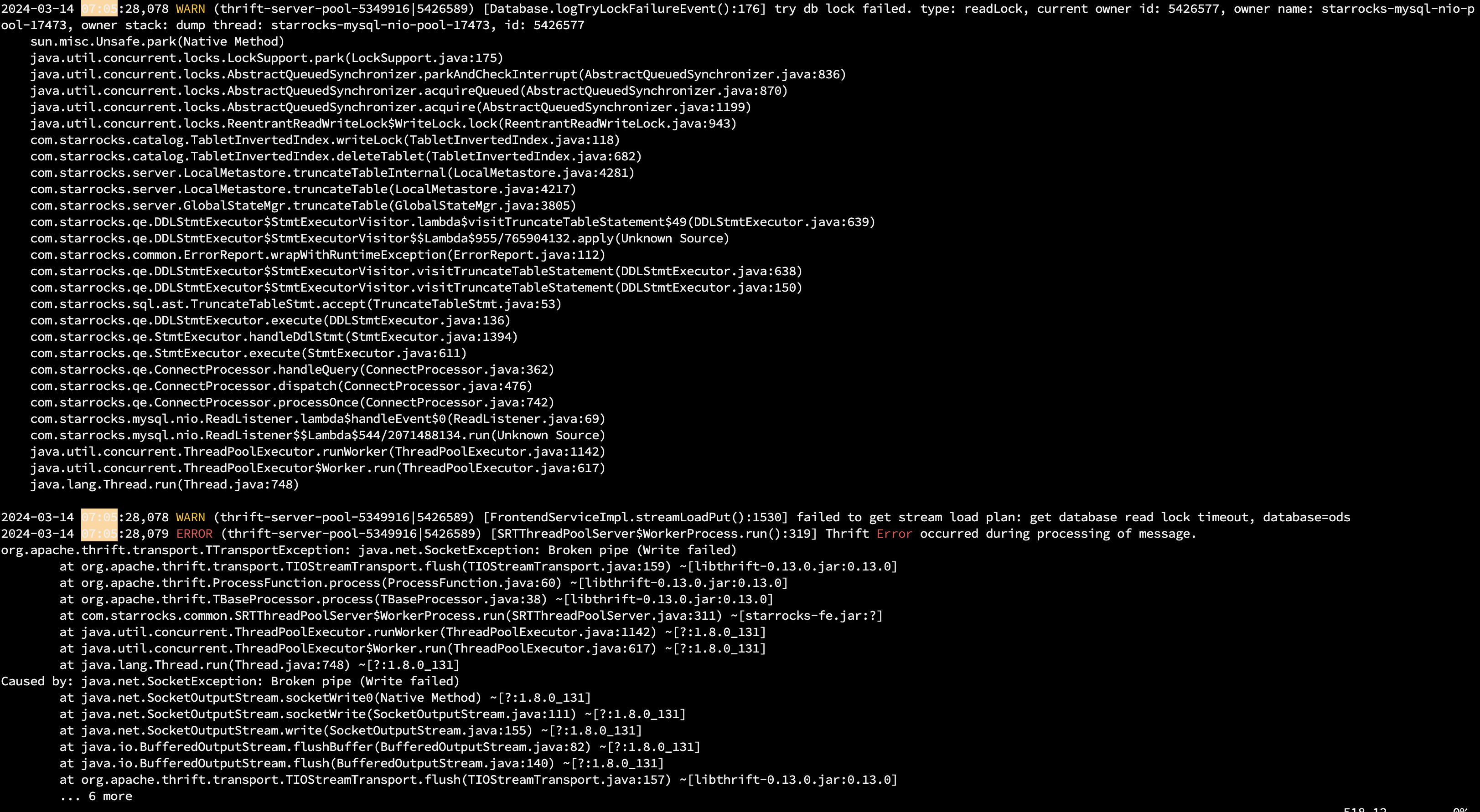
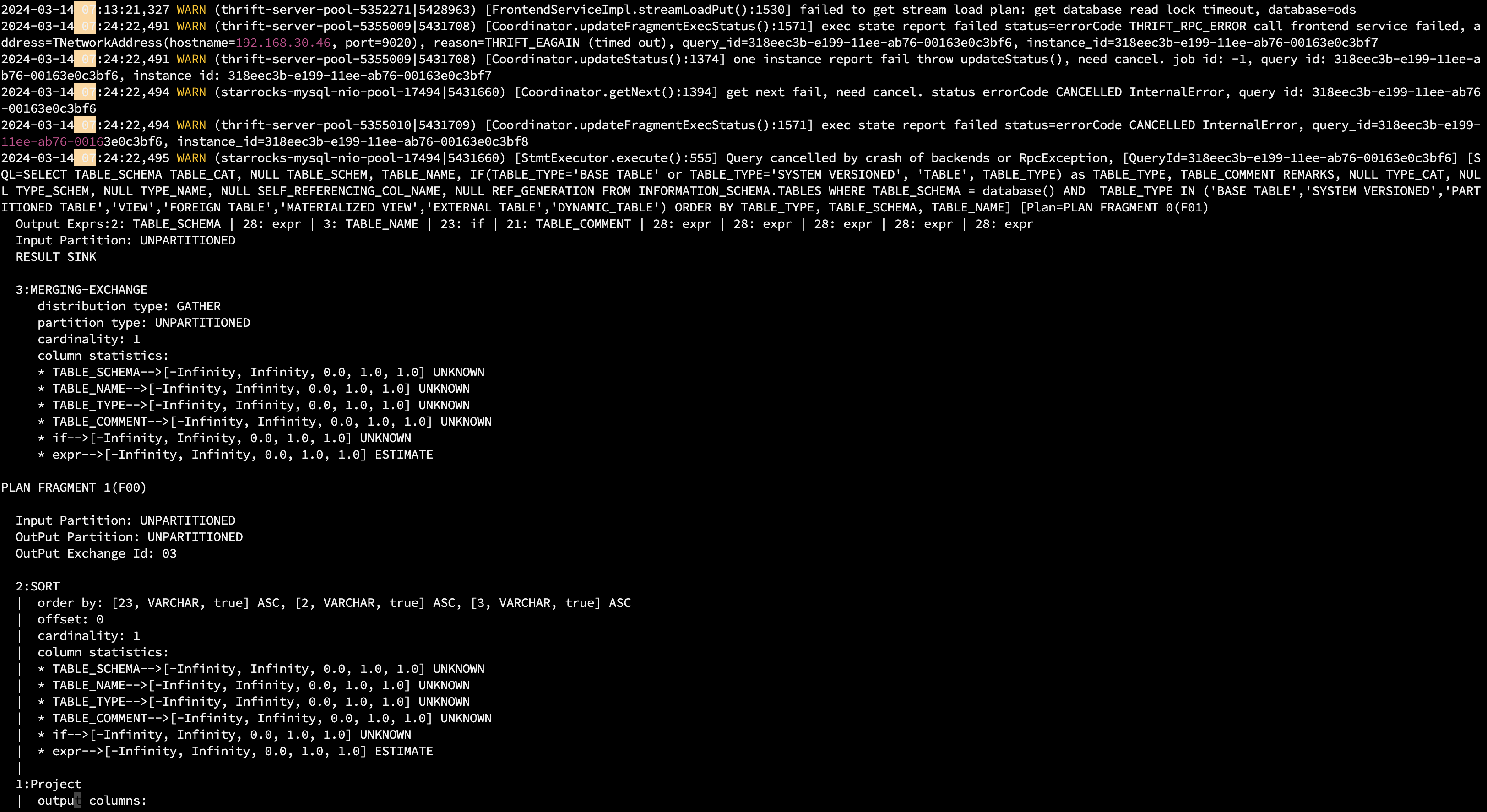
