
【详述】问题详细描述
【背景】做过哪些操作?
【业务影响】
【是否存算分离】
【StarRocks版本】3.2.4
【集群规模】 3fe +3be(fe与be混部)
【机器信息】 48C/250G/万兆
【联系方式】
注:外部表指向的是greenplum数据库
仅仅是统计了一下数量,总数据量才50w
通过resouce创建的外部表查询只需要0.3s ,sql如下:
select count(*) from ods.dot_logistics_return_apply_ex;
通过catalog去查询同样的外部表却需要5s,差距非常大, sql如下:
select count(*) from catalog11.stg.stg_ydky_dot_logistics_return_apply;
如果将外部表插入sr的表里,差距更大。
catalog提供了方便,但是在效率上为何差距如此之大?
jdbc外部表ddl如下:
CREATE EXTERNAL TABLE dot_logistics_return_apply_ex (
modify_date datetime NULL COMMENT “”,
logistics_id bigint(20) NULL COMMENT “”,
apply_site_code int(11) NULL COMMENT “”,
apply_user_code varchar(400) NULL COMMENT “”,
apply_type smallint(6) NULL COMMENT “”,
apply_reason int(11) NULL COMMENT “”,
apply_status smallint(6) NULL COMMENT “”,
volume decimal(10, 4) NULL COMMENT “”,
gross_weight decimal(10, 2) NULL COMMENT “”,
settlement_total_number decimal(10, 2) NULL COMMENT “”,
item_total_number int(11) NULL COMMENT “”,
acceptance_site_code int(11) NULL COMMENT “”,
remarks varchar(400) NULL COMMENT “”,
new_logistics_id varchar(400) NULL COMMENT “”,
operate_site_code int(11) NULL COMMENT “”,
operate_time datetime NULL COMMENT “”,
operate_user_code varchar(400) NULL COMMENT “”,
create_time datetime NULL COMMENT “”
) ENGINE=JDBC
PROPERTIES (
“resource” = “resource11”,
“table” = “stg.stg_ydky_dot_logistics_return_apply”
);
profile差异如下:
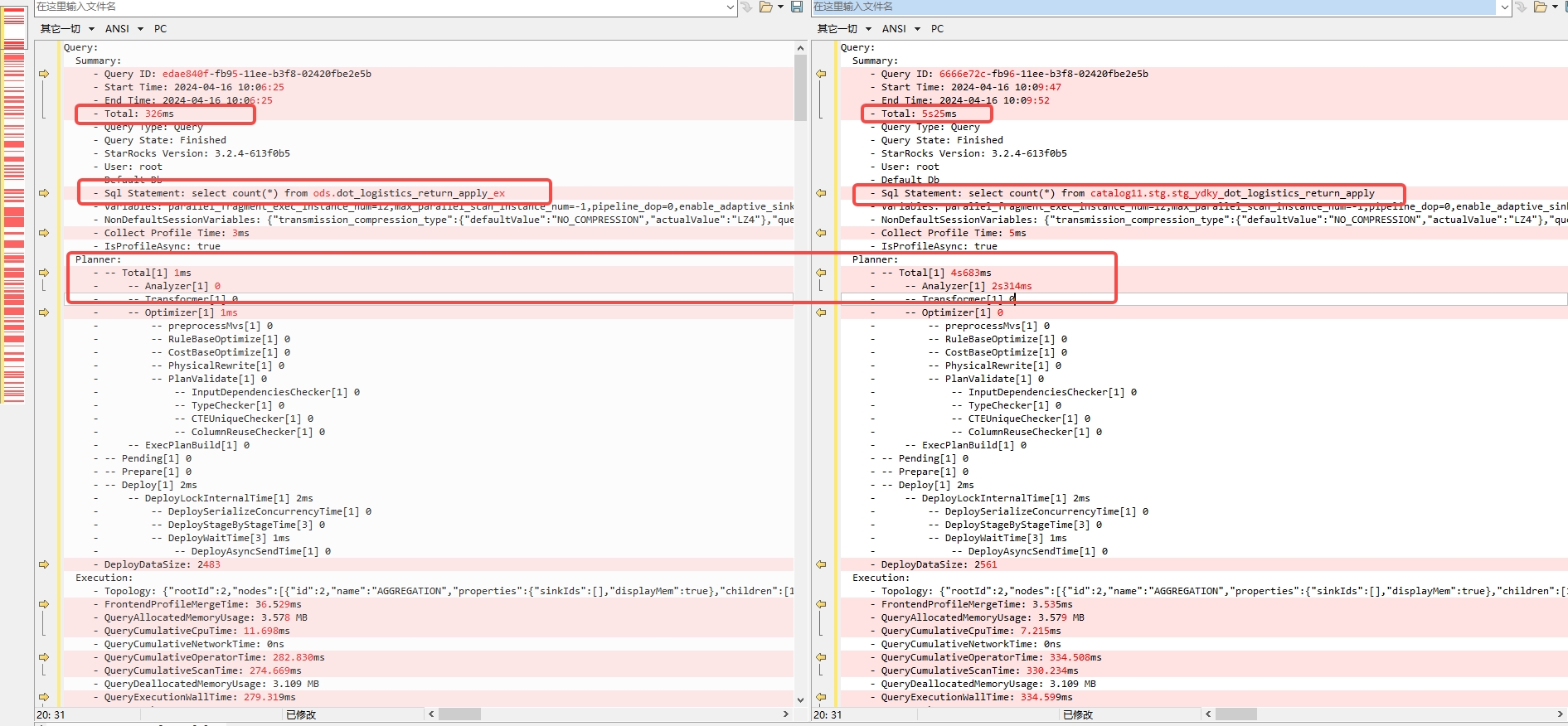
profile文件:
catalog11.stg.stg_ydky_dot_logistics_return_apply.txt (20.0 KB) dot_logistics_return_apply_ex.txt (20.0 KB)