
【详述】在用group by cube的时候,如果select语句里有 split,结果就不对
【背景】用group by cube进行统计, select的字段里有一个用到了split
【业务影响】
【StarRocks版本】例如:1.18.0
【集群规模】:3fe(3 follower)+5be(fe与be混部)
【机器信息】
【附件】
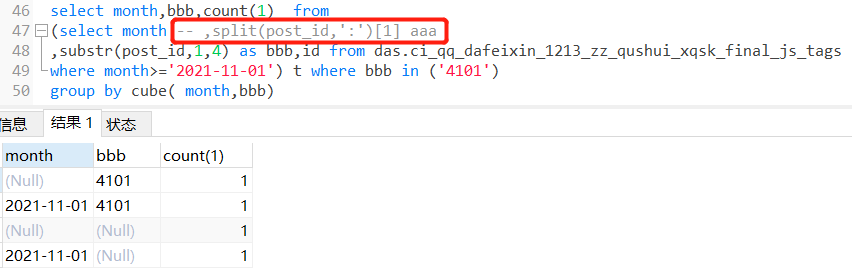
正确结果
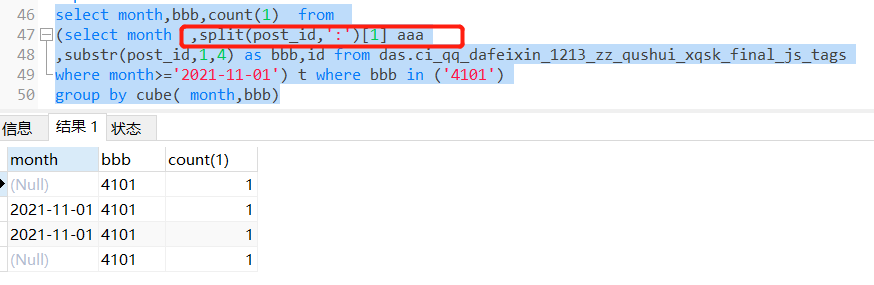
错误结果
建表语句
CREATE TABLE xxx (
id varchar(100) ,
month date ,
post_id varchar(200)
) ENGINE=OLAP
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 32
PROPERTIES (
“replication_num” = “3”,
“in_memory” = “false”,
“storage_format” = “DEFAULT”
);
正确的explain
WORK ON CBO OPTIMIZER
PLAN FRAGMENT 0
OUTPUT EXPRS:2: month | 31: substr | 32: count(1)
PARTITION: UNPARTITIONED
RESULT SINK
7:EXCHANGE
use vectorized: true
PLAN FRAGMENT 1
OUTPUT EXPRS:
PARTITION: HASH_PARTITIONED: 2: month, 31: substr, 33: GROUPING_ID
STREAM DATA SINK
EXCHANGE ID: 07
UNPARTITIONED
6:Project
| <slot 32> : 32: count(1)
| <slot 2> : 2: month
| <slot 31> : 31: substr
| use vectorized: true
|
5:AGGREGATE (merge finalize)
| output: count(32: count(1))
| group by: 2: month, 31: substr, 33: GROUPING_ID
| use vectorized: true
|
4:EXCHANGE
use vectorized: true
PLAN FRAGMENT 2
OUTPUT EXPRS:
PARTITION: RANDOM
STREAM DATA SINK
EXCHANGE ID: 04
HASH_PARTITIONED: 2: month, 31: substr, 33: GROUPING_ID
3:AGGREGATE (update serialize)
| STREAMING
| output: count(1)
| group by: 2: month, 31: substr, 33: GROUPING_ID
| use vectorized: true
|
2:REPEAT_NODE
| repeat: repeat 3 lines [[], [31], [2], [2, 31]]
| use vectorized: true
|
1:Project
| <slot 2> : 2: month
| <slot 31> : substr(8: post_id, 1, 4)
| use vectorized: true
|
0:OlapScanNode
TABLE: ci_qq_dafeixin_1213_zz_qushui_xqsk_final_js_tags
PREAGGREGATION: ON
PREDICATES: substr(8: post_id, 1, 4) = ‘4101’, 2: month >= ‘2021-11-01’
partitions=1/1
rollup: ci_qq_dafeixin_1213_zz_qushui_xqsk_final_js_tags
tabletRatio=32/32
tabletList=6944868,6944872,6944876,6944880,6944884,6944888,6944892,6944896,6944900,6944904 …
cardinality=750200
avgRowSize=2.0
numNodes=0
use vectorized: true
错误的explain
PLAN FRAGMENT 0
OUTPUT EXPRS:<slot 8> month | <slot 9> bbb | <slot 11> count(1)
PARTITION: UNPARTITIONED
RESULT SINK
5:EXCHANGE
use vectorized: true
PLAN FRAGMENT 1
OUTPUT EXPRS:
PARTITION: HASH_PARTITIONED: <slot 8> month, <slot 9> bbb, <slot 10> GROUPING_ID
STREAM DATA SINK
EXCHANGE ID: 05
UNPARTITIONED
4:AGGREGATE (merge finalize)
| output: count(<slot 11> count(1))
| group by: <slot 8> month, <slot 9> bbb, <slot 10> GROUPING_ID
| use vectorized: true
|
3:EXCHANGE
use vectorized: true
PLAN FRAGMENT 2
OUTPUT EXPRS:
PARTITION: RANDOM
STREAM DATA SINK
EXCHANGE ID: 03
HASH_PARTITIONED: <slot 8> month, <slot 9> bbb, <slot 10> GROUPING_ID
2:AGGREGATE (update serialize)
| STREAMING
| output: count(1)
| group by: default_cluster:das.ci_qq_dafeixin_1213_zz_qushui_xqsk_final_js_tags.month, substr(post_id, 1, 4), GROUPING_ID
| use vectorized: true
|
1:REPEAT_NODE
| repeat: repeat 3 lines [[], [0], [], [0]]
| generate: GROUPING_ID
| use vectorized: true
|
0:OlapScanNode
TABLE: ci_qq_dafeixin_1213_zz_qushui_xqsk_final_js_tags
PREAGGREGATION: ON
PREDICATES: default_cluster:das.ci_qq_dafeixin_1213_zz_qushui_xqsk_final_js_tags.month >= ‘2021-11-01’, substr(post_id, 1, 4) IN (‘4101’)
partitions=1/1
rollup: ci_qq_dafeixin_1213_zz_qushui_xqsk_final_js_tags
tabletRatio=32/32
tabletList=6944868,6944872,6944876,6944880,6944884,6944888,6944892,6944896,6944900,6944904 …
cardinality=0
avgRowSize=0.0
numNodes=1
use vectorized: true