

随着大数据技术的发展,企业对于实时数据分析和决策支持的需求日益增长。在这样的背景下,指标平台的构建成为了企业数据战略的核心组成部分。一个高效的指标平台不仅能够确保数据的准确性和一致性,还能显著提升数据分析的速度和灵活性。在这样的背景下,StarRocks 以其卓越的性能和灵活的物化视图功能,成为了构建指标平台的理想选择。在本文中,我们将阐述指标平台的概念,介绍使用 StarRocks 构建指标平台的实际案例,并探讨 StarRocks 物化视图如何有效提高指标平台的性能。
What is a Metrics Layer?
构建指标平台的核心目标是实现数据指标的标准化和统一。指标平台有很多不同的称谓,如 metrics layer、semantic layer 、Headless BI 等。其核心概念是 将业务语义的指标进行统一定义,并以代码形式将其物化,使其成为公司或组织的统一数据来源 ( single source of truth ) ,达到整个公司或组织的统一语义 。
为什么需要指标平台 :
- 一次定义,处处使用
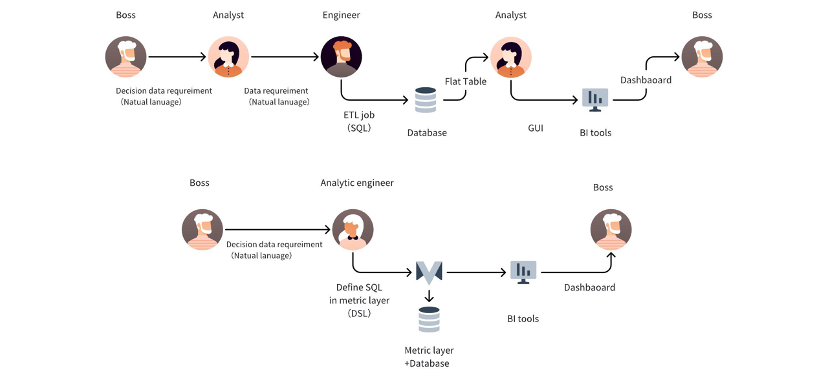
指标平台通过统一的指标定义,使得 BI 系统和数据 API 服务能够采用一致的方法进行数据展示,避免了分散开发带来的问题。传统的数据处理流程通常需要数据工程师将数据通过 ETL 转换为宽表并存储,之后数据分析师在此基础上进行进一步处理,最终在 BI 工具中展示并提供服务。
- 告别烟囱式开发架构
在缺乏统一指标定义的情况下,工程师和分析师之间容易出现分歧,导致工作重复和资源浪费。指标平台通过简化这一流程,使得分析工程师 (analytic engineer)能够统一数据工程和数据分析的角色,从业务视角出发定义一致的指标,并通过平台自动生成相应的 SQL 查询和 BI 报表,从而提高效率和准确性。
Why StarRocks?
