【详述】BE节点磁盘io打满,有查询任务报错。
【背景】无
【业务影响】有查询任务报错
【是否存算分离】否
【StarRocks版本】例如:2.5.11
【集群规模】例如:3fe+7be (部分FE和BE混部)
【机器信息】12C/48G
【联系方式】社区群3-Mr。xiao
【附件】
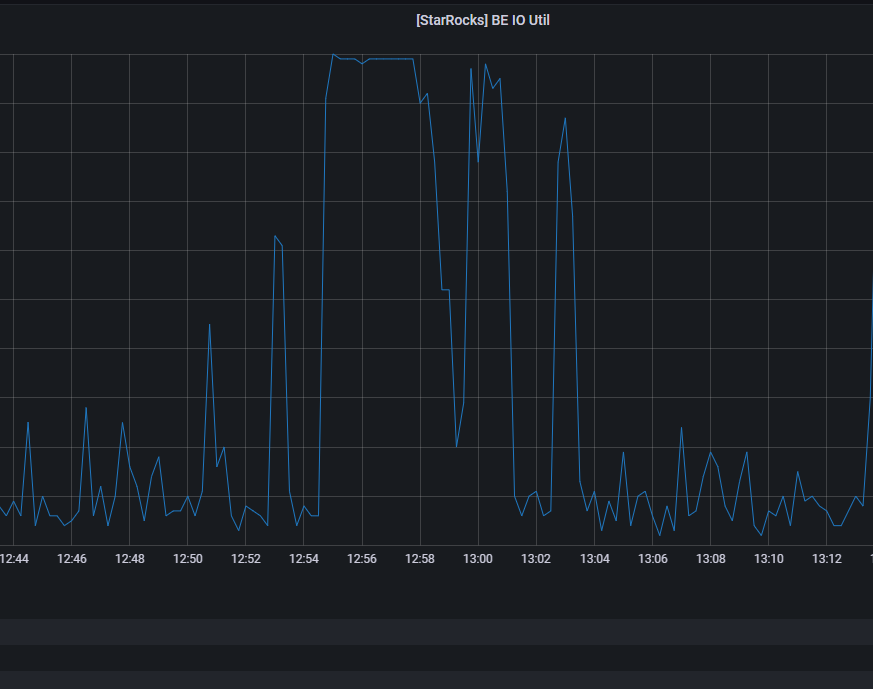
收到业务侧反馈有查询任务超时和报错,查看监控,发现BE磁盘IO打满,并持续了几分钟时间。
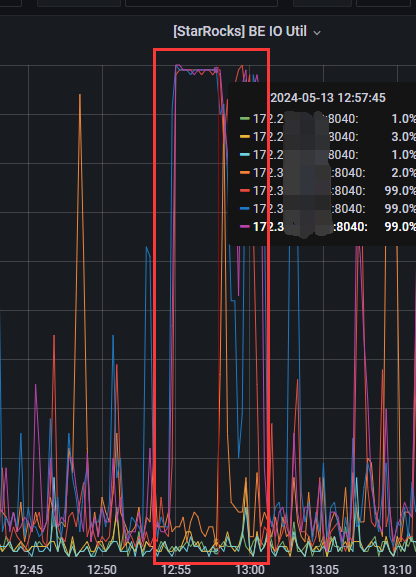
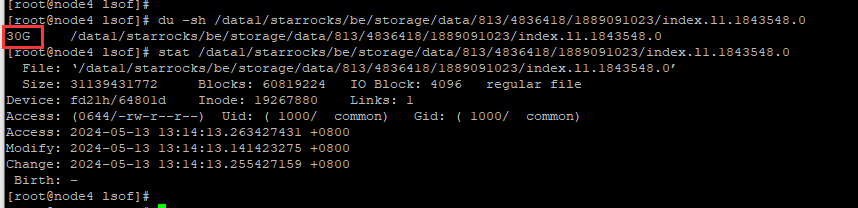
我之前在各个BE几点上部署了lsof的监控脚本,发现在IO高相同的时间段,有个index.tmp文件生成并转换为正式文件,大小为30G。
2024-05-13 12:54:23左右生成了/data1/starrocks/be/storage/data/811/4836406/1889091023/index.l1.1843458.0.tmp文件,
2024-05-13 12:57:51左右,变成/data1/starrocks/be/storage/data/811/4836406/1889091023/index.l1.1843458.0的正式文件了
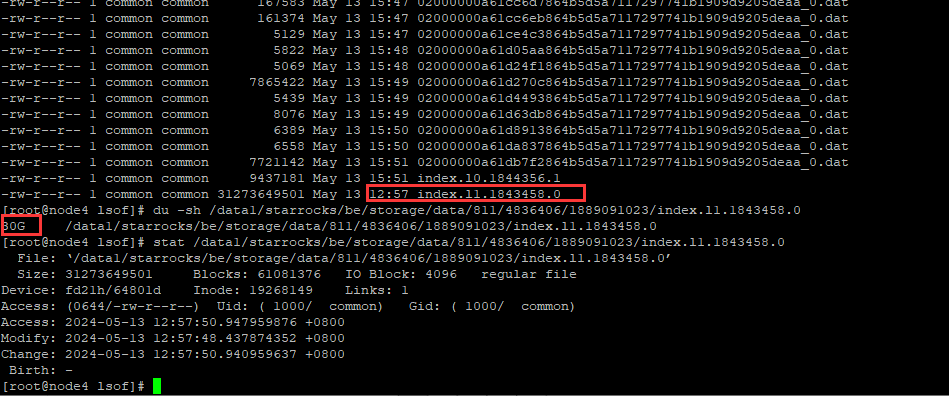

该文件大小为30G,因此分析这一时间段IO持续打满,可能和该文件读写有关,不知道这个index文件为什么这么大?
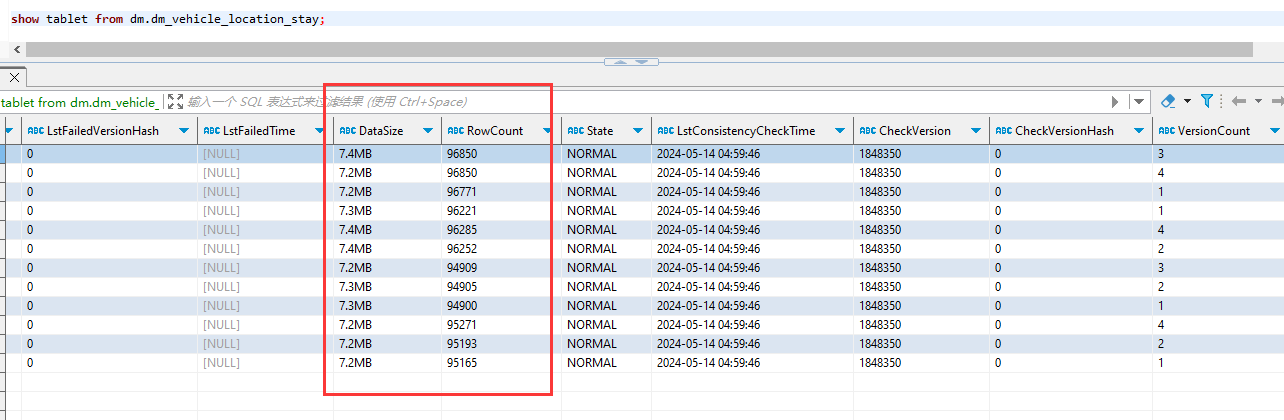
这个index的表为主键模型表,数据量为39w+,表结构如下:
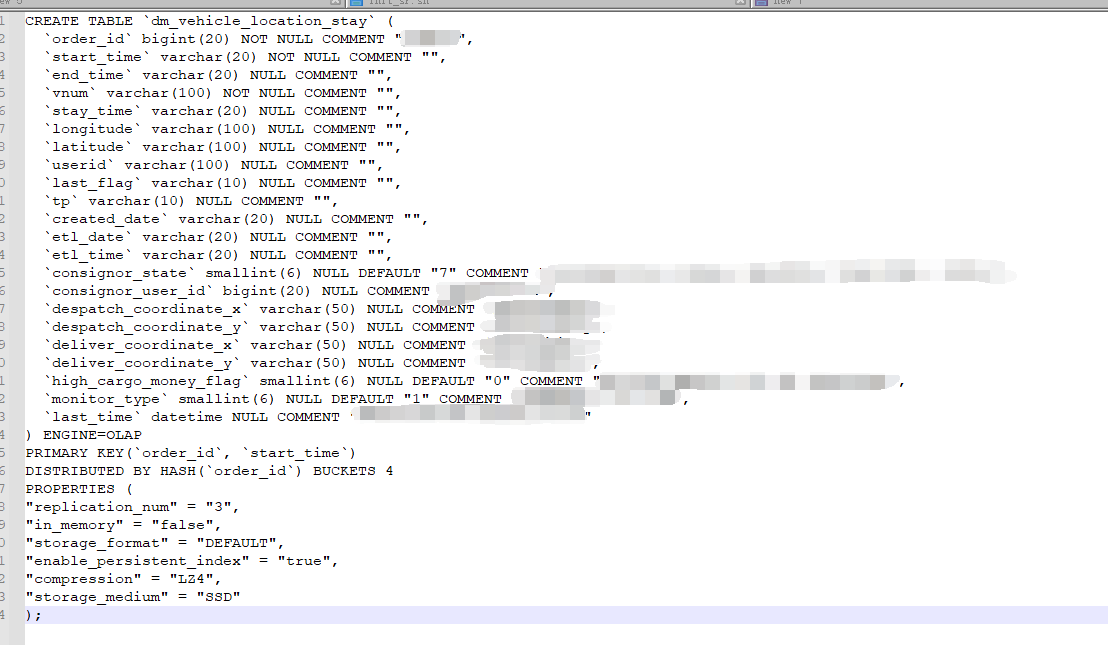
在13:10分左右,还是这张表的另一个tablet下的index文件,也是同样的问题,30G的大小文件,从生成index.l1.1843548.0.tmp到变成index.l1.1843548.0的过程中,这个时间IO也被打满了。