
为了更快的定位您的问题,请提供以下信息,谢谢
【详述】decommission下线一个be时,残留几百个tablet长时间下线不了
【背景】decommission下线一个be,执行完decommision命令后,删除了部分物化视图
【业务影响】BE长时间下线不了
【是否存算分离】否
【StarRocks版本】2.5.19
【集群规模】:3fe(3 follower)+13be(3个be与fe混部)
【机器信息】CPU虚拟核/内存/网卡,40C/128G/万兆
【联系方式】StarRocks社区群5 -思变 [1412195108@qq.com]
【附件】
监控信息
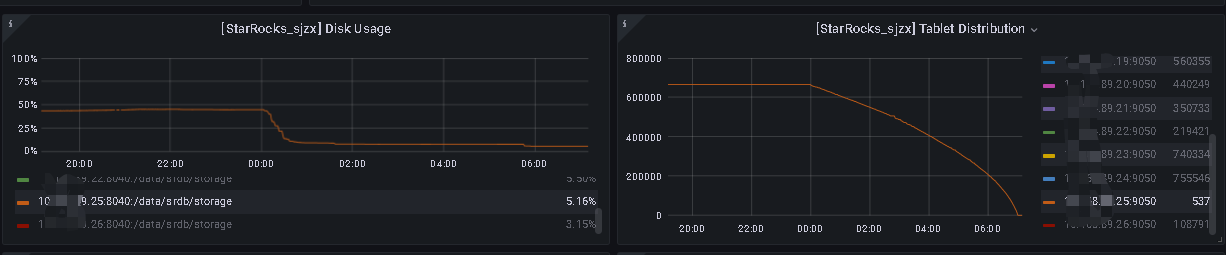
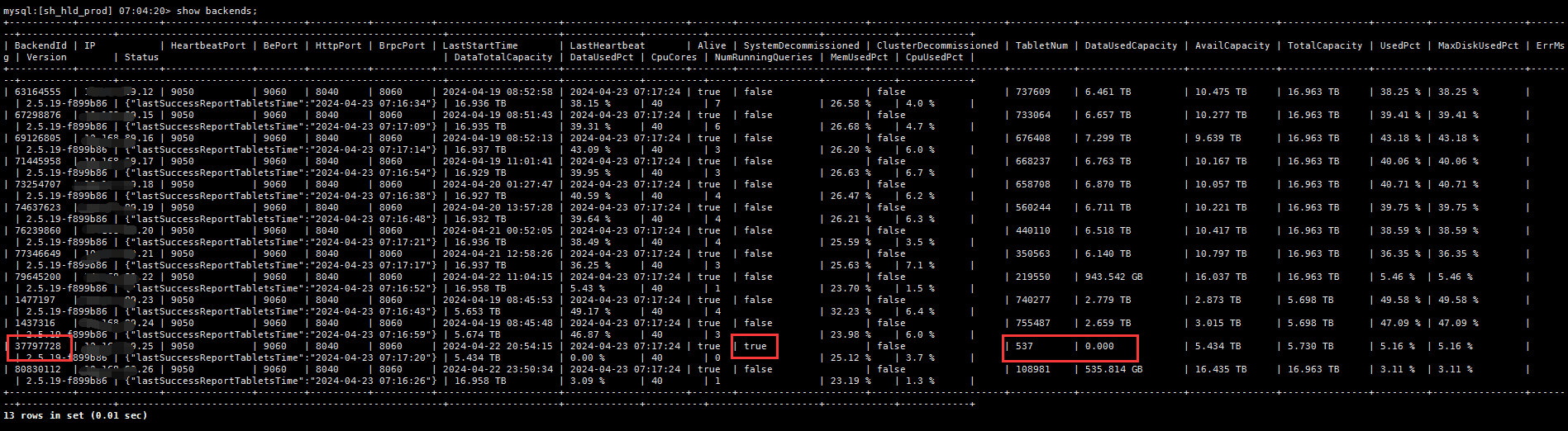
show backends;查看到要下线的be还剩下537个tablet,空间使用已经是0
查询information_schema.be_tablets无记录
select * from information_schema.be_tablets where be_id=37797728;
Empty set (0.00 sec)
Leader FE fe.log定时在输出以下信息
2024-04-23 07:31:51,060 INFO (cluster|28) [SystemHandler.runAlterJobV2():117] backend 37797728 lefts 537 replicas to decommission(show up to 20): [79681025, 79681041, 79681057, 79681062, 79681070, 79681082, 79681086, 79681110, 79681118, 79681138, 79681146, 79681150, 79681158, 79681174, 79681190, 79681210, 79681222, 79681238, 79681246, 79681254]
2024-04-23 07:31:48,819 ERROR (tablet scheduler|43) [Daemon.run():117] daemon thread got exception. name: tablet scheduler
java.lang.NullPointerException: null