
为了更快的定位您的问题,请提供以下信息,谢谢
【详述】同一个查询,起10个并发查询和单次查询,性能差距大
【背景】查基础表
【业务影响】
【是否存算分离】是
【StarRocks版本】例如:3.1.5
【集群规模】例如:1fe(8CU)+3be(16CU)
【机器信息】阿里云emr
查询语句
SELECT old_goods_name
,COUNT(*)
FROM dim.dim_goods_mapping
WHERE load_date = '20240510'
GROUP BY old_goods_name
并发查询超过3s
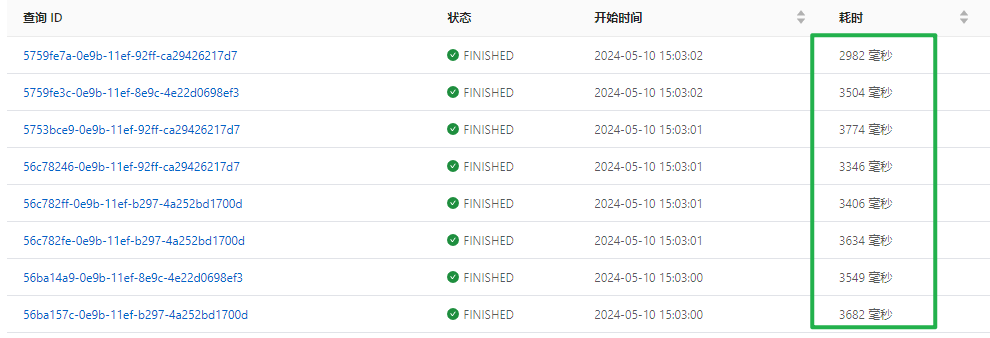
单次查询 0.3s
我拿了之前的 profile 分析,发现这个指标有差距 OutputFullTime ,不知道这个指标能怎么控制
636bc95e-0e9c-11ef-92ff-ca29426217d7-profile.txt (34.2 KB) 5753bce9-0e9b-11ef-92ff-ca29426217d7-profile.txt (34.1 KB)