
【详述】查询一个paimon 大表非常慢,表总数据行数大约22 亿,集群 100 个 backends节点,查看 profile发现数据 scan只有 3 实例运行, 如何充分利用集群节点增加查询并发?查询 iceberg表,scan阶段则有 100 实例运行, 不确定是否是 paimon catalog 实现的问题?
paimon 表 200 bucket
查询语句 select count(1) from paimon.xxx.xxxx;
【StarRocks版本】3.2.4
【集群规模】1fe +100 be
@trueeyu @yuchen1019 @Doni 帮忙看下感谢
执行计划如下
±--------------------------------------------------------------------------------------------------------------------------------+
| Explain String |
±--------------------------------------------------------------------------------------------------------------------------------+
| PLAN FRAGMENT 0(F01) |
| Output Exprs:20: count |
| Input Partition: UNPARTITIONED |
| RESULT SINK |
| |
| 4:AGGREGATE (merge finalize) |
| | aggregate: count[([20: count, BIGINT, false]); args: TINYINT; result: BIGINT; args nullable: true; result nullable: false] |
| | cardinality: 1 |
| | column statistics: |
| | * count–>[0.0, 3.533228509E9, 0.0, 8.0, 1.0] ESTIMATE |
| | |
| 3:EXCHANGE |
| distribution type: GATHER |
| cardinality: 1 |
| |
| PLAN FRAGMENT 1(F00) |
| |
| Input Partition: RANDOM |
| OutPut Partition: UNPARTITIONED |
| OutPut Exchange Id: 03 |
| |
| 2:AGGREGATE (update serialize) |
| | aggregate: count[(1); args: TINYINT; result: BIGINT; args nullable: false; result nullable: false] |
| | cardinality: 1 |
| | column statistics: |
| | * count–>[0.0, 3.533228509E9, 0.0, 8.0, 1.0] ESTIMATE |
| | |
| 1:Project |
| | output columns: |
| | 22 <-> 1 |
| | cardinality: 3533228509 |
| | column statistics: |
| | * auto_fill_col–>[1.0, 1.0, 0.0, 1.0, 1.0] ESTIMATE |
| | |
| 0:PaimonScanNode |
| TABLE: xxxxxxxxxxxx |
| partitions=1/1 |
| avgRowSize=0.0 |
| cardinality: -1 |
| column statistics: |
±--------------------------------------------------------------------------------------------------------------------------------+
40 rows in set (3.38 sec)