作为企业统一的入口,指标平台必须具备强大的底层数据库支持,以满足内外部用户的各种查询需求。为此,底层数据库应具备以下特性:
-
能直接对接 BI 工具,并支持标准 SQL。
-
能支持高并发查询,以满足更多的内外部用户需求。
-
能支持不同层次的查询加速。
在此背景下,StarRocks 作为指标平台的优势有:
-
卓越的查询性能: StarRocks 提供了高性能的单表、多表和外部表查询能力,能够快速响应复杂的查询需求。
-
灵活的预计算: StarRocks 的物化视图功能可以灵活地进行预计算,从而提升查询性能和并发处理能力。
-
数据的一致性和可靠性 : StarRocks 采用湖仓(Lakehouse)架构,确保了 Single Source of Truth,从而保证数据的一致性和可靠性。
接下来,我们简要介绍一下物化视图的基本概念,以助于理解物化视图如何成为提升指标平台性能的关键因素。
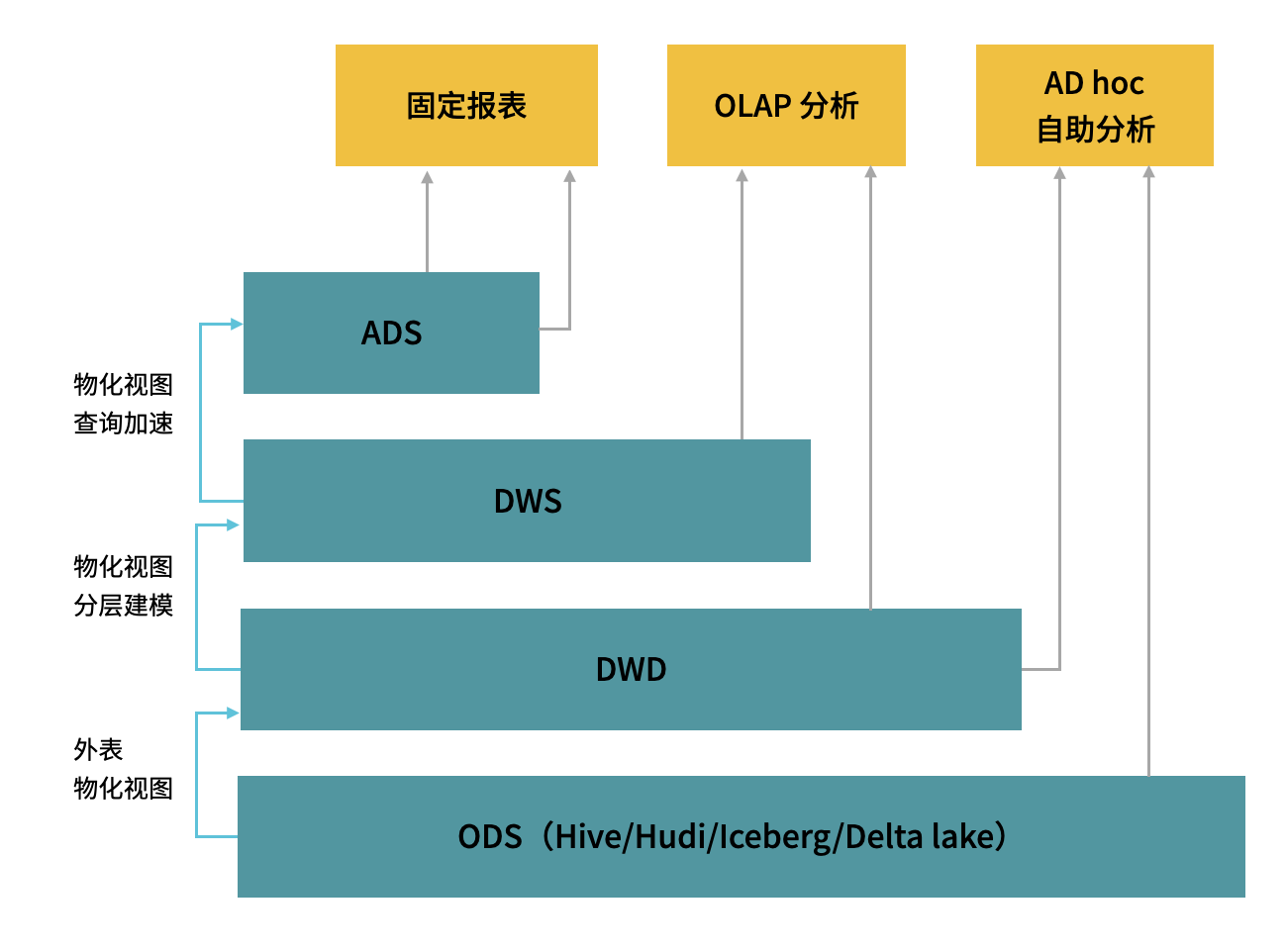
在传统数仓的分层结构中,底层数据存储在数据湖中。 通过外表和 物化视图 ,可以对数据进行初步加工和清洗。利用多表物化视图分层建模,能够有效地提高查询性能。 随着维度层次的升高,聚合能力越强,性能和并发处理能力也越好;低层次的物化视图则更适用于 ad-hoc 即席分析场景。
物化视图具有多重语义,它的价值主要体现在:
-
简化 数据建模: 物化视图能够简化数据加工流程,无需额外维护外部组件。它可以自动管理数据间的依赖关系,并控制分区粒度的刷新。
-
透明查询加速: 通过物化视图,查询可以自动利用优化后的查询路径,实现透明加速。物化视图支持各种查询操作,包括 Aggregate、Join、Union 等。
-
促进 湖仓融合: 基于外部 Catalog 建立物化视图,免去复杂的 ETL 数据准备工作。
StarRocks 指标平台案例
Airbnb
(Minerva V1 架构图)
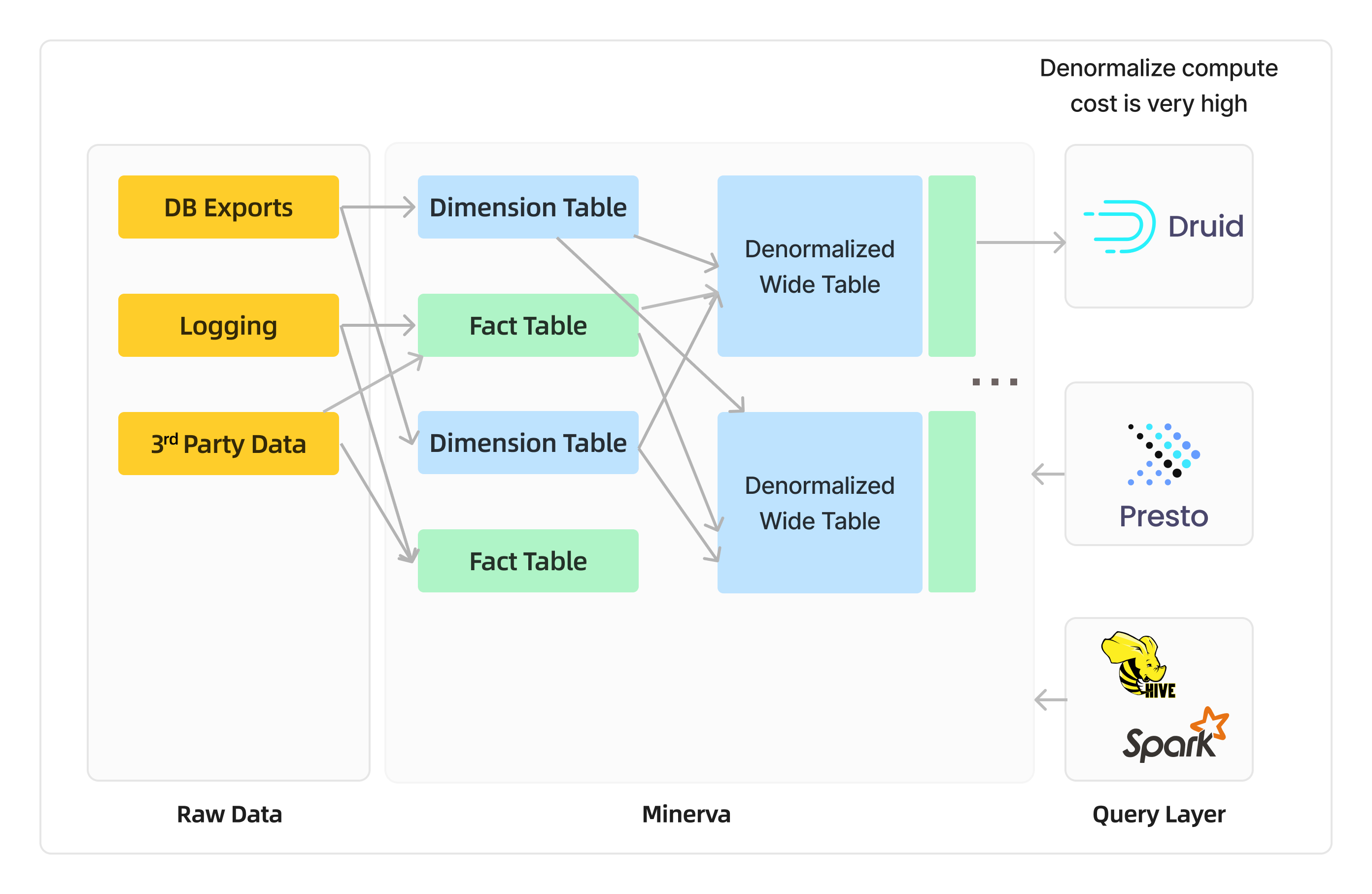
Minerva 是 Airbnb 内部使用的统一指标平台。在 V1 版本中,它通过合并维度和事实表创建了宽表,这些表存储在 Druid 中,并使用 Presto 查询 Hive 表。该平台建立了 3 万个指标和 4000 个维度,支持 A/B test 和多种数据使用场景。但宽表和 Druid 的使用引发了一些问题,如数据变更不敏感、数据维度变化需要大量数据重刷以及高昂的数据加工成本等问题。
(Minerva V2 架构图)
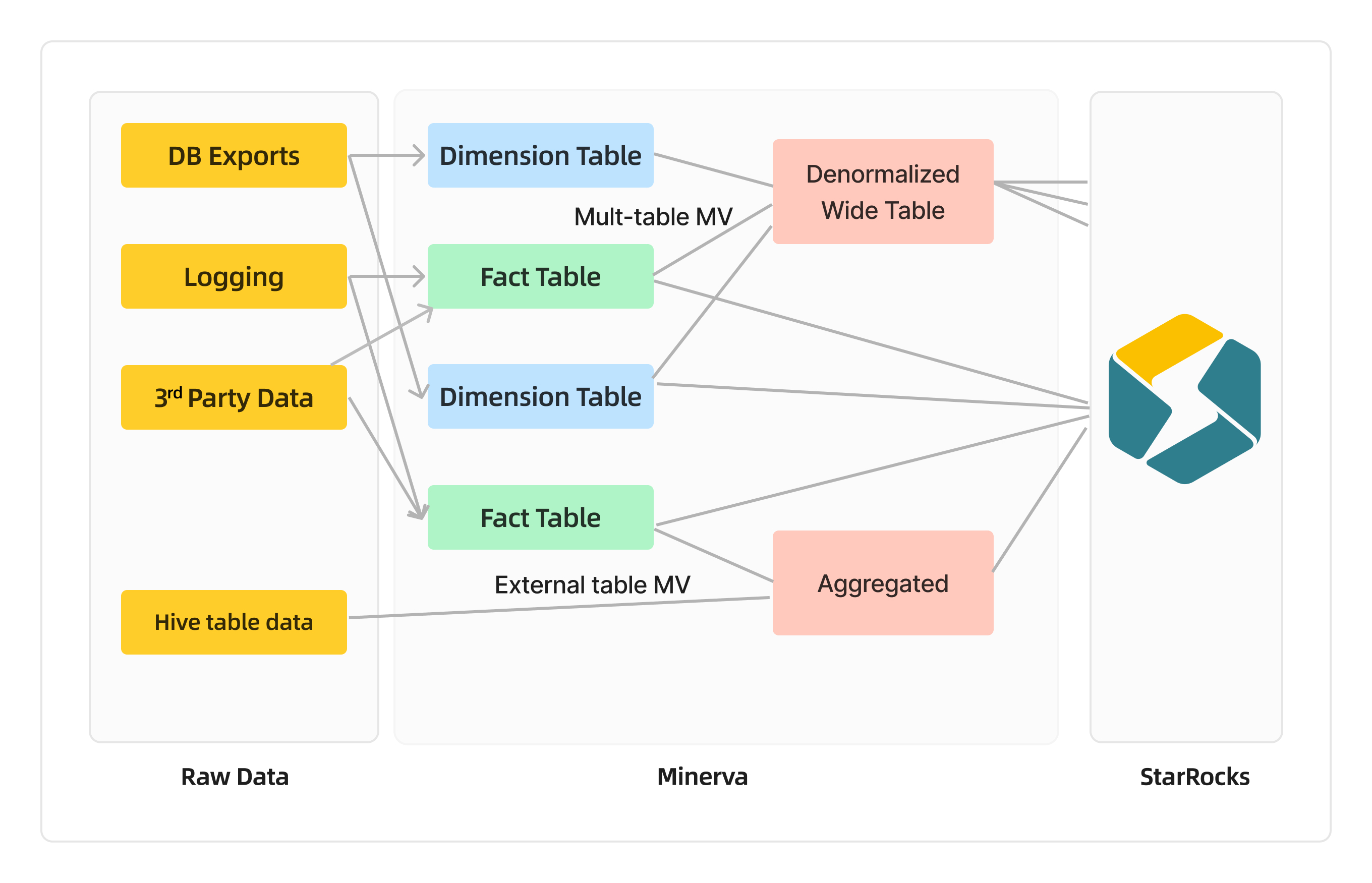
随着 Minerva 的发展,V2 版本迁移到了 StarRocks 上,并利用 StarRocks 的多表功能构建了新一代系统。
Airbnb 团队经调研发现,只有 20% 的情况下需要构建宽表,这可以通过物化视图来实现。因此,Minerva V2 版本采用了 StarRocks 外表物化视图 + colocated 的方式来构建部分外表的本地加速。
随着 StarRocks 3.0 和 3.1 版本的发布,其物化视图改写功能得到加强,通过 View Delta Join 和 Query Delta Join 技术支持更多查询类型。这使得 Minerva 能够进行更深层次的优化:
-
减少物化视图数量,服务更多查询类型:例如,原本需要多表 Join 的查询现在可以通过单个物化视图满足各种查询需求,包括聚合和 Union 操作。这样,可以用最少的物化视图满足最多的查询类型。
-
视图建模——物化视图、生成列和视图裁剪
在 Airbnb 的风控业务中,需要用大量宽视图进行逻辑建模,然后再动态裁剪无关的表结构。这是因为业务语义容易产生较宽的视图,但用户实际查询却只需要极少数张表。
例如,如果用户只查询了 a 表和 b 表的数据,系统会自动裁剪掉 c 表的数据。在风险控制等场景中,这种裁剪机制能够有效地过滤掉与查询需求无关的数据结构。为了实现这一功能,需要依赖外部表之间的主键和外键约束。
因此,在构建指标平台时,Airbnb 采用了视图进行数据建模,配合物化视图、生成列(generated column)和视图裁剪等能力极大地提升了指标平台的效能:
-
优化查询性能 :通过视图裁剪(view pruning)的能力,可以确保视图具有最佳的查询效率,通过智能地减少不必要的数据处理来提升查询速度。
-
支持派生指标 :视图可以方便地生成衍生指标或派生指标。例如,通过简单的算术表达式,可以从现有的列 a 和 b 中生成一个新的列,表示 a 加 b 除以 2 的结果,满足指标平台常见的需求。
-
简化数据管理 :当需要新增指标时,通过生成列(generated column)的方式,无需重新刷写整个表结构,只需添加新的生成列即可。这样,数据导入依然只涉及原始数据,而衍生指标的计算可以自动完成。
-
提升数据性能 :当原始列的性能不足以满足查询需求时,可以通过物化视图(materialized view)选择性地提升特定数据的性能,而无需对整个数据集进行物化。
-
视图重写能力 :在后续版本中,如 3.2 到 3.3,指标平台引入了视图改写(view rewrite)的能力。这意味着在性能不足时,系统可以自动将逻辑视图转换为物化视图,从而实现性能的透明提升,而无需业务层面进行任何修改。
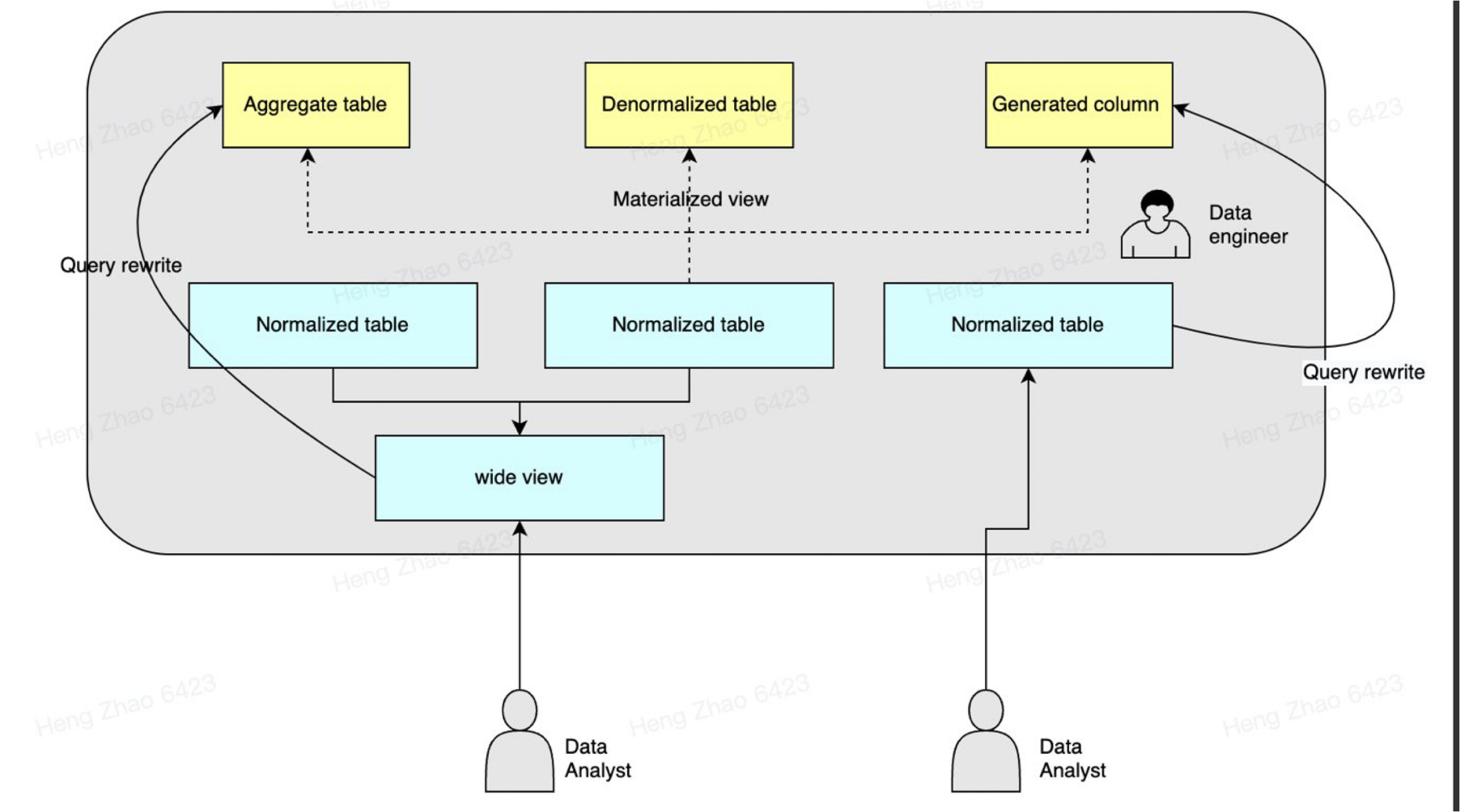
(使用了物化视图、生成列和视图裁剪能力的 Minerva)
某股份制银行
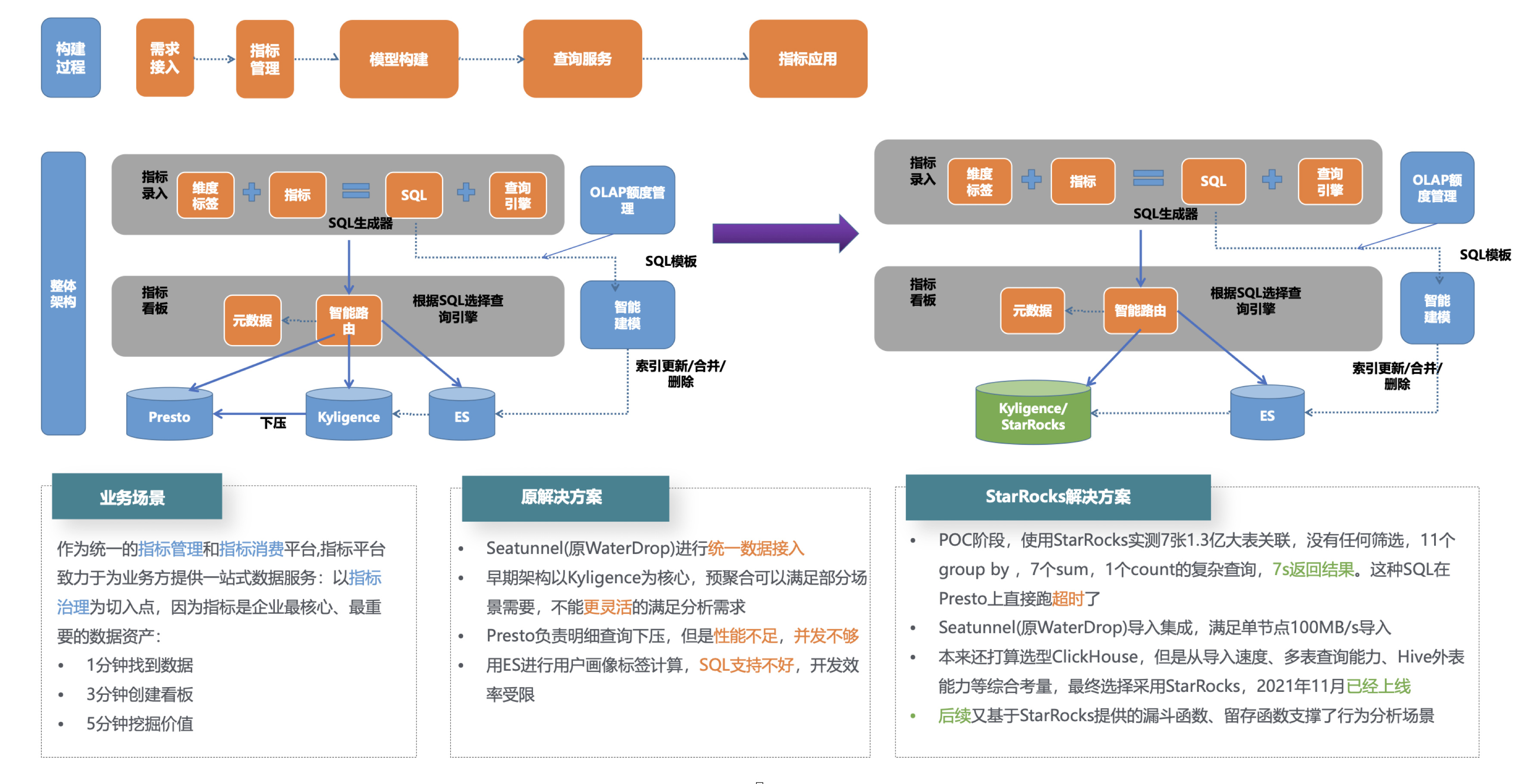
- 最初,这家银行的指标平台依赖于 Presto、Apache Kylin(简称 Kylin)和 Kyligence。但随着时间的推移,Presto 在处理大型数据表和复杂查询时暴露出性能不足,经常遇到超时问题。平台的复杂性增加,涉及更多指标维度和衍生方法,以及更广泛的业务服务,这使得 Kylin 构建 Cube 时的性能问题逐渐显现,特别是在 Cube 构建过程中的性能开销较大。
