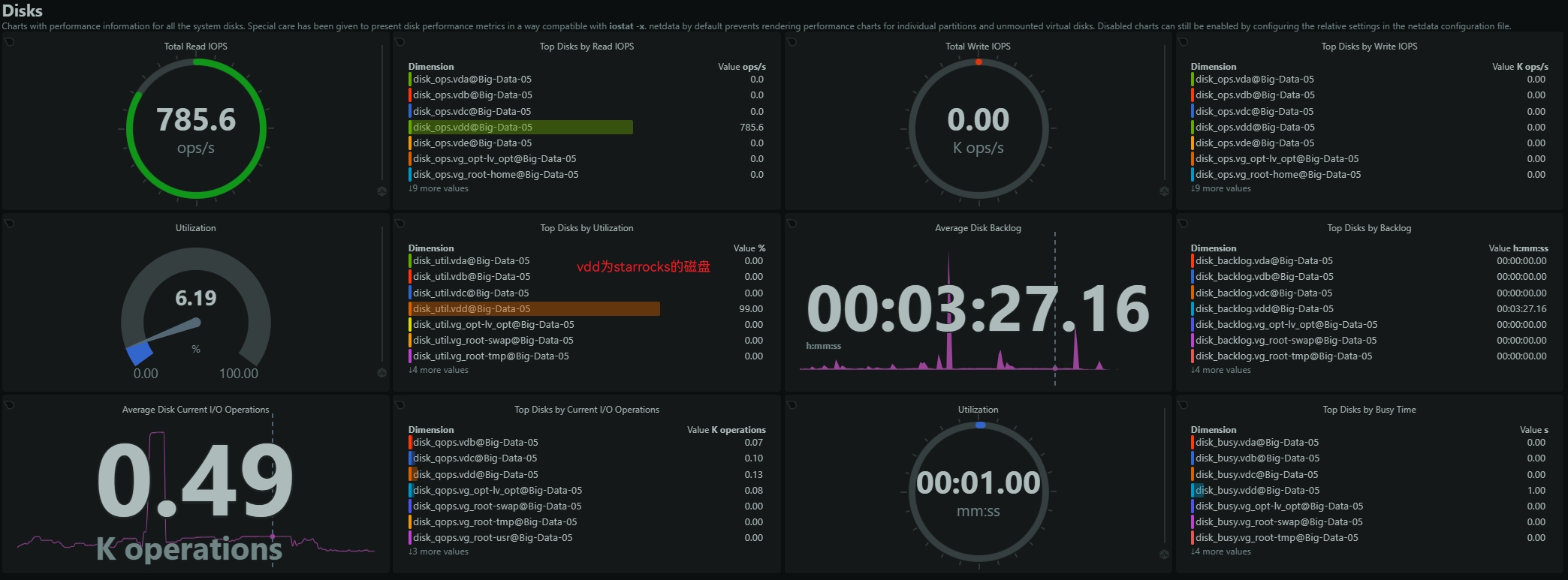
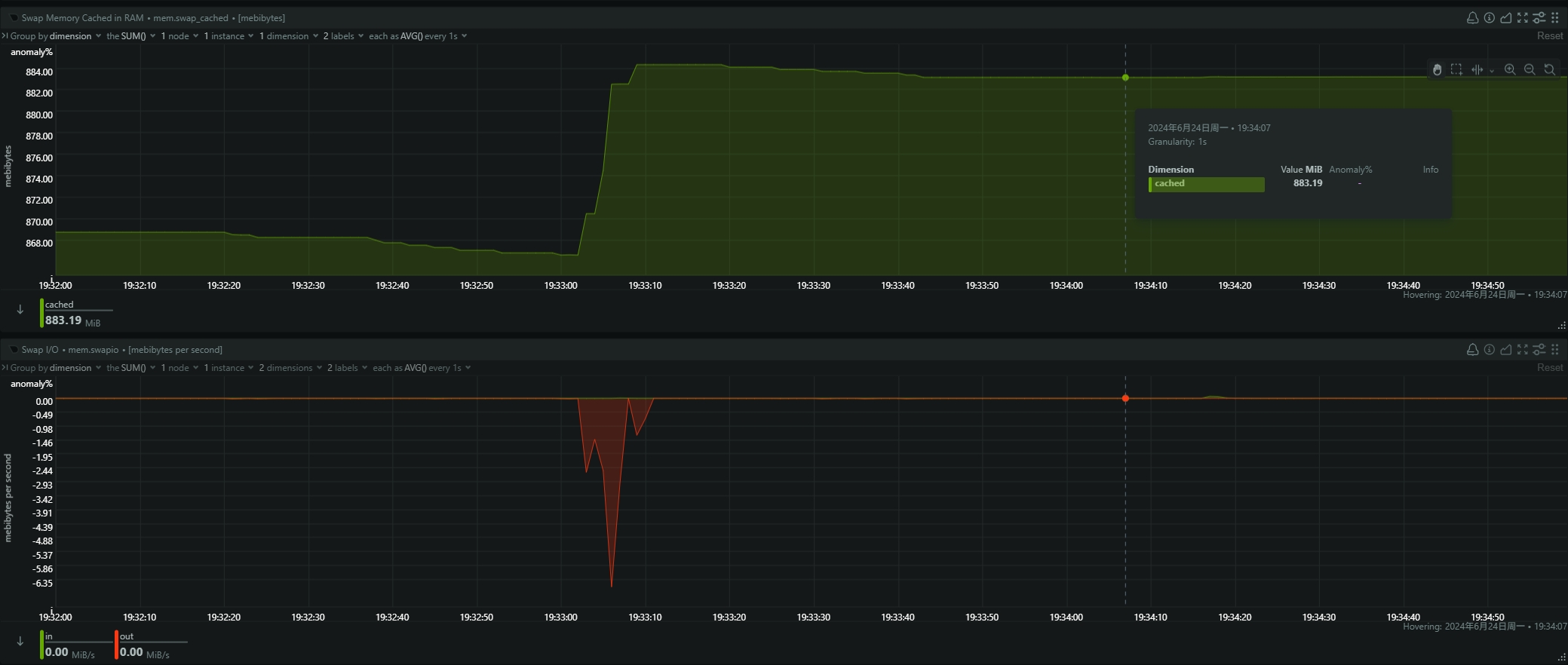
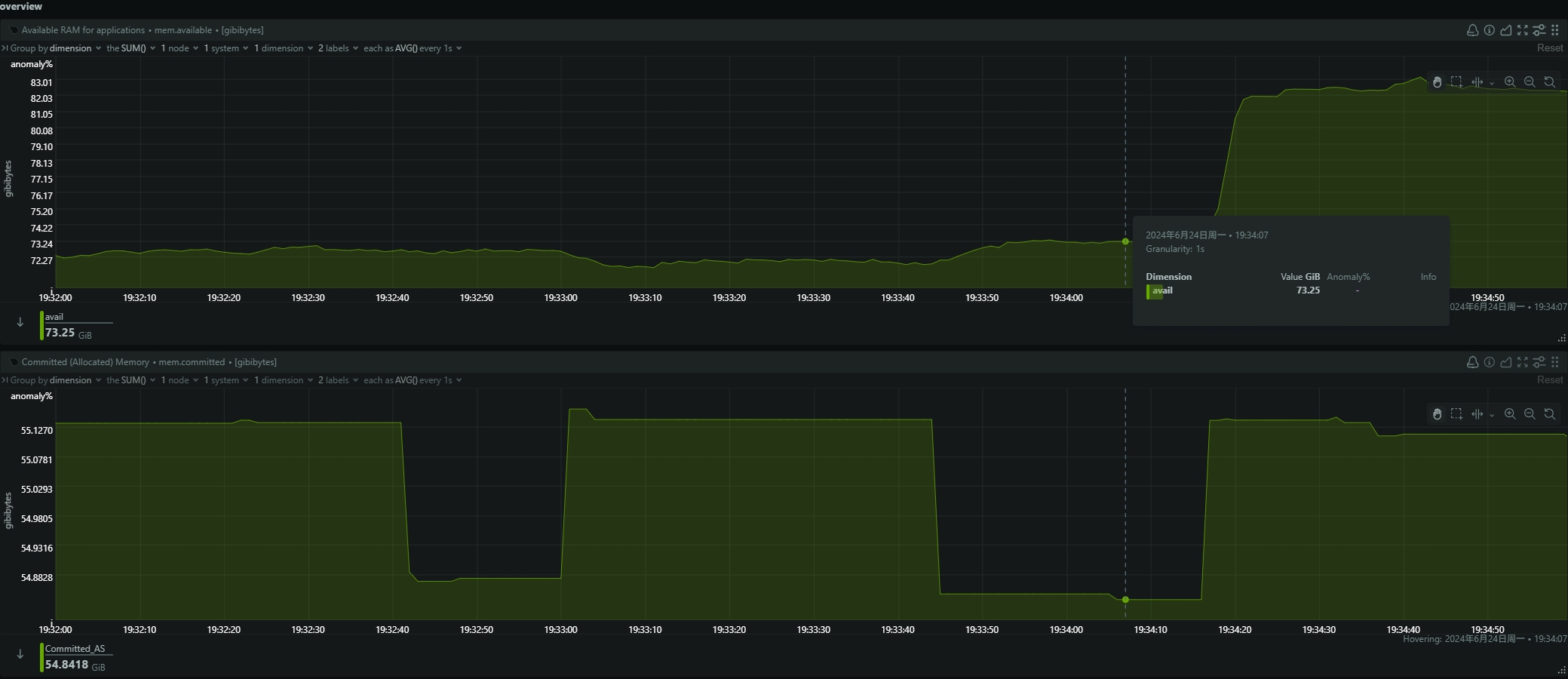
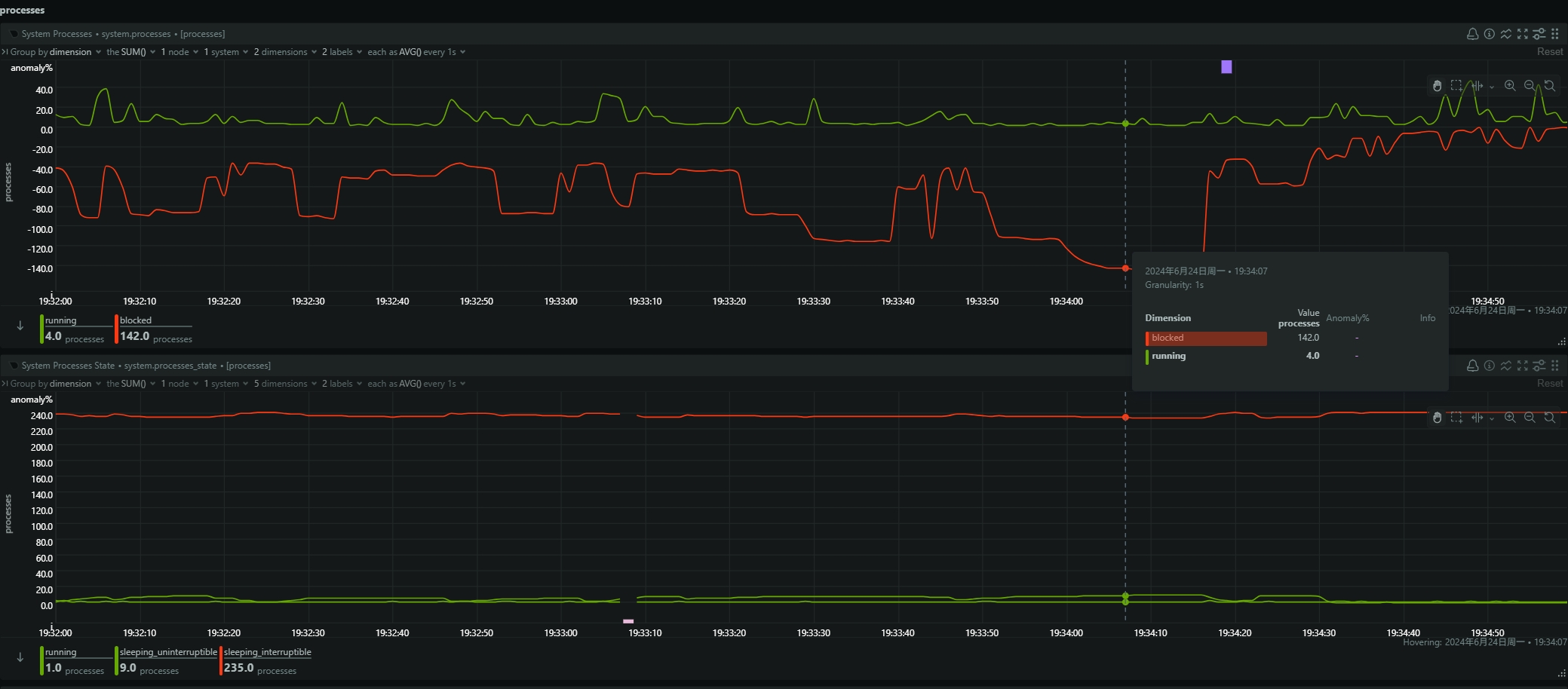
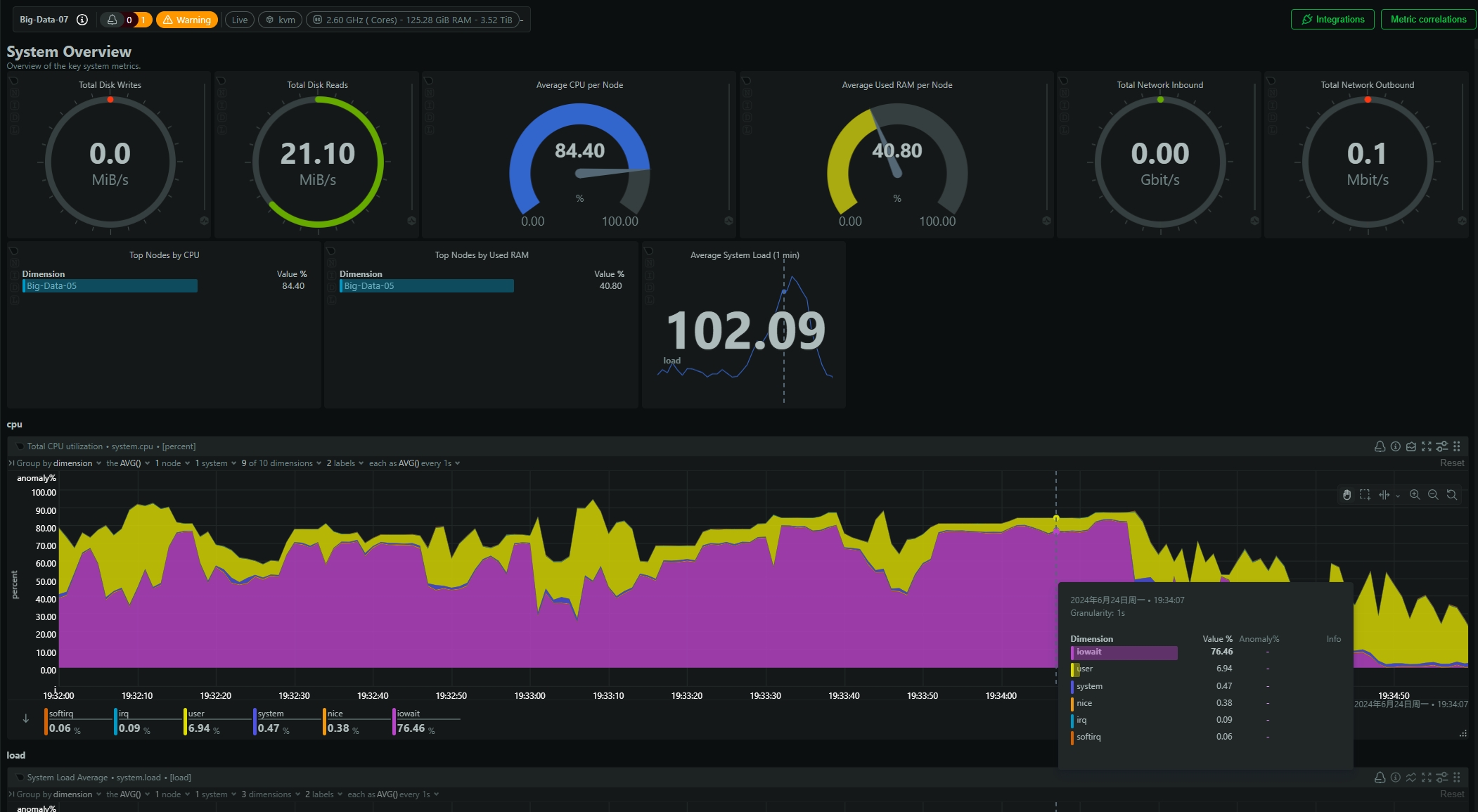
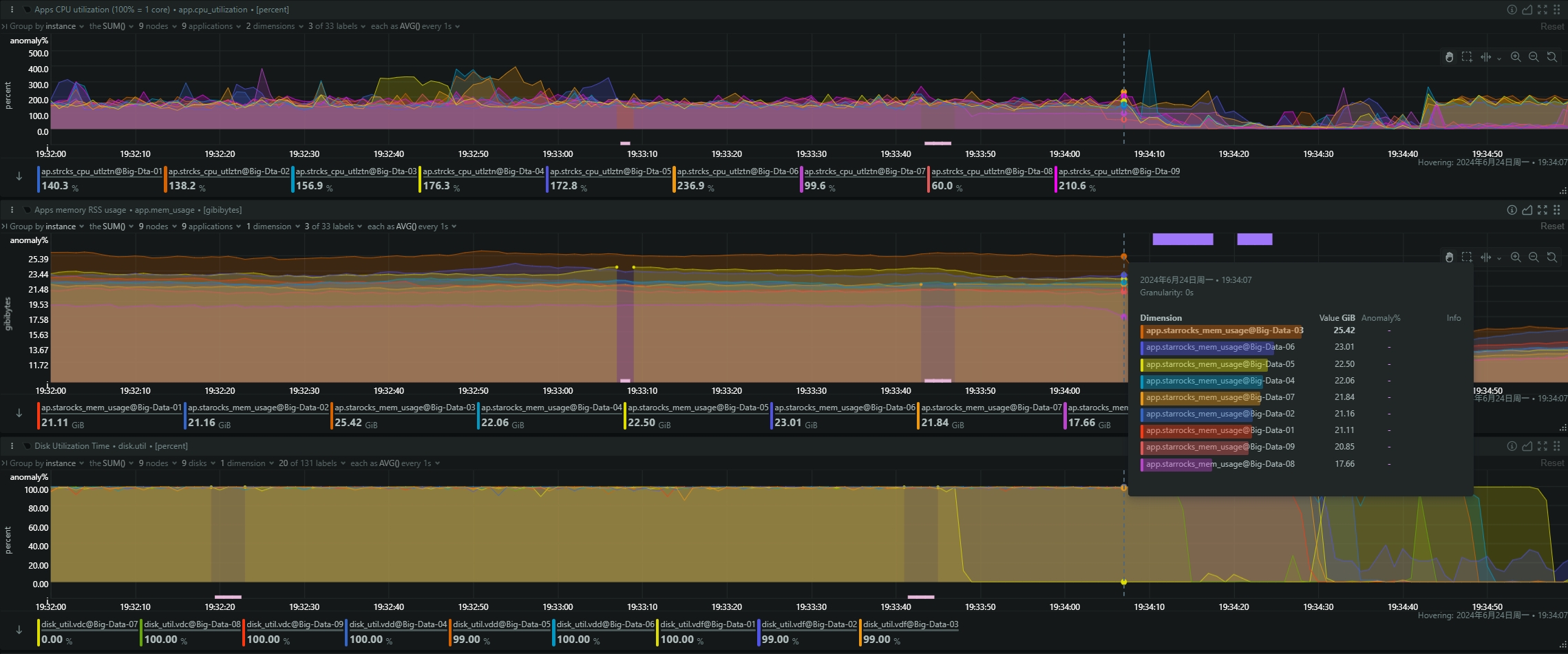
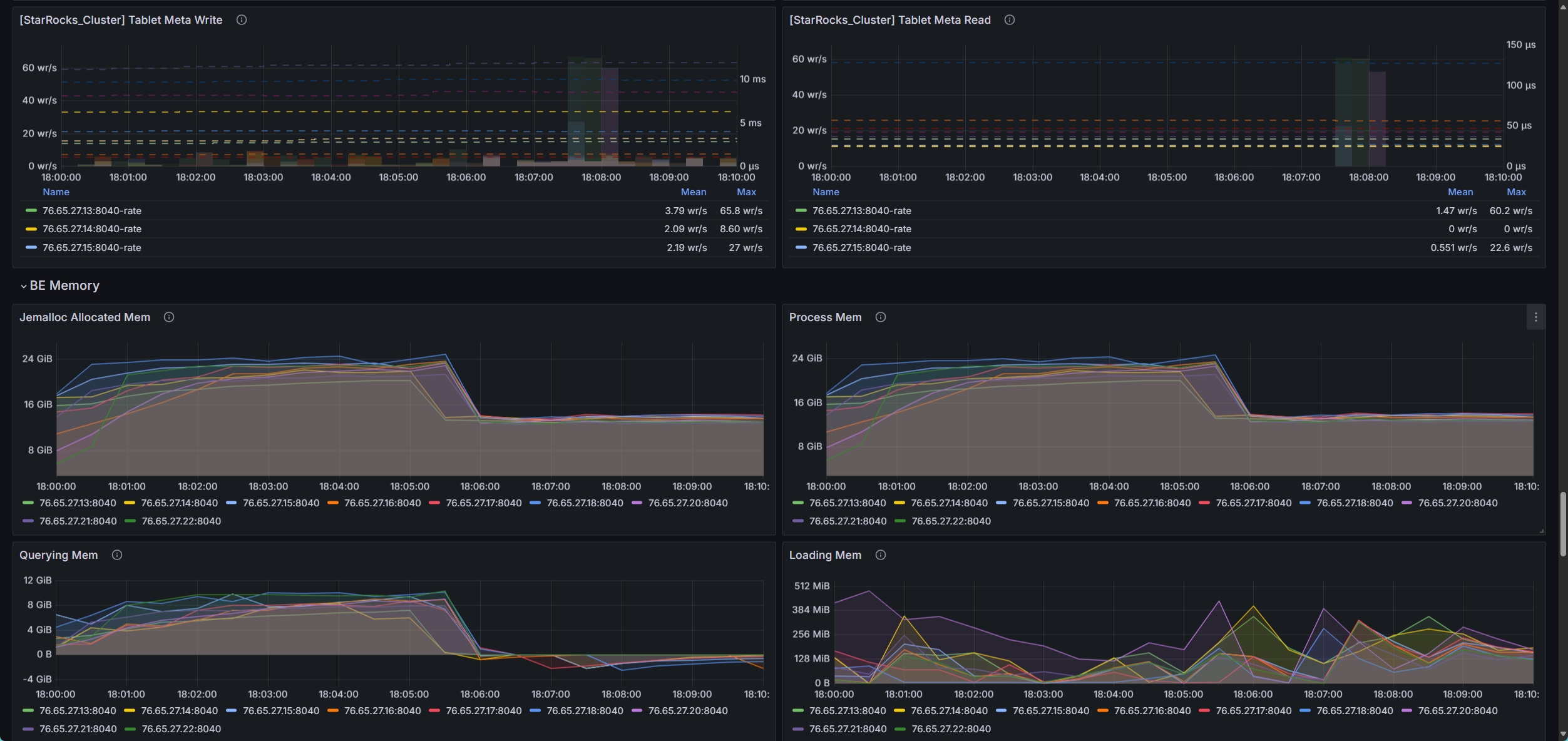
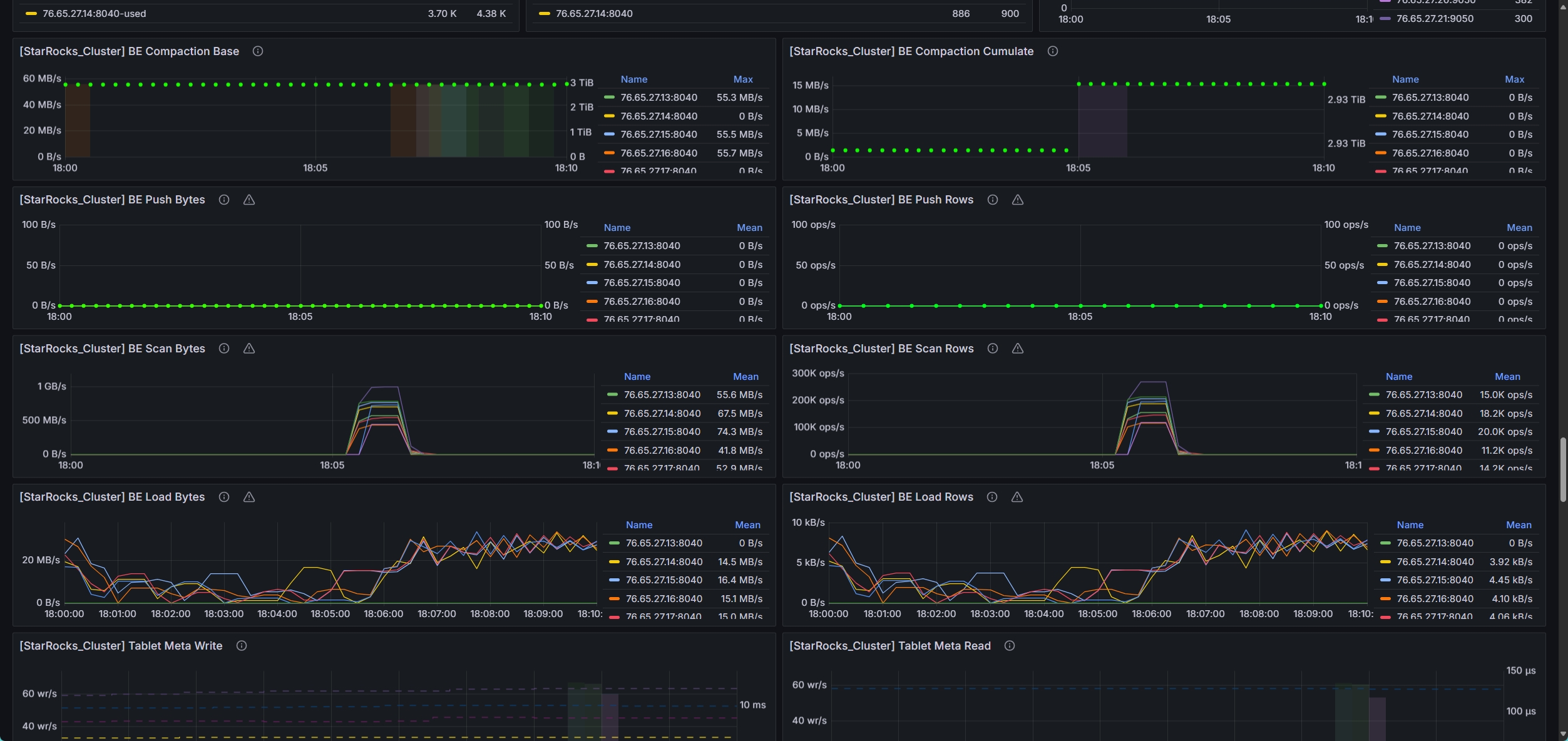
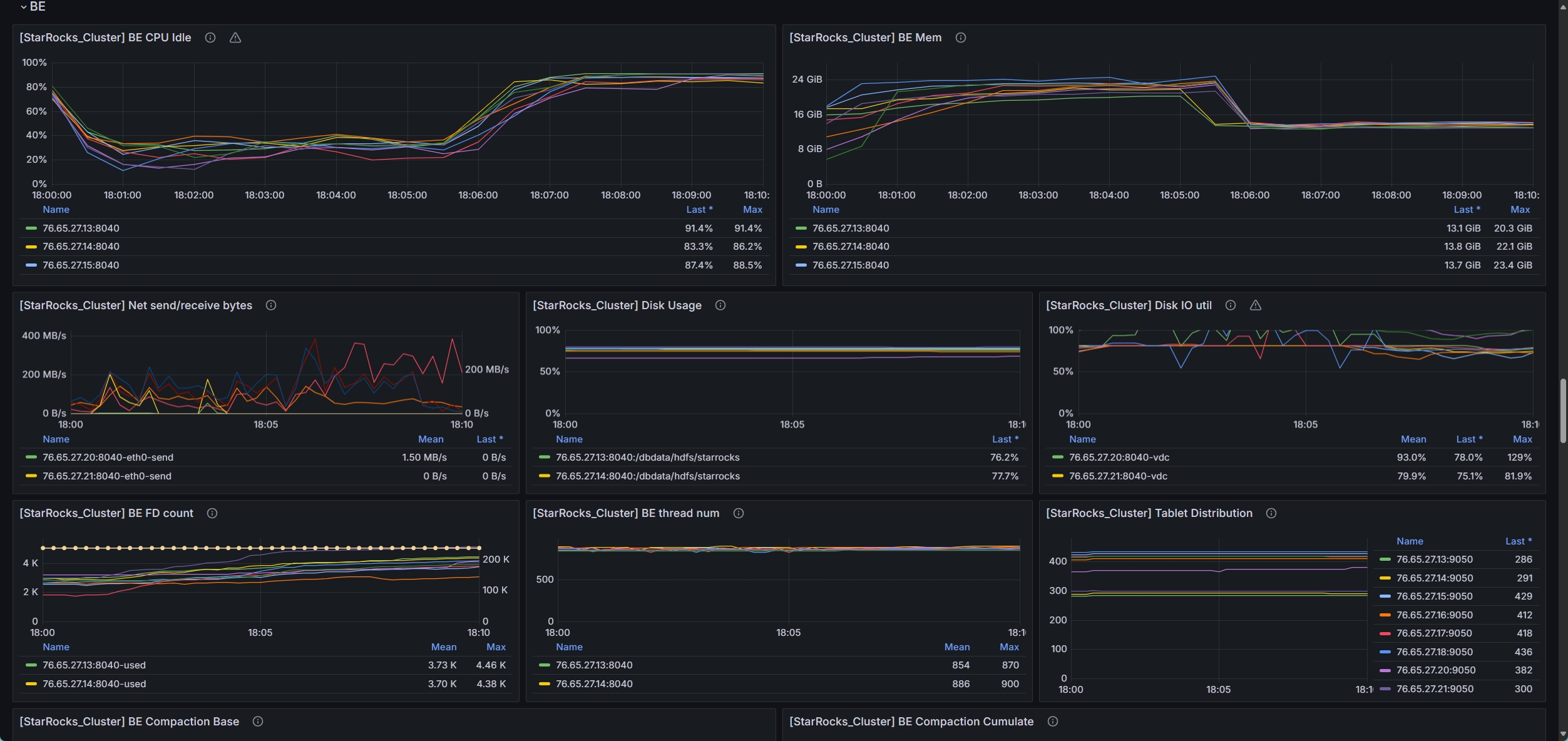
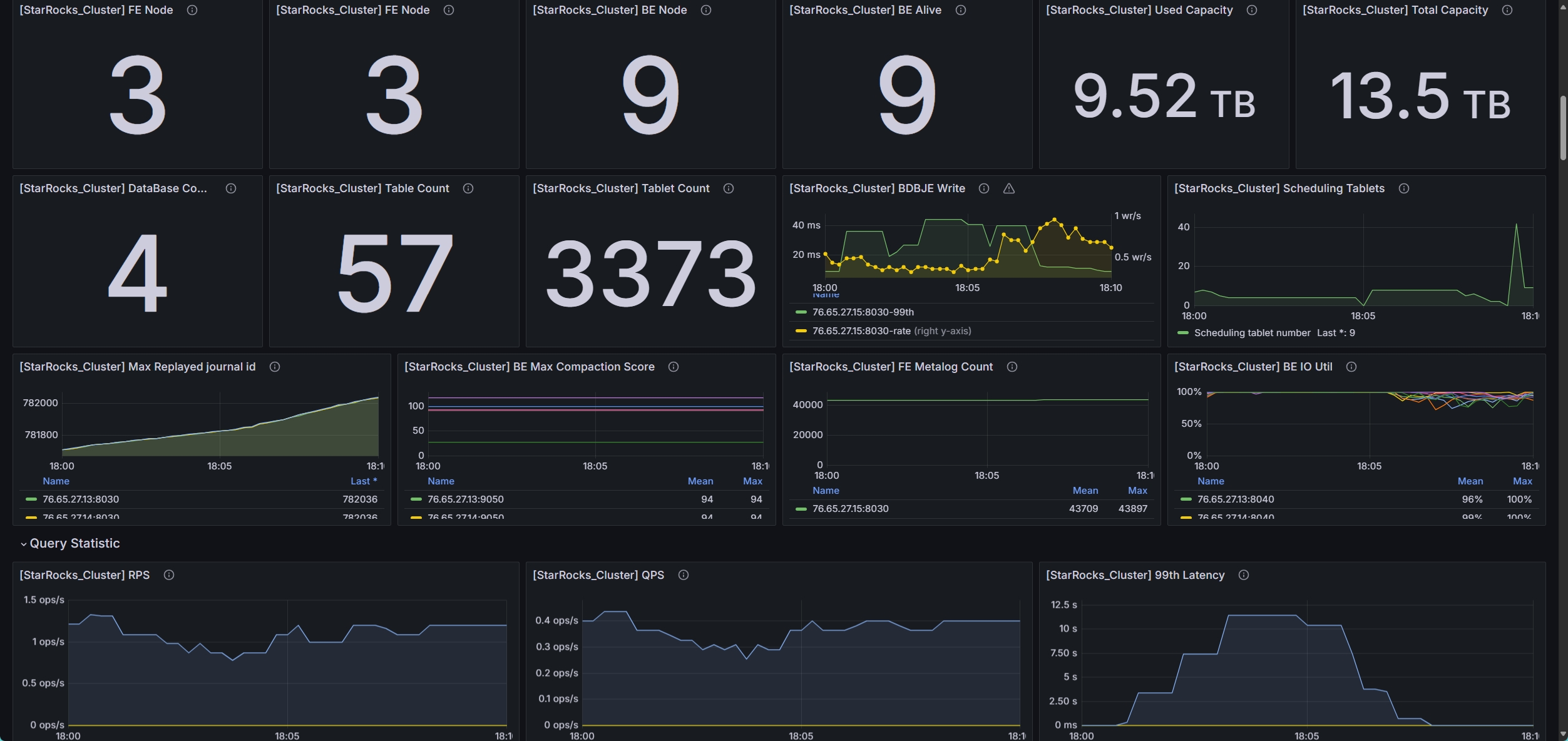
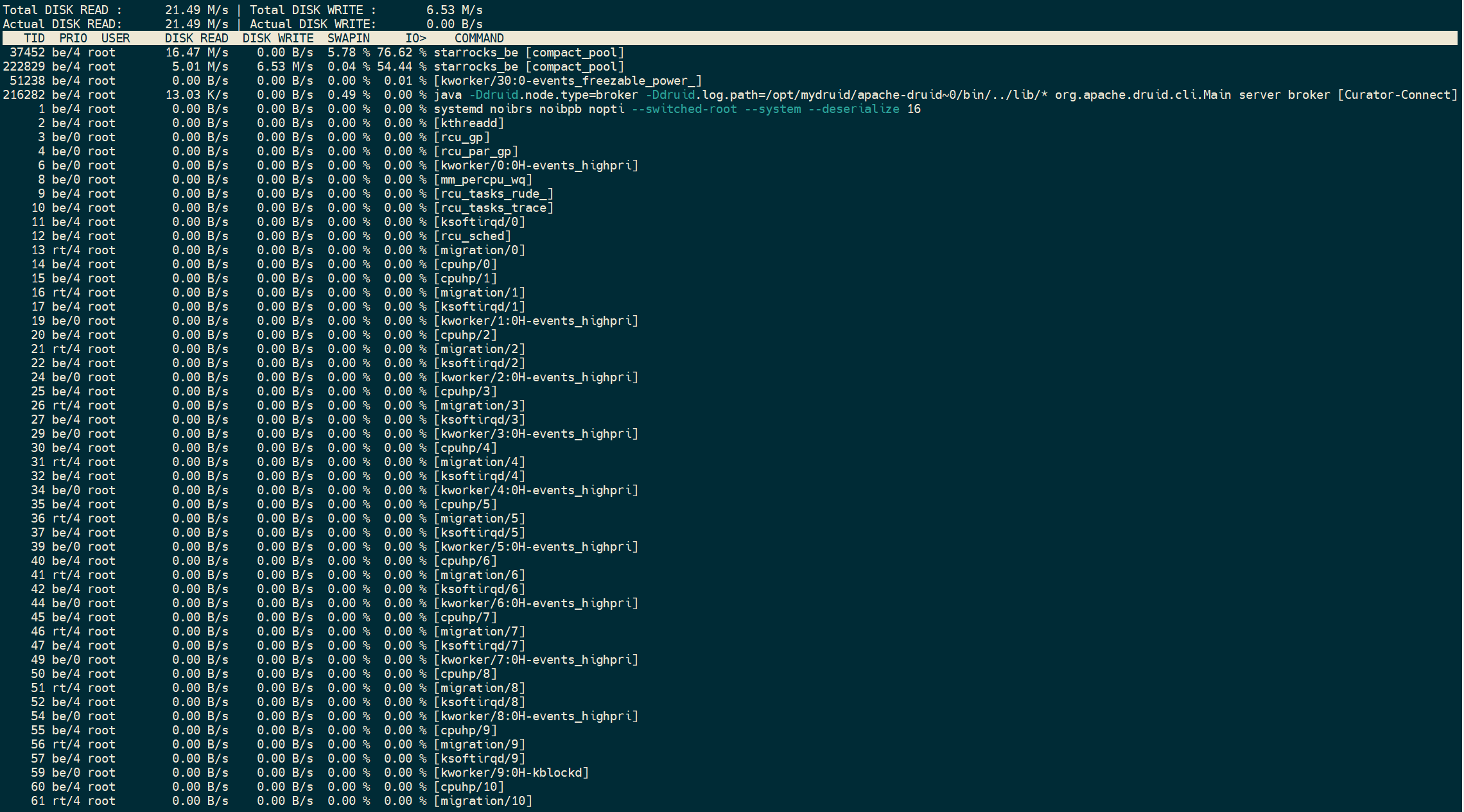
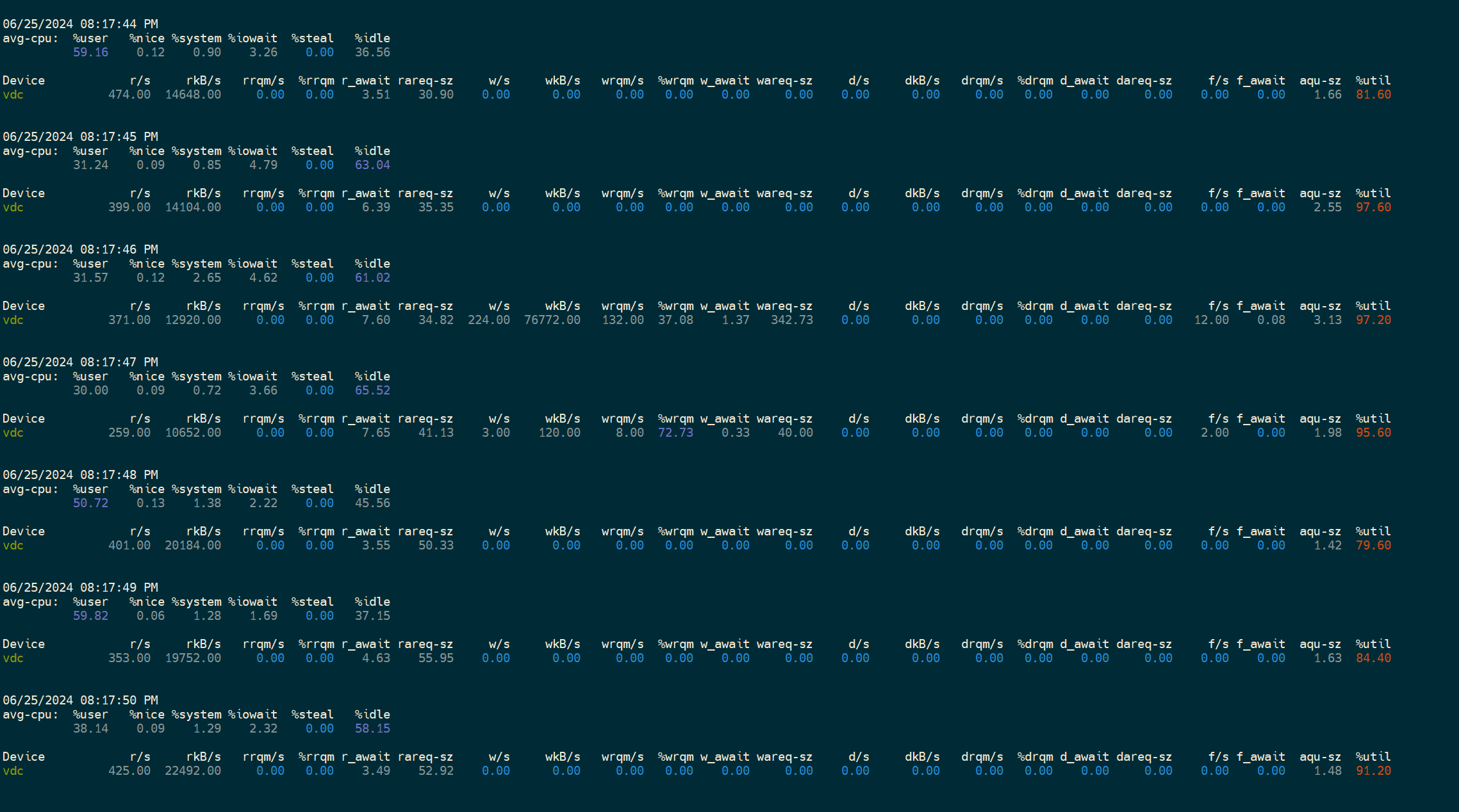
- be节点cpu和内存使用率截图