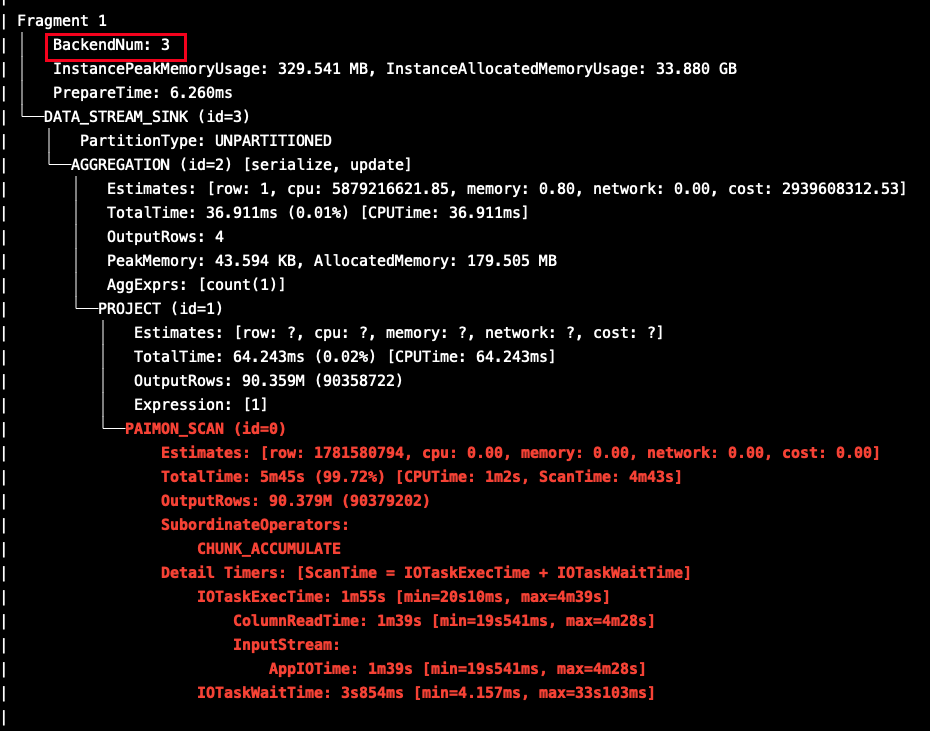
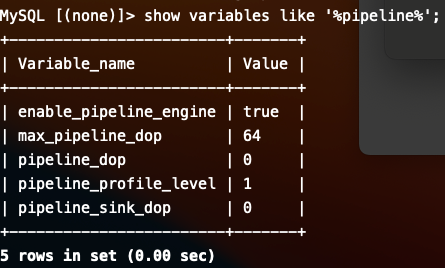
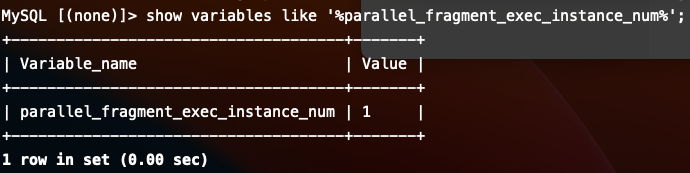
大致定位到原因了,com.starrocks.qe.HDFSBackendSelector.HdfsScanRangeHasher#acceptScanRangeLocations没有考虑到paimon
下面是一个 paimon的THdfsScanRange具体信息,没有一个条件命中com.starrocks.qe.HDFSBackendSelector.HdfsScanRangeHasher#acceptScanRangeLocations中的primitiveSink,所以最终所有 paimon THdfsScanRange计算的 hash 值都是 0
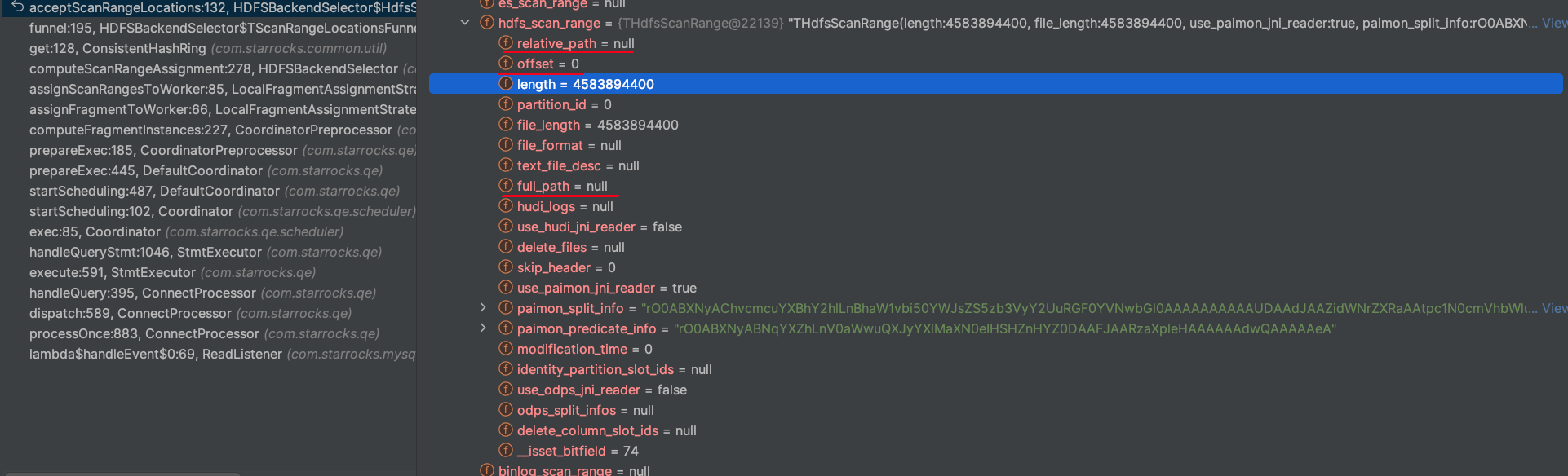
com.starrocks.qe.HDFSBackendSelector.HdfsScanRangeHasher#acceptScanRangeLocations
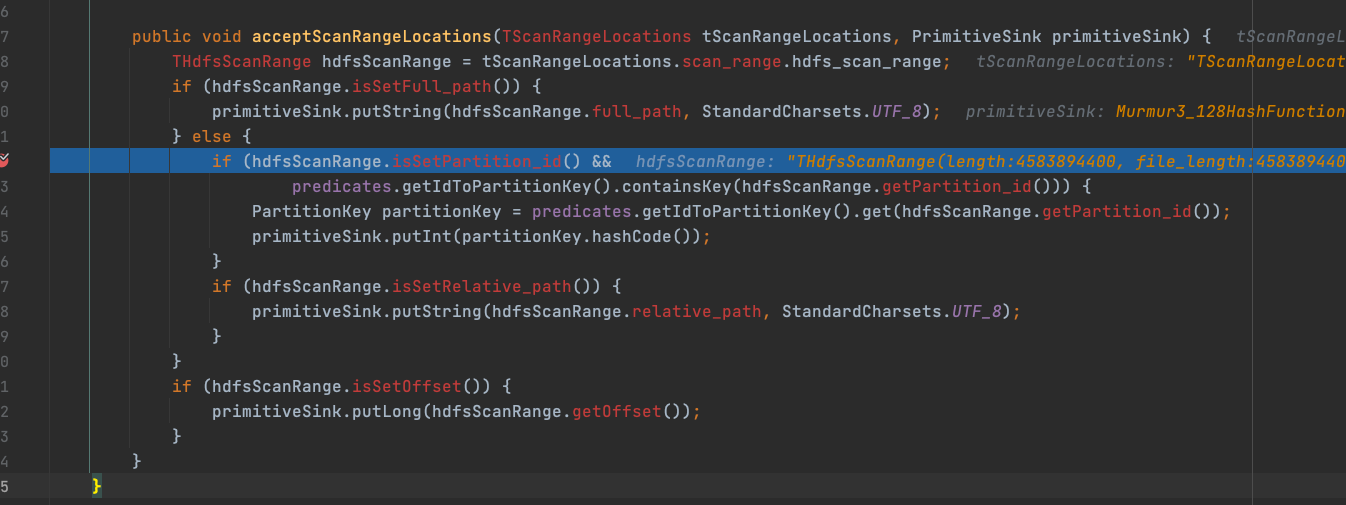
因为 hash值都是 0, 所以 hashring 返回的始终是同一组 backend, com.starrocks.qe.HDFSBackendSelector#computeScanRangeAssignment中
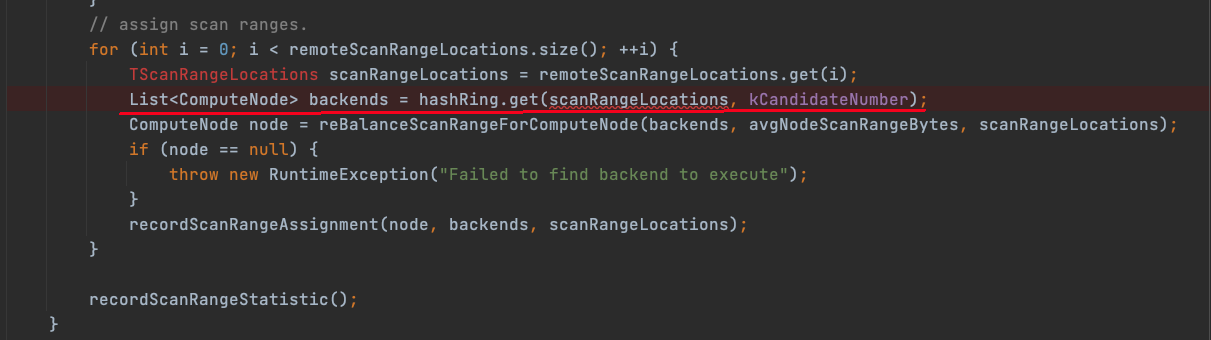
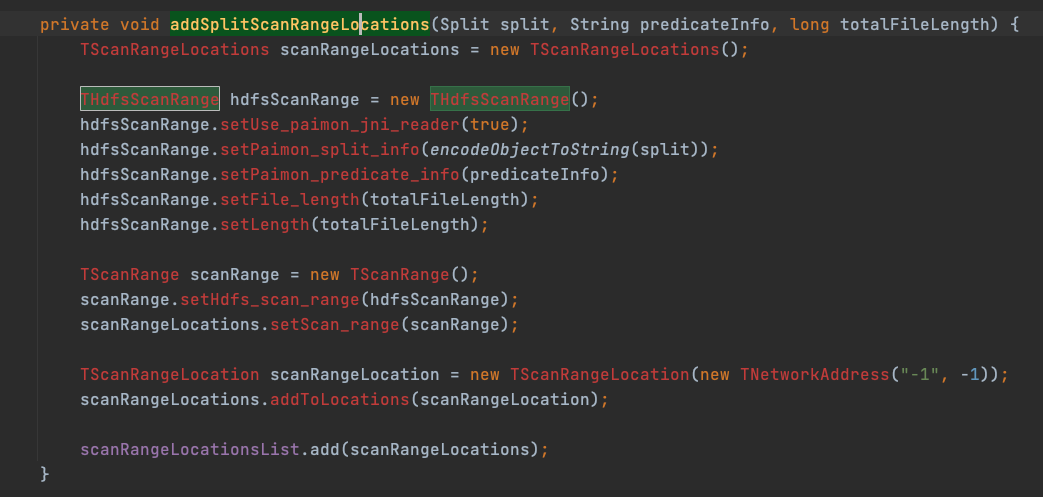
一个修复思路是把 split bucket 信息放入THdfsScanRange,根据 bucket 信息做 hash
com.starrocks.planner.PaimonScanNode#addSplitScanRangeLocations
提交 issue
非常棒的分析,希望社区能尽快修复一下