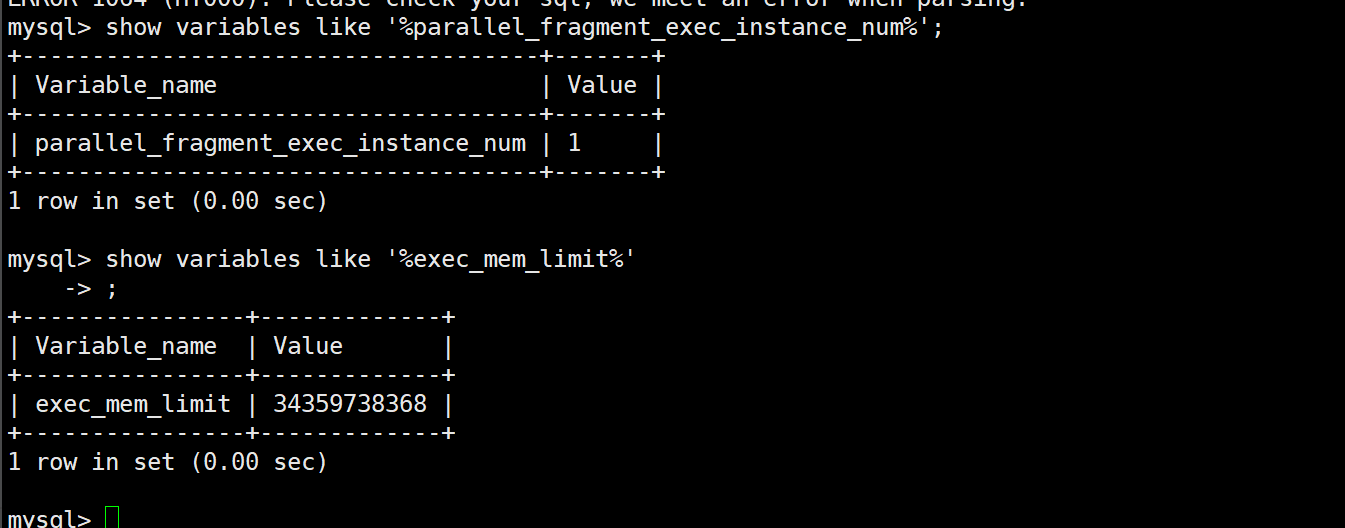
【详述】慢查询。。在实际生产中发现sql运行很慢
表信息:三张表 a b c连续left join 数据量:a三百万,b表 1千,c表2千万, sql运行时长大概需要六分钟,c表为拉链表 join条件为: a.key = c.key and a.number between c.start and c.end
下面的profile是把条件范围缩小 执行了6分钟成功的慢查询 :实际a表全表有1.5亿 限制后 只有三百万
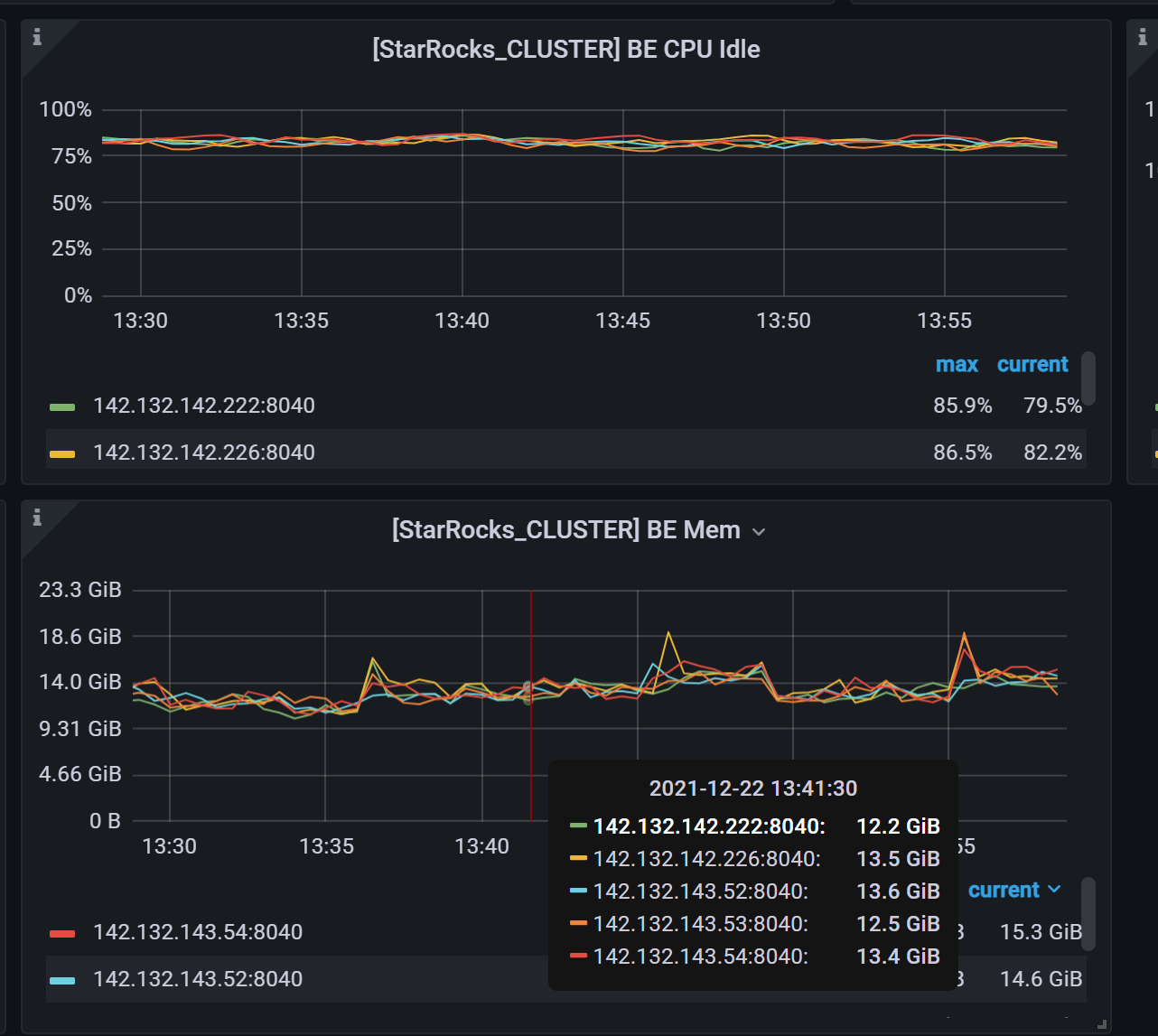
监控观察cpu和mem资源又很空闲,前来请教大佬
【StarRocks版本】例如:1.19.2
【集群规模】例如:3fe+5be
【机器信息】32core+128 mem
【附件】
- 慢查询:
- Profile信息:
6miu.html (88.9 KB)
- Profile信息:
監控信息: