版本:2.3.8,fe和be非混布
创建spark资源:
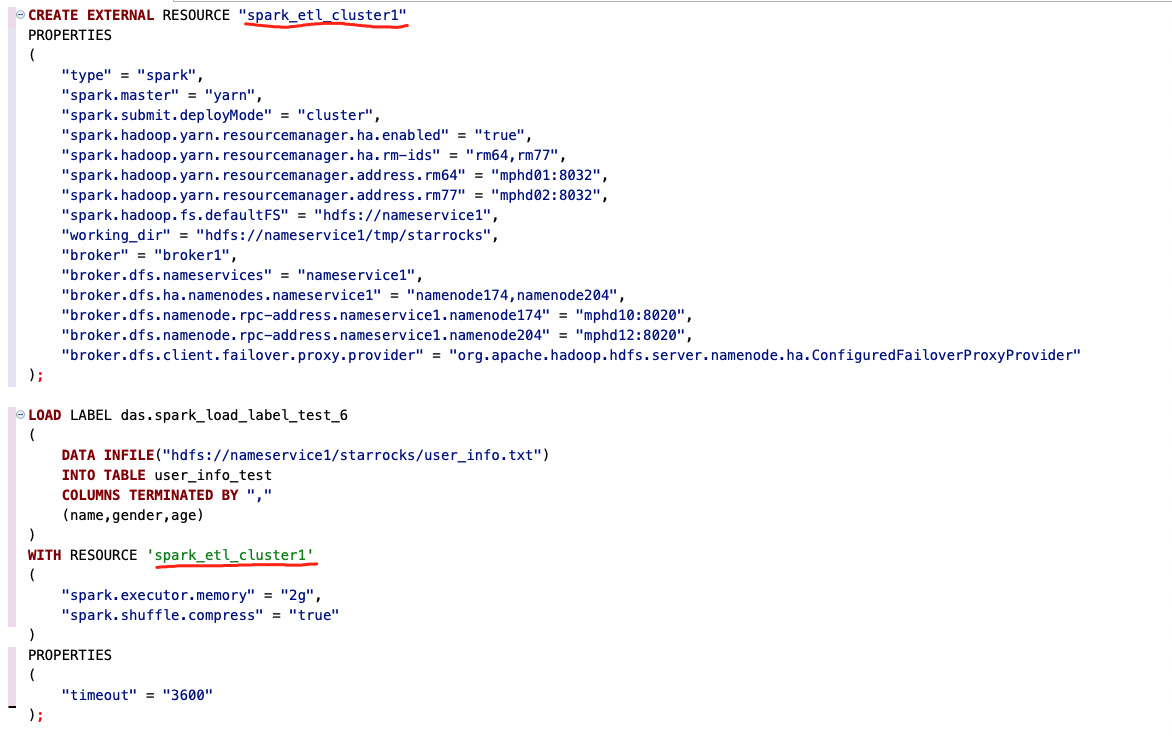
CREATE EXTERNAL RESOURCE “spark_etl_cluster”
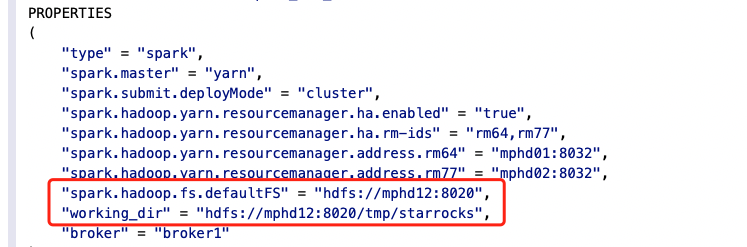
PROPERTIES
(
“type” = “spark”,
“spark.master” = “yarn”,
“spark.submit.deployMode” = “cluster”,
“spark.hadoop.yarn.resourcemanager.ha.enabled” = “true”,
“spark.hadoop.yarn.resourcemanager.ha.rm-ids” = “rm64,rm77”,
“spark.hadoop.yarn.resourcemanager.address.rm64” = “mphd01:8032”,
“spark.hadoop.yarn.resourcemanager.address.rm77” = “mphd02:8032”,
“spark.hadoop.fs.defaultFS” = “hdfs://nameservice1”,
“working_dir” = “hdfs://nameservice1/tmp/starrocks”,
“broker” = “broker1”
);
fe.conf配置spark和yarn客户端:
spark_home_default_dir = /home/starrocks/spark-2.4.6-bin-hadoop2.6
spark_resource_path = /opt/module/starrocks/fe/lib/spark2x/jars/spark-2x.zip
yarn_client_path = /opt/module/starrocks/fe/lib/yarn-client/hadoop/bin/yarn
执行导入
LOAD LABEL das.spark_load_label_test_4
(
DATA INFILE (“hdfs://nameservice1/starrocks/user_info.txt”)
INTO TABLE user_info_test
COLUMNS TERMINATED BY “,”
(name,gender,age)
)
WITH RESOURCE ‘spark_etl_cluster’
(
“spark.executor.memory” = “2g”,
“spark.shuffle.compress” = “true”
)
PROPERTIES
(
“timeout” = “3600”
);
报错:
type :ETL_SUBMIT_FAIL; msg: start spark app failed. error: Waiting too much time to get appId from handle. spark app state: UNKNOWN , loadJobId:93693049
请问这是什么原因导致的?