为了更快的定位您的问题,请提供以下信息,谢谢
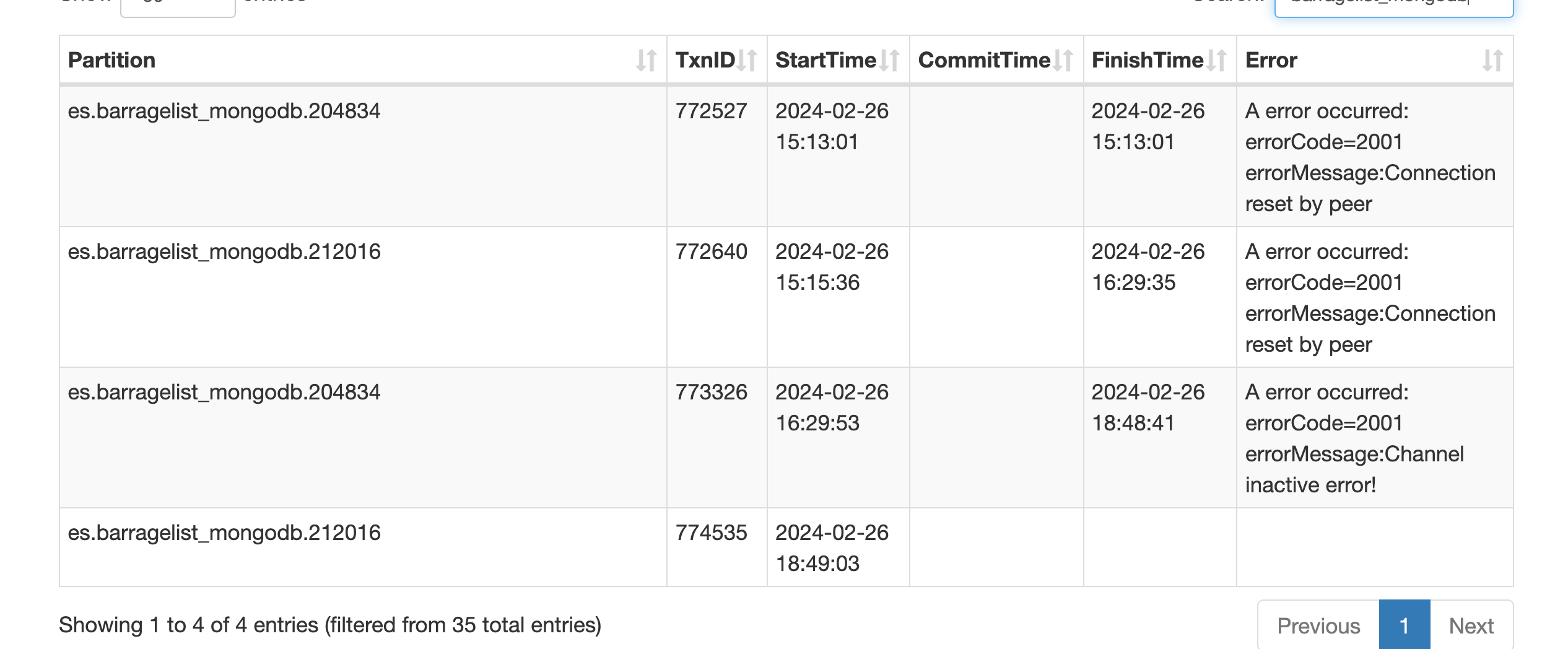
【详述】我从 oss 目录导入 json 文件 到 sr,每年大概有6亿条数据, 每次导入一年的。表名称为 es.barragelist_mongodb. 最近失败n多次,都是装载失败。
【背景】为了 提升查询效率, 我以年份作为分区,每个分区生成 1024 个bucket,计划保存最近7年的数据,
为了提升导入效率,执行了 update information_schema.be_configs set value = 16 where name like ‘flush_thread_num_per_store’。
导入效率明显提升,但是到最后关头总会失败,发现是内存受限, 新增了一个节点,修改了 load 的内存限制到50%, 因为目前查询很少,只有一个导数任务,理论上不会有问题。
修改之后发现还是内存受限。发现随着load_limit 的提升, 导入使用的内存也更多, 这个时候因为barragelist_mongodb 表已经导入了2018和2019两个分区。导致会不停的执行compaction操作,每次都是失败,然后重试。
load操作和 compaction 最终占用的内存超过限制,导致任务失败。load 任务失败后, compaction的内存占用也变得很小。
【业务影响】
【是否存算分离】
【StarRocks版本】3.2.3
【集群规模】1 fe + 2 be
【机器信息】16核 128G
【表模型】主键模型
【导入或者导出方式】从oss 导入json文件,使用 load data infile
操作命令:
LOAD LABEL barragelist_mongodb_from_oss_all_2020
(
DATA INFILE(“s3://enlightent-backup/es-cluster/barragelist-mongodb/barragelist-mongodb/2020*/*”)
INTO TABLE barragelist_mongodb
FORMAT AS “JSON”
(updateTime, channel, name, index, @timestamp, mongoId, userId, channelType, startTime, mDanmuId, content, upCount, createTime, type)
set(updateday=from_unixtime(createTime/1000, ‘%Y-%m-%d’))
)
WITH BROKER
(
“aws.s3.enable_ssl” = “false”,
“aws.s3.use_instance_profile” = “false”,
“aws.s3.region” = “cn-beijing”,
“aws.s3.endpoint” = “https://oss-cn-beijing-internal.aliyuncs.com”,
“aws.s3.access_key” = “*********xxxx”,
“aws.s3.secret_key” = “xxxxxxuDJc7l”
)
PROPERTIES
(
“timeout” = “100000”,
“max_filter_ratio” = “0.1”
);
type:LOAD_RUN_FAIL; msg:Memory of process exceed limit. Pipeline Backend: 172.16.100.42, fragment: 373682ca-25ce-408b-86ed-e3ccf8f178f7 Used: 56931348088, Limit: 56696658001. Mem usage has exceed the limit of BE
type:LOAD_RUN_FAIL; msg:Memory of process exceed limit. try consume:1572864 Used: 40131672848, Limit: 50728566804. Mem usage has exceed the limit of BE
 :supervise_thread()
:supervise_thread()