(引入 StarRocks 后的指标平台架构)
为了提升指标查询的性能,该银行引入了 StarRocks 作为对 Kylin 的补充。StarRocks 的引入显著增强了外表查询的性能,通过物化视图创建了一个透明的指标层,进一步优化了整体的查询效率。这种架构不仅提高了查询速度,还为平台的深入优化提供了新的可能性。
在性能优化方面,银行制定了一套策略,根据指标的行数来决定是否进行物化处理,以及如何实施物化。这一策略根据不同的场景和需求采取了不同的优化策略。例如,在逻辑层定义原子指标,然后通过物化视图对单个或多个指标进行物化。也可以合并一些常一起使用的原子指标,以提高查询效率。
在进行物化视图的测试中,即使在相同的聚合条件下,StarRocks 相比其他解决方案仍然展现出了一定的性能提升。
指标平台案例总结
从上面两个案例,我们能够看到指标平台构建的相同点和差异:
-
Airbnb 和银行用户都在 Hive 或 Iceberg 的湖上构建了统一的指标平台,不仅仅有根据指标定义预计算的需求,同时也有新指标无法命中预计算而直接查询湖上数据的需求。
-
最初,人们倾向于通过预构建的方式事先规划所有指标,但随着业务复杂度增加,从自助分析反向将指标落回到指标平台变得越来越常见。
-
Airbnb 通过外部表将物化视图做到 DWD 层,使用 Colocated 的能力降低 Join 的开销,保证了灵活性和性能;银行用户会则是将指标上卷到高维度的原子指标,以满足高并发的 API 接口服务要求,然后通过合并原子指标的方式降低 MV 的数量,节约成本。
综合来看,无论采用何种模式,都可以看到物化视图的核心价值。 通过结合预先定义的模型和按需创建的模型,减少了对多层建模的依赖,从而提升了效率和性能。物化视图的推荐和合并就是最大程度的在实时计算和预计算之间找到适当的平衡点。
