【详述】
- 存算一体集群,
- flink 1.18.1 通过 flink-connector-starrocks:1.2.9_flink-1.18 写入 SR ,
- 未配置 sink.label-prefix 参数
- 任务停止后, 事务超时不终止
步骤:
- flink 任务stop 后, 给表添加字段, 一直是 WAITING_TXN 状态
- 查看 FE 日志, 发现提示等待前面的事务完成
2024-04-28 16:10:41.212+08:00 INFO (schema change|17) [SchemaChangeJobV2.runWaitingTxnJob():464] wait transactions before 126640 to be finished, schema change job: 29914
-
使用事务排查语句
SHOW TRANSACTION FROM oks WHERE id = 126637;
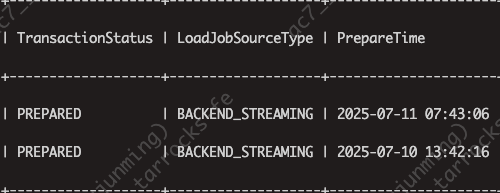
一个一个的减少事务 id 后, 发现有一个flink 的 事务是 PREPARED 状态一直没有回滚, 即便是超过 10 分钟了(默认超时 600秒) 也没回滚 -
通过 label 手动取消事务后, 给表增加字段的任务执行成功
curl --location-trusted -u oks_etl:vniwe_834w2u4 -H "label:flink-5411628e-628e-4469-b610-436432630db2" \
-H "Expect:100-continue" \
-H "db:xxxx" \
-XPOST http://sr-fe02:18030/api/transaction/rollback
【背景】执行 flink job 的 cancel 操作, 终止任务
【业务影响】 由于事务不终止, 导致给表增加字段失败, 提示 WAITING_TXN
【是否存算分离】否,
【StarRocks版本】例如:3.2.6
【集群规模】例如:3fe + 3be(fe与be独立部署)
【表模型】聚合模型
【导入或者导出方式】Flink
【附件】
这是我手动取消后的事务状态