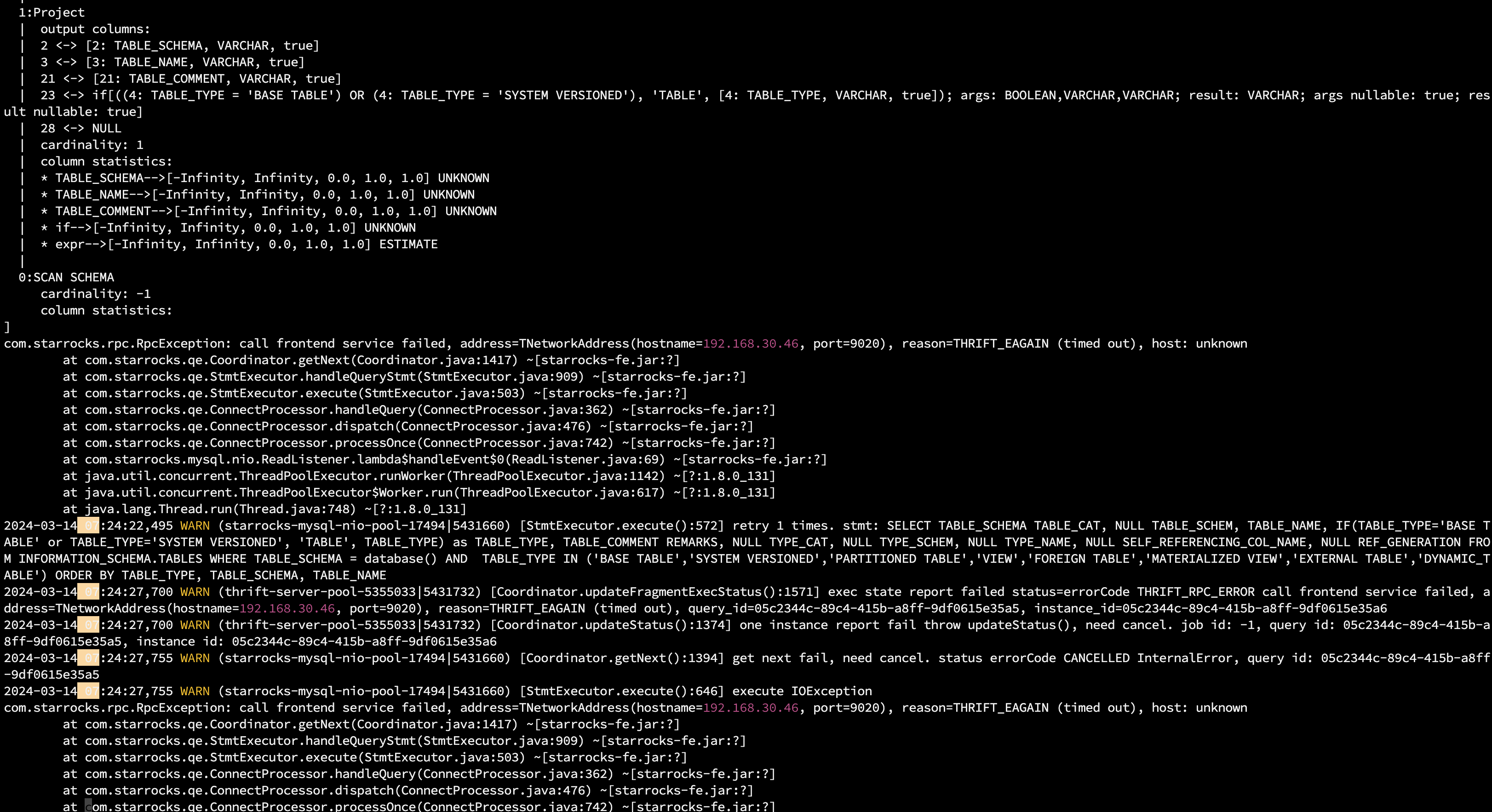
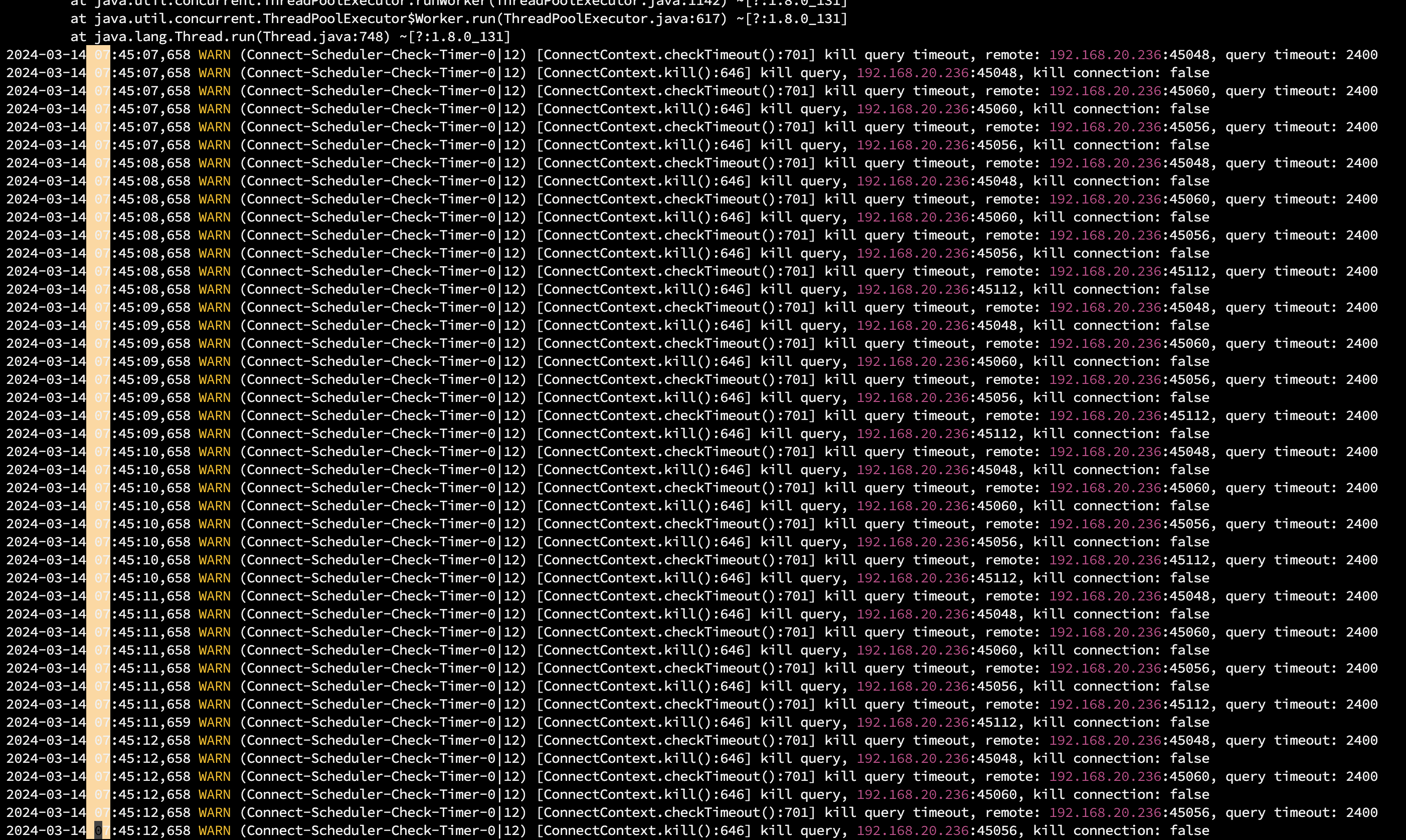
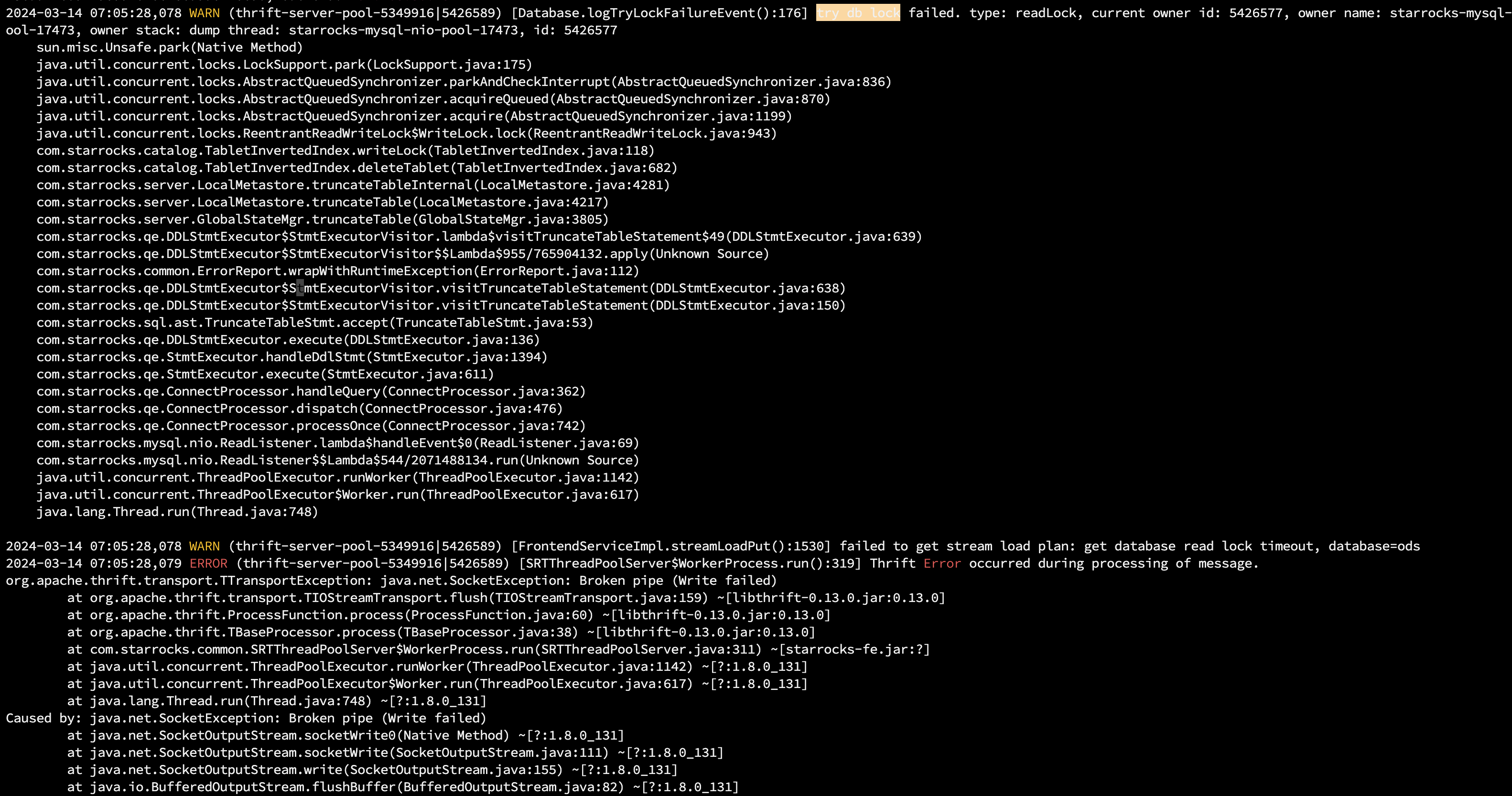
【详述】早上starrocks集群突然无法正常使用,所有导入任务都失败了,查了日志发现是fe leader异常,用的3个节点的fe,但leader并没有自动更新掉,造成业务异常。看日志大多数出现的try db lock failed. type: readLock。所有的数据写入任务都超时被杀掉了。同时监控在7点05分就显示节点dead了。
【背景】常规调度数据导入
【业务影响】无法使用
【是否存算分离】否
【StarRocks版本】3.1.2
【集群规模】3fe+3be(fe与be混部)
【机器信息】8C/64G
【联系方式】yuyii@qq.com
【附件】
fe.log:
fe.warn.log