从指标平台加速看新一代建模方式
通过指标平台的案例,我们来回顾我们的建模方式,我们总结了三种不同的建模范式:
三种建模方式与物化视图的关系
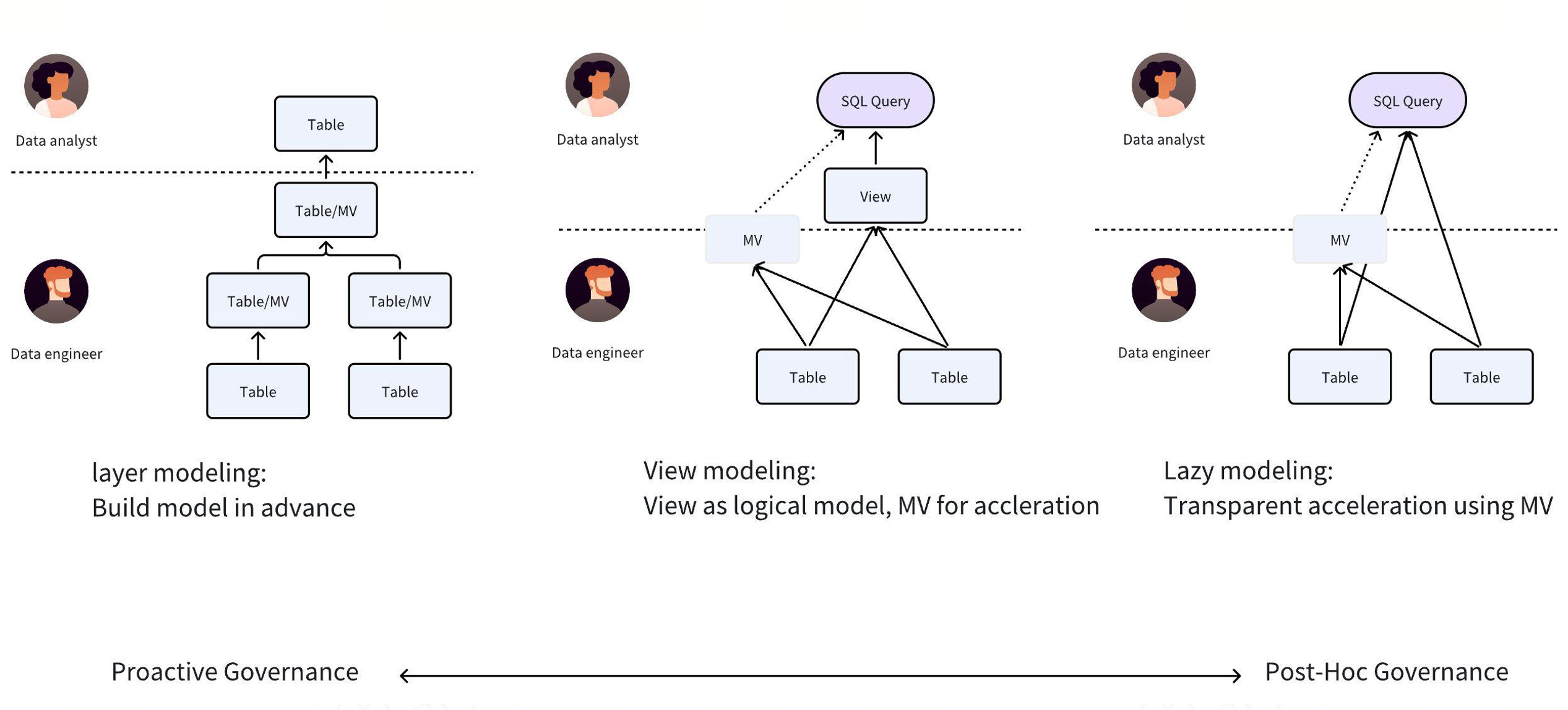
不同层次的建模方式与物化视图之间存在密切关系。
-
分层建模 (Layer modeling) : 是一个事前治理的结构,事先规划好业务层次结构,定义共通的宽表或指标,并逐层定义。虽然这种方式可以良好运作,但对工程师的要求较高,且随着业务变化快速,前期规划的内容可能会失效或变得不再适用,导致数据资产价值下降。
-
延迟建模 (Lazy modeling) : 是一个事后建模的方式,先通过 Adhoc 查询外部表,然后根据查询性能不佳的情况,按需构建物化视图来加速查询。
-
视图建模 (View modeling) : 是一个折中的方案,业务人员可通过逻辑视图先进行建模,然后按需地利用 MV 加速。这种方式不仅可以减少业务人员对底层复杂关系的理解难度,还能让开发人员根据实际查询情况或自动化工具的推荐情况,按需创建物化视图。
从分层建模到视图建模
Kylin 的 Cube 是分层建模中的典型代表,它通过预先定义的层次结构来组织数据。相比之下,StarRocks 的物化视图技术是视图建模的核心,它通过直接在查询时构建数据视图来优化性能和灵活性。以下表格详细比较了这两者的特点和差异:

Kylin 的底层数据来源于 Hive,而且依赖一个单独的 Spark 集群来做 Cube 的预计算;相比之下,StarRocks 既可以直接查询 Hive,提供灵活的自助分析,也能够基于 Hive 构建灵活的外表物化视图,提供更好的统一分析能力。
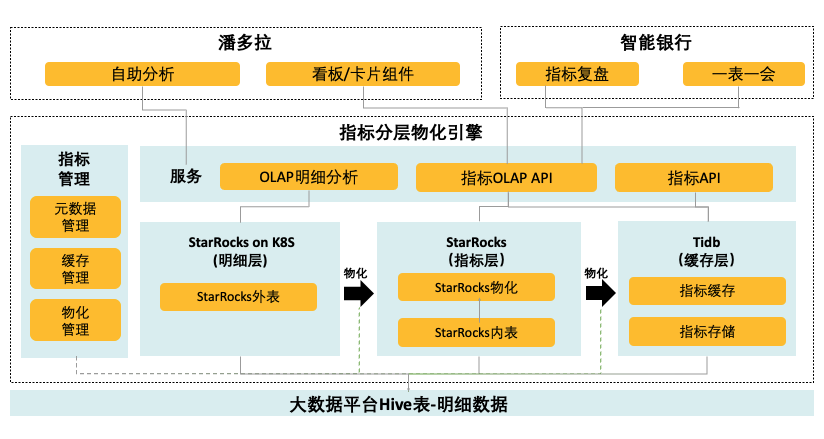
某头部连锁餐饮企业案例
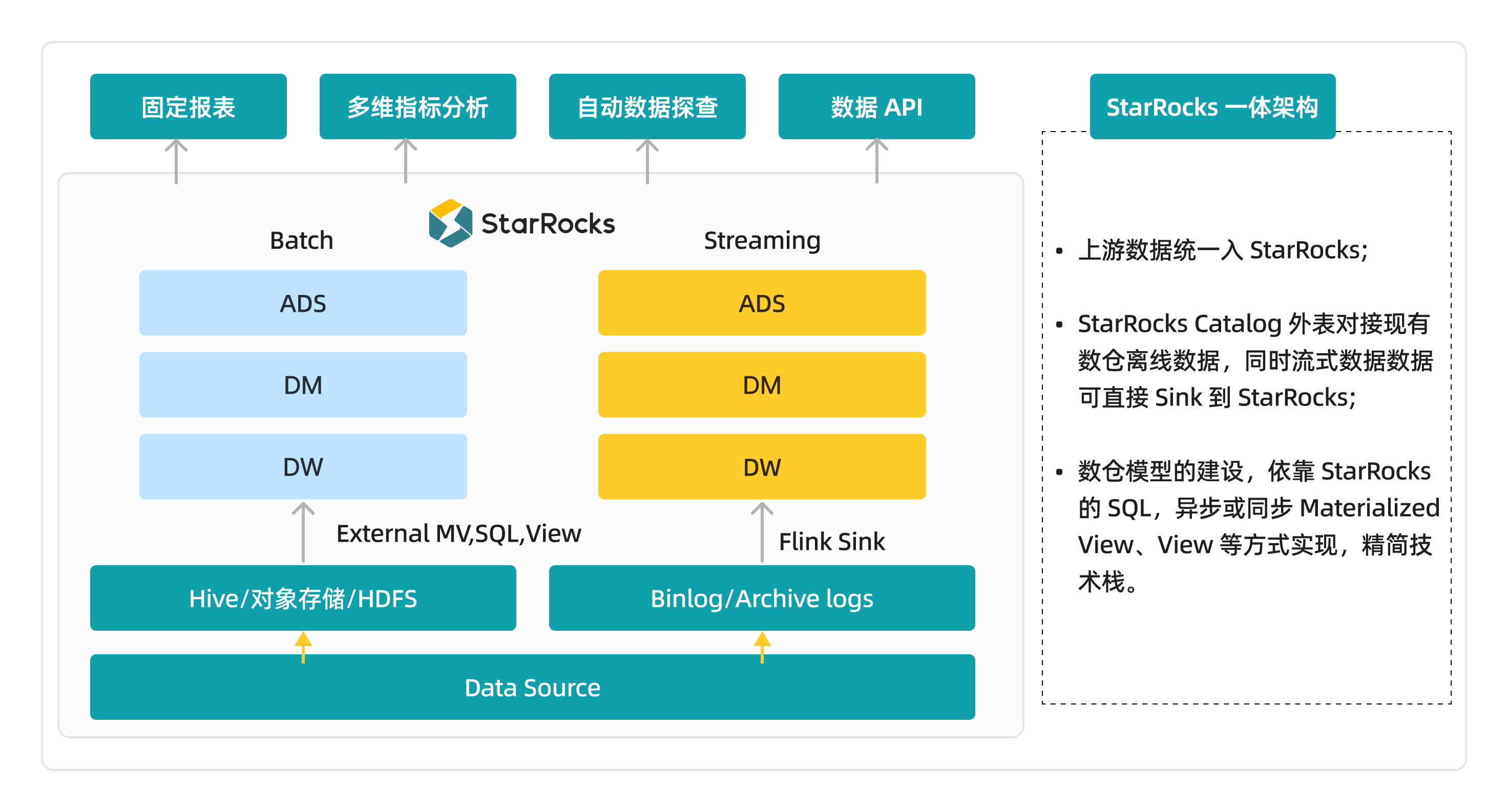
(引入 StarRocks 后的指标平台架构)
