
StarRocks查询scan性能分析
背景
我们时常遇到sql执行时间不及预期的情况,为了优化sql达到预期查询时延,我们能够做哪些优化。本文旨在分析sql执行时间中的scan部分耗时是否合理以及对应优化方式。
准备
打开profile分析上报。
使用mysqlclient连接starrocks集群,
mysql -h ip -P9030 -u root -p xxx
然后输入
##该参数开启的是session变量,若想开启全局变量可以set global is_report_success=true;一般不建议全局开启,会略微影响查询性能
mysql> set is_report_success=true;
该参数会打开profile上报,后续可以查看sql对应的profile,从而分析sql瓶颈在哪。如何进一步优化。
如何获取profile?
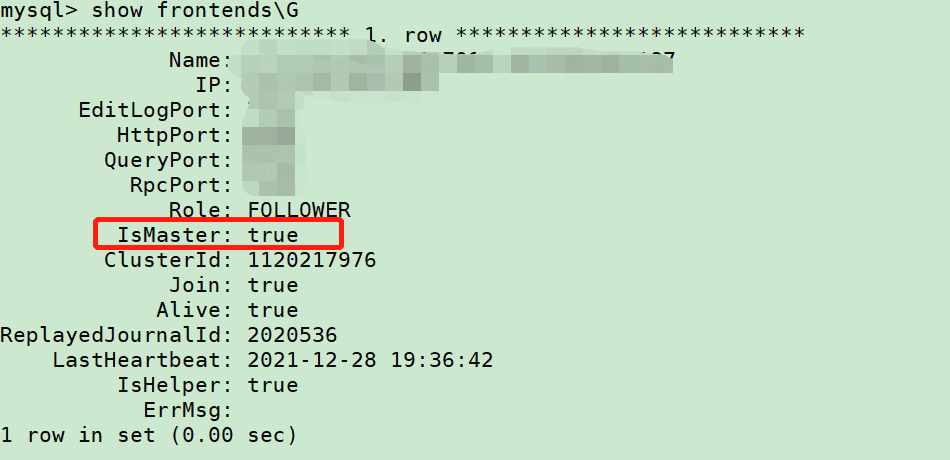
如上设置打开profile上报后,打开fe的http界面(http://ip:8030),如下点击queries后,点击相应sql后的profile即可查看对应信息。

注:此处需要进master的http页面。如不确定集群哪台是master,可以show frontends查看IsMaster值为true的ip
explain分析
Explain sql获取执行计划,如下
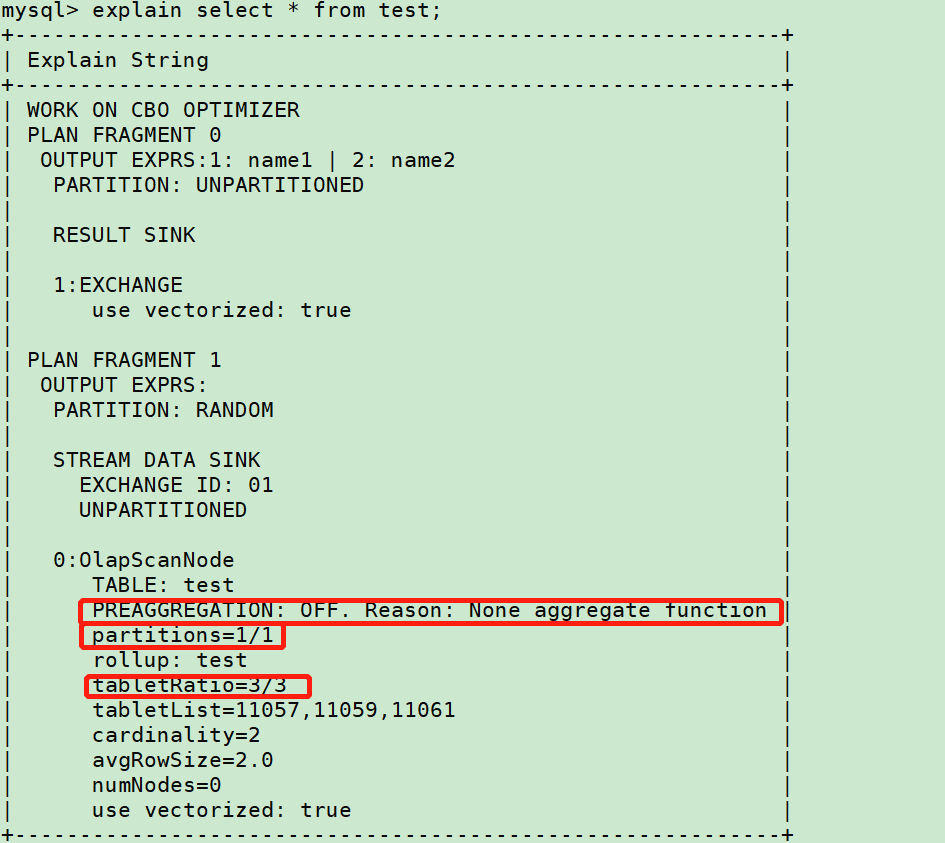
分区分桶
上图中
partitions字段x/xx表示 查询分区/总分区
tabletRatio字段x/xx表示 查询分桶/总分桶
查看对应查询sql是否包含分区字段,是否正确裁剪。如未正常裁剪,确认是否有以下问题:
- 字段类型不一致
- 字段有函数 eg:
date_format('2009-10-04 22:23:00', '%W %M %Y')
存储层聚合
何时需要存储层聚合?
- 聚合表的聚合发⽣在导⼊
- Compaction
- 查询时
PREAGGREGATION 是On 表⽰存储层可以直接返回数据, 存储层⽆需进⾏聚合
PREAGGREGATION 是 OFF 表⽰存储层必须聚合, 可以关注下 OFF的原因是否符合预期
profile分析
再porifle中搜索OLAP_SCAN_NODE,会有很多个结果形如OLAP_SCAN_NODE (id=0),其中id=x有多个,表示同一个表的scan信息。如下是一个典型的scan慢节点。
OLAP_SCAN_NODE (id=0):(Active: 56s208ms[56208256470ns], % non-child: 0.00%)
- Table: xxxx
- Rollup: xxxx
- Predicates: 3: svrIp = 'xxx.xxx.xxx.xxx'
- BytesRead: 1.21 GB
- NumDiskAccess: 0
- PeakMemoryUsage: 1.24 MB
- PerReadThreadRawHdfsThroughput: 0.0 /sec
- RowsRead: 0
- RowsReturned: 96
- RowsReturnedRate: 1
- ScanTime: 56s206ms
- ScannerThreadsInvoluntaryContextSwitches: 0
- ScannerThreadsTotalWallClockTime: 0ns
- MaterializeTupleTime(*): 0ns
- ScannerThreadsSysTime: 0ns
- ScannerThreadsUserTime: 0ns
- ScannerThreadsVoluntaryContextSwitches: 0
- TabletCount : 1
- TotalRawReadTime(*): 0ns
- TotalReadThroughput: 0.0 /sec
MERGE:
- aggr: 56s206ms
- union: 56s203ms
SCAN:(Active: 56s203ms[56203074918ns], % non-child: 45.19%)
- CachedPagesNum: 0
- CompressedBytesRead: 2.05 GB
- CreateSegmentIter: 435.687us
- DictDecode: 3.149ms
- IOTime: 48s384ms
- LateMaterialize: 42s792ms
- PushdownPredicates: 1
- RawRowsRead: 459.082236M (459082236)
- SegmentInit: 661.218ms
- BitmapIndexFilter: 0ns
- BitmapIndexFilterRows: 0
- BloomFilterFilterRows: 0
- ShortKeyFilterRows: 0
- ZoneMapIndexFilterRows: 19.611648M (19611648)
- SegmentRead: 12s743ms
- BlockFetch: 11s190ms
- BlockFetchCount: 694.015K (694015)
- BlockSeek: 829.477ms
- BlockSeekCount: 1.058K (1058)
- ChunkCopy: 124.666ms
- DecompressT: 40.773ms
- DelVecFilterRows: 0
- IndexLoad: 0ns
- PredFilter: 161.341ms
- PredFilterRows: 458.902727M (458902727)
- TotalPagesNum: 146.41K (146410)
- UncompressedBytesRead: 2.08 GB
其中table=x可以看到对应的所扫描的表信息。
数据倾斜
查询某张表的scan信息,比如上述test表对应的OLAP_SCAN_NODE (id=0),分别检索查看多个Active: xxxms信息,观察是否差距很大,如果存在个别节点耗时是其他节点数据量倍数,
例如:
OLAP_SCAN_NODE (id=0):(Active: 4m50s[290851091923ns]
OLAP_SCAN_NODE (id=0):(Active: 25 0. 6 44ms[ 25 0 6 44279ns]
OLAP_SCAN_NODE (id=0):(Active: 13 1 .8 7 4ms[13 1 8 7 42 36 ns]
OLAP_SCAN_NODE (id=0):(Active: 1 6 0.8 32 ms[1 6 08 32 2 21 ns]
…
则有数据倾斜的问题。可以运行一下tabelt分析工具。
https://starrocks-public.oss-cn-zhangjiakou.aliyuncs.com/tools.tar.gz
下载完成后编辑config.ini信息,然后执行
./healthy_report config.ini
不支持在 Docs 外粘贴 block
可以获取以下信息:
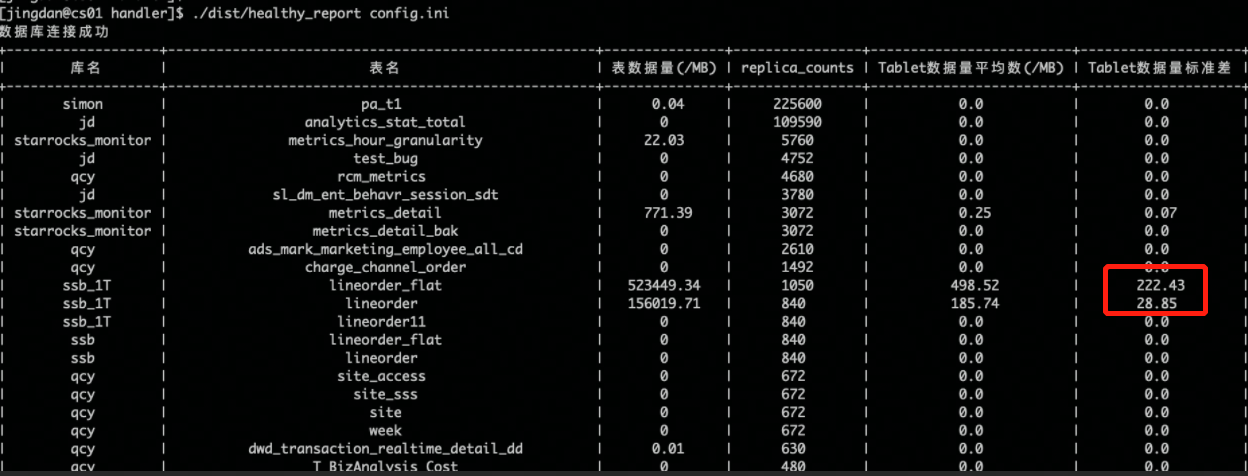
以上信息中关注下标准差那列,如果异常高,则表示该表需要重新选取hash键,建表不合理有严重的数据倾斜问题。
除此还可以关注下tablet数据平均值是否合理,一般建议该值在100MB-1GB之间,对于表总体数据量比较小时可以容忍小一点,数据量大的表建议在1G左右,如果该值与建议值差异较大,可以适当调整建表语句的bucket数量大小。
关键指标
以下对scan的关键指标做一些解读,如果对应字段的值占比总查询时间很高,可以针对该阶段进行分析。
BytesRead
读取tablet数据量大小,该值太大或者太小表示tablet设置的均不合理,可以参考视频内容,简单说明了分桶数的作用以及使用注意事项:
https://www.bilibili.com/video/BV1SX4y1c7i4?p=2
RowsReturned
扫描返回符合要求的行数,如果BytesRead很大,而RowsReturned很小。但是scan占比挺久,可以考虑将过滤条件中的字段建表时设置为key列,对点查效果有很好的加速效果,关于排序列的使用可以参考以下内容:
https://www.bilibili.com/video/BV1SX4y1c7i4?p=1
RowsReturned Rate
结果集返回速率,如果有个别节点返回比较慢,可以查看磁盘读写是否异常,或者cpu,内存资源是否负载很高,导致系统调度时间增加,该问题常见% non-child: 98.1%占比很大。
TabletCount
tablet数量,关注此处是否太多或者太少,此处和bucket设置息息相关,一般按照数据量去划分bucket数量,同BytesRead综合分析是否需要修改bucket数量
MERGE
如果merge中的aggr/union/sort耗时特别久,则整体瓶颈在底层rowset的merge上,该问题常见于unique表和aggregate表,在于内部存在多个rowset没有合并,导致查询时内部需要做相应操作,从而影响结果集输出。可以通过以下步骤去排查rowset是否太多:
Show tablet from table\G
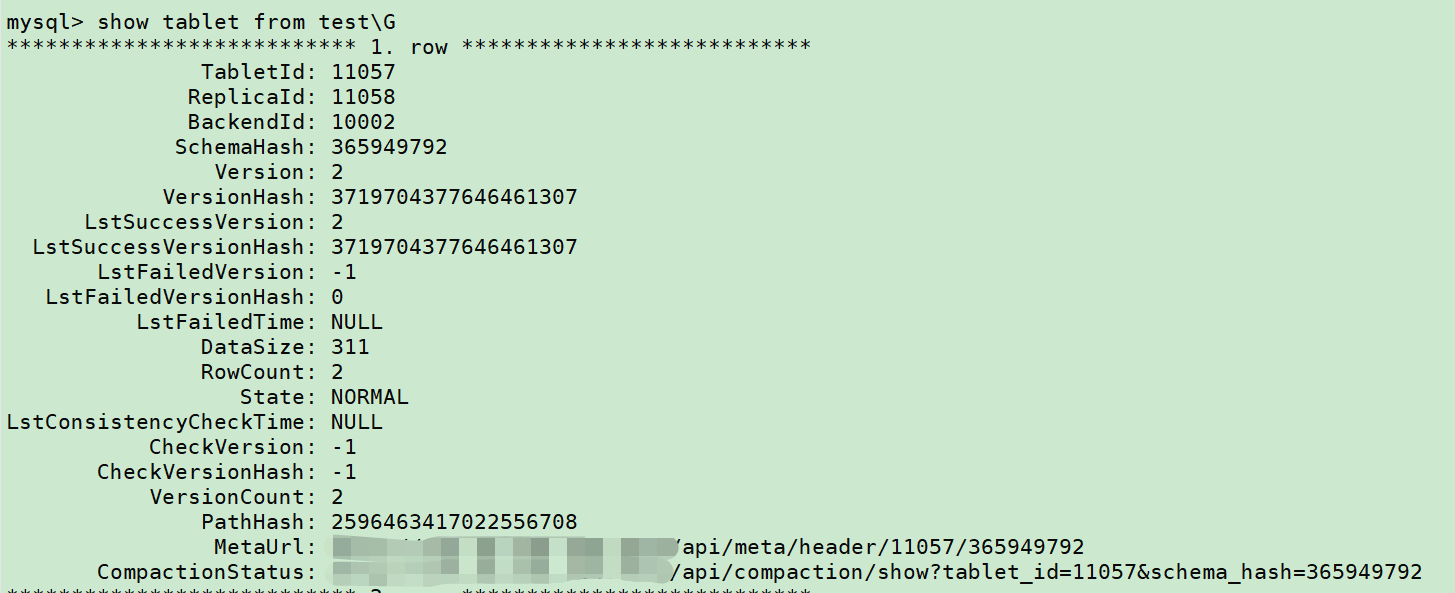
找到version比较大的tablet,此处举例取11057,接着
Show tablet 11057\G
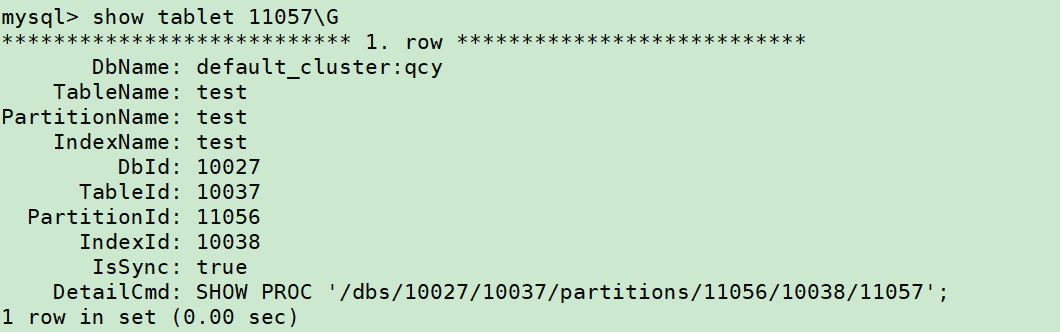
可以用 「DetailCmd」的命令,来进一步展示详细信息:
SHOW PROC '/dbs/10027/10037/partitions/11056/10038/11057'\G
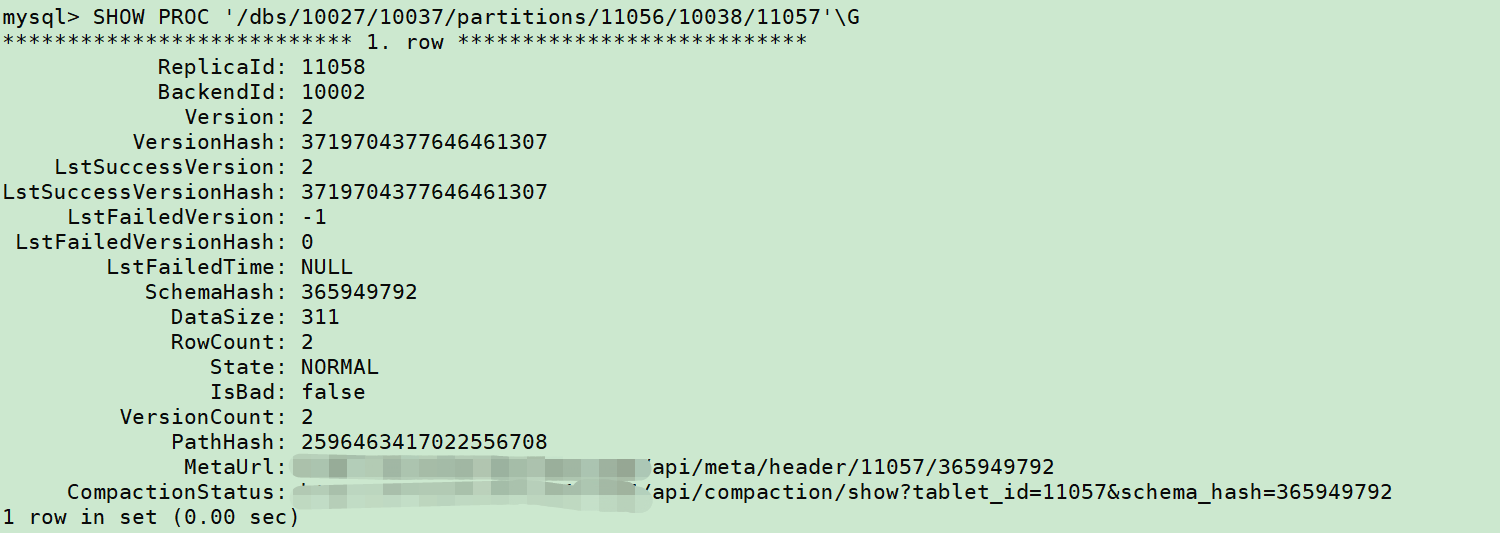
访问「CompactionStatus」中的 URL,会展示分片的几个副本(replica)的具体信息,包括可以查看每个副本更多元数据信息。
会出现如下信息:
{
"cumulative point": 40716,
"last cumulative failure time": "2021-05-28 14:28:07.695",
"last base failure time": "1970-01-01 08:00:00.000",
"last cumulative success time": "2021-05-27 18:30:59.385",
"last base success time": "2021-05-27 18:30:59.385",
"rowsets": [
"[0-40603] 1 DATA NONOVERLAPPING",
"[40604-40635] 0 DATA NONOVERLAPPING",
"[40636-40674] 1 DATA NONOVERLAPPING",
"[40675-40715] 0 DATA NONOVERLAPPING"
],
"stale version path": []
}
此处有4个rowset说明数据还没充分做compaction。(其中 NONOVERLAPPING 只是表示一个 rowset 内部,如果有多个 segment 时,是否有重叠部分)。
可以通过修改 BE 的 conf/be.conf 中的配置,加快 compaction,以减少版本数:
# 加快做 comulative compaction 的检查,能减少版本数(rowset 的数量)
cumulative_compaction_check_interval_seconds = 2
cumulative_compaction_num_threads_per_disk = 2
base_compaction_num_threads_per_disk = 2
如果想要进一步合并 2 个 rowset 为 1 个 rowset,可以做如下配置,但一般不建议,因为会导致增加大量 base compaction。
# Cumulative文件数目要达到设定数值,就进行 base compaction
base_compaction_num_cumulative_deltas = 1
注:聚合和更新表key列过多时,会极大影响merge时间,可以根据业务合适选取key列,如果必要的key列实在很多,可以考虑以下几种方案:
- 聚合表可以考虑用明细表+物化视图替代
- 更新表如果符合主键模型的场景,可以使用主键模型替代,详情参考文档主键模型使用部分内容:https://docs.starrocks.com/zh-cn/main/table_design/Data_model#主键模型
IOTime
磁盘io所用时间,和上述MERGE和RowsReturnedRate有关,排查见如上所示。
PushdownPredicates
下推到存储层的谓词
RawRowsRead
读取行数
BitmapIndexFilter / BitmapIndexFilterRows / BloomFilterFilterRows
被索引过滤的行数
PredFilter
谓词过滤的时间
PredFilterRows
谓词过滤的行数
注:如果有谓词下推异常或者分区分桶裁剪不正常的情况可以检查是否包含以下问题:
- 字段类型不一致
- 过滤条件中左边字段有函数 eg:
date_format('2009-10-04 22:23:00', '%W %M %Y')