be节点平均cpu利用率约4核,平均内存约23G,磁盘IO跑满100%利用率
- 查询报错:
- query_dump,怎么获取query_dump文件
dump_file.zip (16.0 KB)
- query_dump,怎么获取query_dump文件
- be crash
- be.out
be.out没看到报错
- be.out
start time: Wed Jun 5 06:17:00 PM CST 2024
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/starrocks/be/lib/jni-packages/starrocks-jdbc-bridge-jar-with-dependencies.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/starrocks/be/lib/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
start time: Fri Jun 14 11:28:55 AM CST 2024
start time: Tue Jun 18 09:28:14 AM CST 2024
start time: Tue Jun 18 12:02:16 PM CST 2024
start time: Tue Jun 18 03:43:25 PM CST 2024
start time: Tue Jun 18 07:35:56 PM CST 2024
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/starrocks/be/lib/jni-packages/starrocks-jdbc-bridge-jar-with-dependencies.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/starrocks/be/lib/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
start time: Thu Jun 20 07:57:28 PM CST 2024
start time: Fri Jun 21 02:13:06 PM CST 2024
start time: Fri Jun 21 03:51:46 PM CST 2024
start time: Fri Jun 21 04:06:25 PM CST 2024
start time: Fri Jun 21 05:17:27 PM CST 2024
Ignored unknown config: storage_page_cache
start time: Fri Jun 21 05:40:05 PM CST 2024
Ignored unknown config: storage_page_cache
start time: Fri Jun 21 06:00:11 PM CST 2024
Ignored unknown config: storage_page_cache
start time: Mon Jun 24 07:07:17 PM CST 2024
Ignored unknown config: storage_page_cache
- 外表查询报错
- be.out和fe.warn.log
fe.warn.log:
fe.warn.log (23.5 KB)
- be.out和fe.warn.log