初始架构与其问题:
用户早期使用的是 Kylin 和 Impala 的结合方案,这个架构在用户场景下存在以下痛点:
-
Kylin 中包含几百个 Cube,单个 Cube 的数据量达到上亿级别,导致构建时间过长,通常需要几个小时甚至到隔天早上才能完成构建。
-
未命中 Cube 的查询降级为 Hive 查询,查询速度非常慢。即使命中 Cube,查询速度也取决于具体查询的复杂程度和索引的粒度。
引入 StarRocks 显著提高了效率,具体表现在以下几个方面:
-
利用基于 Hive catalog 的物化视图,直接将大宽表提供给用户,性能不佳时再进一步优化。
-
外部表物化视图的第一层采用 Kylin 的 Spark 构建 SQL,只需简单修改 SparkSQL 即可完成宽表构建。对于一些 Cube,我们选择放弃原有的方法,转而使用外部表查询来满足需求,最终精简至保留 50 个 MV。
-
构建时间 大幅缩短, 从原来的 7-9 个小时降至 1.5 小时, 无需额外的 Spark 资源,实现了对现有 StarRocks 集群资源的有效复用。
-
大部分查询能够在 1 秒内完成,即便是涉及两年数据的多表 Join 查询,也能在 7-8 秒内得到结果。
-
迁移至 StarRocks 后,指标开发周期显著缩短,从 3.5 天减少到 1.5 天, 简化了供应商的开发流程。
迁移方案:
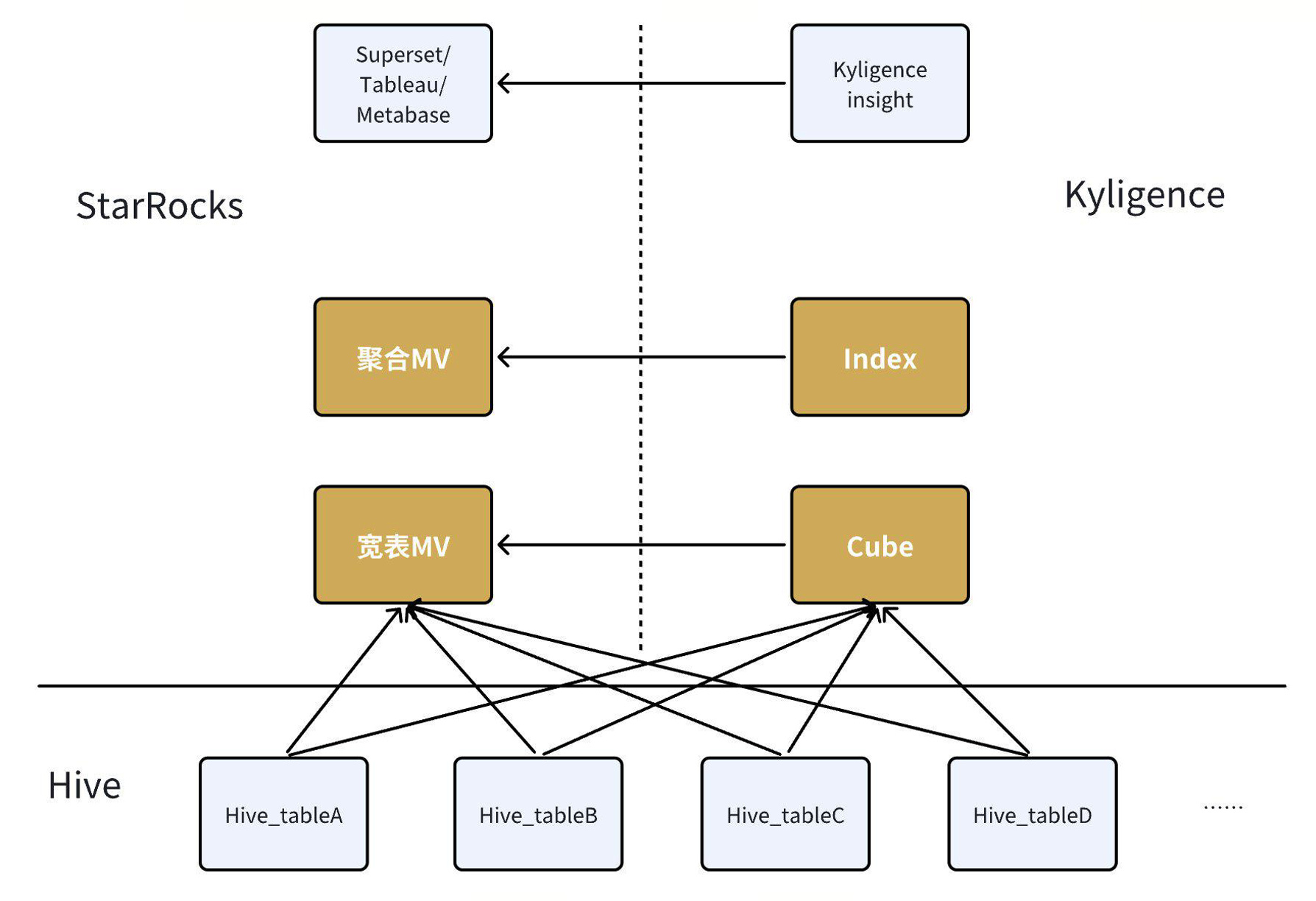
对于现有系统,我们可以通过标准化的方法从 Kylin 迁移到 StarRocks。在 Kylin 中,存在 Cube 和 Index 索引这两个核心概念,它们分别类似于数仓建模中的 DWS(数据服务层)和 ADW(应用数据层)。我们可以通过使用 StarRocks 的宽表物化视图来替代 Cube 构建,并利用上层聚合的物化视图来取代 Cube 之上的 Index 索引,实现系统的平滑过渡和性能提升。
