
为了更快的定位您的问题,请提供以下信息,谢谢
【详述】问题详细描述
使用主键模型,从MySQL导入5亿行100列的大宽表到Starrocks,导入过程中发现metadata占用内存较大,调试发现创建了大量ColumnReader对象,不知是否有内存泄露?
【背景】导入数据
【业务影响】OOM
【是否存算分离】否
【StarRocks版本】例如:3.1.11
【集群规模】单机合并部署
【机器信息】80C360G
运行中memory profile如下
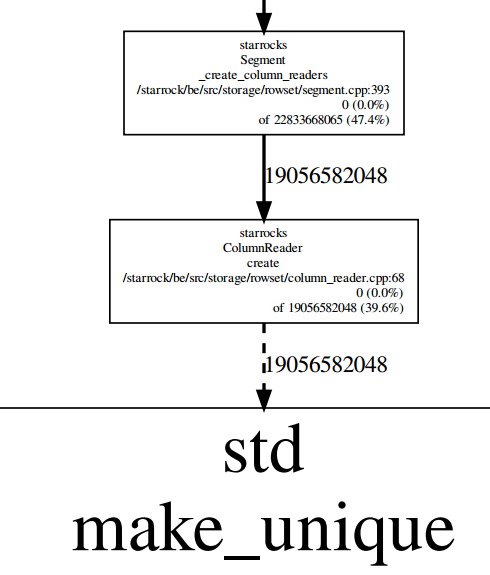
不知道为什么创建这么多ColumnReader对象,我统计了一下大概有1.7亿个,每个152字节
,同时我的segment大概7000个,tablet200个。另外如果不是内存泄露,那么ColumnReader能不能关闭一些 ,防止占用太多内存。