替换的步骤如下:
-
替换 Cube 任务:在 Kylin 中的 Spark 任务可以直接替换成 MV 的 as 语句。参数设置上这个语句几乎不需要做太多改动,因为 Cube 的构建通常比较简单,主要是几个多表 Join 和聚合操作,这些语法都是完全兼容的。构建 MV 时可以额外增加一些参数,比如 partition_refresh_number,它主要控制了每次构建物化视图时刷新多少个分区。
-
替换 Index 索引 :这里 Kylin 的 index 就是一个宽表的上卷任务,我们只需要创建一个单表的 MV,按照维度group by,计算出对应的指标即可,通过嵌套的 MV 可以自动进行数据变更后的刷新任务。
物化视图的构建工作可以通过企业版的 AutoMV 功能进行推荐,降低物化视图编写 SQL 的成本。此外,我们还支持各种刷新策略,可以根据不同的场景进行配置,以尽量减少数据的变更。这里不详细论述,可以参考StarRocks相关文档。
StarRocks 物化视图的愿景
StarRocks 物化视图是加快数据分析的关键特性,它在多种场景中发挥着至关重要的作用。社区也正不断改进物化视图的性能,以更好地支持 StarRocks 湖仓分析新范式,实现我们对 “One Data,All Analytics” 的承诺。
因此,我们希望 StarRocks 物化视图最终能实现以下目标:
-
湖仓融合的桥梁: 通过外表物化视图,用户无需手动导入数据,实现了湖仓的透明加速,数据湖和数仓两者的融合连接将更加高效。
-
批流一体的统一封装: 通过单一的 SQL 语句实现批量数据刷新与增量计算,使批处理和流处理能够无缝衔接,降低了数据处理的复杂性。1
-
传统 ETL 的替代 :采用声明式的方法取代传统的过程式操作,降低数据开发的门槛,提高开发效率,并与现代指标平台的构建理念相契合。
最后,如果你想更近一步了解 StarRocks 的使用案例,欢迎阅读以下文章: