为了更快的定位您的问题,请提供以下信息,谢谢
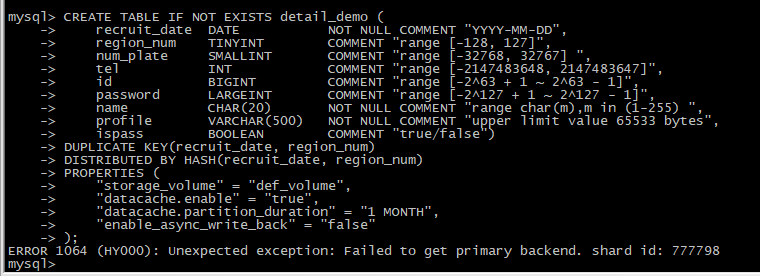
【详述】搭建完集群后发现建表报错。ERROR 1064 (HY000): Unexpected exception: Failed to get primary backend. shard id: 777798
【背景】查询cn 节点均正常活着,但是fe.log 中有 sending heartbeat to worker bigdata01:9070 failed, GRPC:DEADLINE_EXCEEDED: Deadline exceeded after 4.999970552s. .和 Error: WorkerGroup 0 doesn’t have alive workers等日志内容
【业务影响】
【是否存算分离】存算分离
【StarRocks版本】例如:3.2
【集群规模】例如:5fe+5cn(fe与cn混部)
【机器信息】CPU虚拟核/内存/网卡,例如:48C/64G/万兆
【联系方式】wujingchao-jn@ruiyinxin.com
【附件】
fe.log:
2024-02-26 13:18:24,812 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():110] sending heartbeat to worker bigdata01:9070 failed, GRPC:DEADLINE_EXCEEDED: Deadline exceeded after 4.999970552s. .
2024-02-26 13:18:29,816 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():94] caught GRPC exception when sending heartbeat to worker bigdata02:9070, io.grpc.StatusRuntimeException: DEADLINE_EXCEEDED: Deadline exceeded after 4.999971305s. .
2024-02-26 13:18:29,817 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():110] sending heartbeat to worker bigdata02:9070 failed, GRPC:DEADLINE_EXCEEDED: Deadline exceeded after 4.999971305s. .
2024-02-26 13:18:33,366 INFO (statistics meta manager|36) [StatisticsMetaManager.createSampleStatisticsTable():139] create sample statistics table start
2024-02-26 13:18:33,366 INFO (statistics meta manager|36) [Database.checkDataSizeQuota():442] database[statistics] data quota: left bytes: 8388608.000 TB / total: 8388608.000 TB
2024-02-26 13:18:33,366 INFO (statistics meta manager|36) [Database.checkReplicaQuota():453] database[statistics] replica quota: left number: 9223372036854775807 / total: 9223372036854775807
2024-02-26 13:18:33,371 WARN (grpc-default-executor-1079|37173) [ShardManager.createShard():437] Fail to schedule new created shards to default workerGroup for service: 521bc6a5-6438-4970-a8ad-8f468ede2eb0, ignore the error for now. Error:WorkerGroup 0 doesn’t have alive workers
2024-02-26 13:18:33,371 INFO (statistics meta manager|36) [LocalMetastore.buildPartitions():1890] start to build 1 partitions sequentially for table statistics.table_statistic_v1 with 10 replicas
2024-02-26 13:18:33,371 INFO (statistics meta manager|36) [LogRateLimiter.info():43] On-demand schedule [786911] failed. Error: WorkerGroup 0 doesn’t have alive workers
2024-02-26 13:18:33,371 WARN (statistics meta manager|36) [StatisticsMetaManager.createSampleStatisticsTable():161] Failed to create sample statistics, Failed to get primary backend. shard id: 786911
2024-02-26 13:18:33,371 WARN (statistics meta manager|36) [StatisticsMetaManager.refreshStatisticsTable():338] create statistics table table_statistic_v1 failed
2024-02-26 13:18:34,822 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():94] caught GRPC exception when sending heartbeat to worker bigdata03:9070, io.grpc.StatusRuntimeException: DEADLINE_EXCEEDED: Deadline exceeded after 4.999972884s. .
2024-02-26 13:18:34,823 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():110] sending heartbeat to worker bigdata03:9070 failed, GRPC:DEADLINE_EXCEEDED: Deadline exceeded after 4.999972884s. .
2024-02-26 13:18:39,826 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():94] caught GRPC exception when sending heartbeat to worker bigdata04:9070, io.grpc.StatusRuntimeException: DEADLINE_EXCEEDED: Deadline exceeded after 4.999955801s. .
2024-02-26 13:18:39,827 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():110] sending heartbeat to worker bigdata04:9070 failed, GRPC:DEADLINE_EXCEEDED: Deadline exceeded after 4.999955801s. .
2024-02-26 13:18:43,371 INFO (statistics meta manager|36) [StatisticsMetaManager.createSampleStatisticsTable():139] create sample statistics table start
2024-02-26 13:18:43,371 INFO (statistics meta manager|36) [Database.checkDataSizeQuota():442] database[statistics] data quota: left bytes: 8388608.000 TB / total: 8388608.000 TB
2024-02-26 13:18:43,371 INFO (statistics meta manager|36) [Database.checkReplicaQuota():453] database[statistics] replica quota: left number: 9223372036854775807 / total: 9223372036854775807
2024-02-26 13:18:43,375 WARN (grpc-default-executor-1079|37173) [ShardManager.createShard():437] Fail to schedule new created shards to default workerGroup for service: 521bc6a5-6438-4970-a8ad-8f468ede2eb0, ignore the error for now. Error:WorkerGroup 0 doesn’t have alive workers
2024-02-26 13:18:43,376 INFO (statistics meta manager|36) [LocalMetastore.buildPartitions():1890] start to build 1 partitions sequentially for table statistics.table_statistic_v1 with 10 replicas
2024-02-26 13:18:43,376 INFO (statistics meta manager|36) [LogRateLimiter.info():43] On-demand schedule [786924] failed. Error: WorkerGroup 0 doesn’t have alive workers
2024-02-26 13:18:43,376 WARN (statistics meta manager|36) [StatisticsMetaManager.createSampleStatisticsTable():161] Failed to create sample statistics, Failed to get primary backend. shard id: 786924
2024-02-26 13:18:43,376 WARN (statistics meta manager|36) [StatisticsMetaManager.refreshStatisticsTable():338] create statistics table table_statistic_v1 failed
2024-02-26 13:18:43,549 INFO (colocate group clone checker|128) [ColocateTableBalancer.matchGroups():903] finished to match colocate group. cost: 0 ms, in lock time: 0 ms
2024-02-26 13:18:44,830 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():94] caught GRPC exception when sending heartbeat to worker bigdata05:9070, io.grpc.StatusRuntimeException: DEADLINE_EXCEEDED: Deadline exceeded after 4.999973770s. .
2024-02-26 13:18:44,831 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():110] sending heartbeat to worker bigdata05:9070 failed, GRPC:DEADLINE_EXCEEDED: Deadline exceeded after 4.999973770s. .
2024-02-26 13:18:45,227 INFO (leaderCheckpointer|120) [BDBJEJournal.getFinalizedJournalId():275] database names: 150001
2024-02-26 13:18:45,227 INFO (leaderCheckpointer|120) [Checkpoint.runAfterCatalogReady():95] checkpoint imageVersion 150000, checkpointVersion 0
2024-02-26 13:18:46,291 INFO (grpc-default-executor-1080|37217) [LogRateLimiter.info():43] On-demand schedule [11258, 11259, 11260, 11261, 11262, 11263, 11264, 11265, 11266, 11267] failed. Error: WorkerGroup 0 doesn’t have alive workers
2024-02-26 13:18:46,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():43] On-demand schedule [11258] failed. Error: WorkerGroup 0 doesn’t have alive workers
2024-02-26 13:18:47,291 INFO (grpc-default-executor-1080|37217) [LogRateLimiter.info():45] On-demand schedule [29927, 29928, 29929, 29930, 29931, 29932, 29933, 29934, 29935, 29936] failed. Error: WorkerGroup 0 doesn’t have alive workers. [15794 similar messages omitted]
2024-02-26 13:18:48,291 INFO (grpc-default-executor-1080|37217) [LogRateLimiter.info():45] On-demand schedule [46970, 46971, 46972, 46973, 46974, 46975, 46976, 46977, 46978, 46979] failed. Error: WorkerGroup 0 doesn’t have alive workers. [14420 similar messages omitted]
2024-02-26 13:18:49,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [65807] failed. Error: WorkerGroup 0 doesn’t have alive workers. [15939 similar messages omitted]
2024-02-26 13:18:49,835 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():94] caught GRPC exception when sending heartbeat to worker bigdata01:9070, io.grpc.StatusRuntimeException: DEADLINE_EXCEEDED: Deadline exceeded after 4.999972476s. .
2024-02-26 13:18:49,835 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():110] sending heartbeat to worker bigdata01:9070 failed, GRPC:DEADLINE_EXCEEDED: Deadline exceeded after 4.999972476s. .
2024-02-26 13:18:50,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [85816] failed. Error: WorkerGroup 0 doesn’t have alive workers. [16930 similar messages omitted]
2024-02-26 13:18:51,291 INFO (grpc-default-executor-1078|37130) [LogRateLimiter.info():45] On-demand schedule [100569, 100570, 100571, 100572, 100573, 100574, 100575, 100576, 100577, 100578] failed. Error: WorkerGroup 0 doesn’t have alive workers. [12481 similar messages omitted]
2024-02-26 13:18:52,291 INFO (grpc-default-executor-1078|37130) [LogRateLimiter.info():45] On-demand schedule [118743, 118744, 118745, 118746, 118747, 118748, 118749, 118750, 118751, 118752] failed. Error: WorkerGroup 0 doesn’t have alive workers. [15377 similar messages omitted]
2024-02-26 13:18:53,291 INFO (grpc-default-executor-1078|37130) [LogRateLimiter.info():45] On-demand schedule [137502, 137503, 137504, 137505, 137506, 137507, 137508, 137509, 137510, 137511] failed. Error: WorkerGroup 0 doesn’t have alive workers. [15872 similar messages omitted]
2024-02-26 13:18:53,376 INFO (statistics meta manager|36) [StatisticsMetaManager.createSampleStatisticsTable():139] create sample statistics table start
2024-02-26 13:18:53,376 INFO (statistics meta manager|36) [Database.checkDataSizeQuota():442] database[statistics] data quota: left bytes: 8388608.000 TB / total: 8388608.000 TB
2024-02-26 13:18:53,376 INFO (statistics meta manager|36) [Database.checkReplicaQuota():453] database[statistics] replica quota: left number: 9223372036854775807 / total: 9223372036854775807
2024-02-26 13:18:53,381 WARN (grpc-default-executor-1080|37217) [ShardManager.createShard():437] Fail to schedule new created shards to default workerGroup for service: 521bc6a5-6438-4970-a8ad-8f468ede2eb0, ignore the error for now. Error:WorkerGroup 0 doesn’t have alive workers
2024-02-26 13:18:53,381 INFO (statistics meta manager|36) [LocalMetastore.buildPartitions():1890] start to build 1 partitions sequentially for table statistics.table_statistic_v1 with 10 replicas
2024-02-26 13:18:53,381 WARN (statistics meta manager|36) [StatisticsMetaManager.createSampleStatisticsTable():161] Failed to create sample statistics, Failed to get primary backend. shard id: 786937
2024-02-26 13:18:53,381 WARN (statistics meta manager|36) [StatisticsMetaManager.refreshStatisticsTable():338] create statistics table table_statistic_v1 failed
2024-02-26 13:18:54,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [156586] failed. Error: WorkerGroup 0 doesn’t have alive workers. [16149 similar messages omitted]
2024-02-26 13:18:54,840 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():94] caught GRPC exception when sending heartbeat to worker bigdata02:9070, io.grpc.StatusRuntimeException: DEADLINE_EXCEEDED: Deadline exceeded after 4.999980316s. .
2024-02-26 13:18:54,842 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():110] sending heartbeat to worker bigdata02:9070 failed, GRPC:DEADLINE_EXCEEDED: Deadline exceeded after 4.999980316s. .
2024-02-26 13:18:55,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [177282] failed. Error: WorkerGroup 0 doesn’t have alive workers. [17511 similar messages omitted]
2024-02-26 13:18:56,291 INFO (grpc-default-executor-1078|37130) [LogRateLimiter.info():45] On-demand schedule [198355, 198356, 198357, 198358, 198359, 198360, 198361, 198362, 198363, 198364] failed. Error: WorkerGroup 0 doesn’t have alive workers. [17829 similar messages omitted]
2024-02-26 13:18:57,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [220969] failed. Error: WorkerGroup 0 doesn’t have alive workers. [19136 similar messages omitted]
~
lrwxrwxrwx 1 root root 27 Feb 19 11:25 cn.INFO -> cn.INFO.log.20240219-112515
2024-02-26 13:18:45,227 INFO (leaderCheckpointer|120) [Checkpoint.runAfterCatalogReady():95] checkpoint imageVersion 150000, checkpointVersion 0
2024-02-26 13:18:46,291 INFO (grpc-default-executor-1080|37217) [LogRateLimiter.info():43] On-demand schedule [11258, 11259, 11260, 11261, 11262, 11263, 11264, 11265, 11266, 11267] failed. Error: WorkerGroup 0 doesn’t have alive workers
2024-02-26 13:18:46,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():43] On-demand schedule [11258] failed. Error: WorkerGroup 0 doesn’t have alive workers
2024-02-26 13:18:47,291 INFO (grpc-default-executor-1080|37217) [LogRateLimiter.info():45] On-demand schedule [29927, 29928, 29929, 29930, 29931, 29932, 29933, 29934, 29935, 29936] failed. Error: WorkerGroup 0 doesn’t have alive workers. [15794 similar messages omitted]
2024-02-26 13:18:48,291 INFO (grpc-default-executor-1080|37217) [LogRateLimiter.info():45] On-demand schedule [46970, 46971, 46972, 46973, 46974, 46975, 46976, 46977, 46978, 46979] failed. Error: WorkerGroup 0 doesn’t have alive workers. [14420 similar messages omitted]
2024-02-26 13:18:49,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [65807] failed. Error: WorkerGroup 0 doesn’t have alive workers. [15939 similar messages omitted]
2024-02-26 13:18:49,835 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():94] caught GRPC exception when sending heartbeat to worker bigdata01:9070, io.grpc.StatusRuntimeException: DEADLINE_EXCEEDED: Deadline exceeded after 4.999972476s. .
2024-02-26 13:18:49,835 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():110] sending heartbeat to worker bigdata01:9070 failed, GRPC:DEADLINE_EXCEEDED: Deadline exceeded after 4.999972476s. .
2024-02-26 13:18:50,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [85816] failed. Error: WorkerGroup 0 doesn’t have alive workers. [16930 similar messages omitted]
2024-02-26 13:18:51,291 INFO (grpc-default-executor-1078|37130) [LogRateLimiter.info():45] On-demand schedule [100569, 100570, 100571, 100572, 100573, 100574, 100575, 100576, 100577, 100578] failed. Error: WorkerGroup 0 doesn’t have alive workers. [12481 similar messages omitted]
2024-02-26 13:18:52,291 INFO (grpc-default-executor-1078|37130) [LogRateLimiter.info():45] On-demand schedule [118743, 118744, 118745, 118746, 118747, 118748, 118749, 118750, 118751, 118752] failed. Error: WorkerGroup 0 doesn’t have alive workers. [15377 similar messages omitted]
2024-02-26 13:18:53,291 INFO (grpc-default-executor-1078|37130) [LogRateLimiter.info():45] On-demand schedule [137502, 137503, 137504, 137505, 137506, 137507, 137508, 137509, 137510, 137511] failed. Error: WorkerGroup 0 doesn’t have alive workers. [15872 similar messages omitted]
2024-02-26 13:18:53,376 INFO (statistics meta manager|36) [StatisticsMetaManager.createSampleStatisticsTable():139] create sample statistics table start
2024-02-26 13:18:53,376 INFO (statistics meta manager|36) [Database.checkDataSizeQuota():442] database[statistics] data quota: left bytes: 8388608.000 TB / total: 8388608.000 TB
2024-02-26 13:18:53,376 INFO (statistics meta manager|36) [Database.checkReplicaQuota():453] database[statistics] replica quota: left number: 9223372036854775807 / total: 9223372036854775807
2024-02-26 13:18:53,381 WARN (grpc-default-executor-1080|37217) [ShardManager.createShard():437] Fail to schedule new created shards to default workerGroup for service: 521bc6a5-6438-4970-a8ad-8f468ede2eb0, ignore the error for now. Error:WorkerGroup 0 doesn’t have alive workers
2024-02-26 13:18:53,381 INFO (statistics meta manager|36) [LocalMetastore.buildPartitions():1890] start to build 1 partitions sequentially for table statistics.table_statistic_v1 with 10 replicas
2024-02-26 13:18:53,381 WARN (statistics meta manager|36) [StatisticsMetaManager.createSampleStatisticsTable():161] Failed to create sample statistics, Failed to get primary backend. shard id: 786937
2024-02-26 13:18:53,381 WARN (statistics meta manager|36) [StatisticsMetaManager.refreshStatisticsTable():338] create statistics table table_statistic_v1 failed
2024-02-26 13:18:54,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [156586] failed. Error: WorkerGroup 0 doesn’t have alive workers. [16149 similar messages omitted]
2024-02-26 13:18:54,840 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():94] caught GRPC exception when sending heartbeat to worker bigdata02:9070, io.grpc.StatusRuntimeException: DEADLINE_EXCEEDED: Deadline exceeded after 4.999980316s. .
2024-02-26 13:18:54,842 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():110] sending heartbeat to worker bigdata02:9070 failed, GRPC:DEADLINE_EXCEEDED: Deadline exceeded after 4.999980316s. .
2024-02-26 13:18:55,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [177282] failed. Error: WorkerGroup 0 doesn’t have alive workers. [17511 similar messages omitted]
2024-02-26 13:18:56,291 INFO (grpc-default-executor-1078|37130) [LogRateLimiter.info():45] On-demand schedule [198355, 198356, 198357, 198358, 198359, 198360, 198361, 198362, 198363, 198364] failed. Error: WorkerGroup 0 doesn’t have alive workers. [17829 similar messages omitted]
2024-02-26 13:18:57,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [220969] failed. Error: WorkerGroup 0 doesn’t have alive workers. [19136 similar messages omitted]
2024-02-26 13:18:58,291 INFO (grpc-default-executor-1078|37130) [LogRateLimiter.info():45] On-demand schedule [242139, 242140, 242141, 242142, 242143, 242144, 242145, 242146, 242147, 242148] failed. Error: WorkerGroup 0 doesn’t have alive workers. [17910 similar messages omitted]
2024-02-26 13:18:59,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [262172] failed. Error: WorkerGroup 0 doesn’t have alive workers. [16951 similar messages omitted]
2024-02-26 13:18:59,583 INFO (tablet scheduler|45) [TabletScheduler.updateClusterLoadStatistic():483] update cluster load statistic:
2024-02-26 13:18:59,846 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():94] caught GRPC exception when sending heartbeat to worker bigdata03:9070, io.grpc.StatusRuntimeException: DEADLINE_EXCEEDED: Deadline exceeded after 4.999959048s. .
2024-02-26 13:18:59,847 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():110] sending heartbeat to worker bigdata03:9070 failed, GRPC:DEADLINE_EXCEEDED: Deadline exceeded after 4.999959048s. .
2024-02-26 13:19:00,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [282297] failed. Error: WorkerGroup 0 doesn’t have alive workers. [17028 similar messages omitted]
2024-02-26 13:19:00,303 INFO (star mgr LeaderCheckpointer|114) [BDBJEJournal.getFinalizedJournalId():275] database names: 100001
2024-02-26 13:19:00,303 INFO (star mgr LeaderCheckpointer|114) [Checkpoint.runAfterCatalogReady():95] checkpoint imageVersion 100000, checkpointVersion 0
2024-02-26 13:19:01,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [299668] failed. Error: WorkerGroup 0 doesn’t have alive workers. [14698 similar messages omitted]
2024-02-26 13:19:02,291 INFO (grpc-default-executor-1079|37173) [LogRateLimiter.info():45] On-demand schedule [319736, 319737, 319738, 319739, 319740, 319741, 319742, 319743, 319744, 319745] failed. Error: WorkerGroup 0 doesn’t have alive workers. [16978 similar messages omitted]
2024-02-26 13:19:03,291 INFO (grpc-default-executor-1079|37173) [LogRateLimiter.info():45] On-demand schedule [341693, 341694, 341695, 341696, 341697, 341698, 341699, 341700, 341701, 341702] failed. Error: WorkerGroup 0 doesn’t have alive workers. [18578 similar messages omitted]
2024-02-26 13:19:03,382 INFO (statistics meta manager|36) [StatisticsMetaManager.createSampleStatisticsTable():139] create sample statistics table start
2024-02-26 13:19:03,382 INFO (statistics meta manager|36) [Database.checkDataSizeQuota():442] database[statistics] data quota: left bytes: 8388608.000 TB / total: 8388608.000 TB
2024-02-26 13:19:03,382 INFO (statistics meta manager|36) [Database.checkReplicaQuota():453] database[statistics] replica quota: left number: 9223372036854775807 / total: 9223372036854775807
2024-02-26 13:19:03,386 WARN (grpc-default-executor-1074|36996) [ShardManager.createShard():437] Fail to schedule new created shards to default workerGroup for service: 521bc6a5-6438-4970-a8ad-8f468ede2eb0, ignore the error for now. Error:WorkerGroup 0 doesn’t have alive workers
2024-02-26 13:19:03,386 INFO (statistics meta manager|36) [LocalMetastore.buildPartitions():1890] start to build 1 partitions sequentially for table statistics.table_statistic_v1 with 10 replicas
2024-02-26 13:19:03,386 WARN (statistics meta manager|36) [StatisticsMetaManager.createSampleStatisticsTable():161] Failed to create sample statistics, Failed to get primary backend. shard id: 786950
2024-02-26 13:19:03,386 WARN (statistics meta manager|36) [StatisticsMetaManager.refreshStatisticsTable():338] create statistics table table_statistic_v1 failed
2024-02-26 13:19:03,549 INFO (colocate group clone checker|128) [ColocateTableBalancer.matchGroups():903] finished to match colocate group. cost: 0 ms, in lock time: 0 ms
2024-02-26 13:19:04,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [363858] failed. Error: WorkerGroup 0 doesn’t have alive workers. [18756 similar messages omitted]
2024-02-26 13:19:04,851 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():94] caught GRPC exception when sending heartbeat to worker bigdata04:9070, io.grpc.StatusRuntimeException: DEADLINE_EXCEEDED: Deadline exceeded after 4.999978356s. .
2024-02-26 13:19:04,851 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():110] sending heartbeat to worker bigdata04:9070 failed, GRPC:DEADLINE_EXCEEDED: Deadline exceeded after 4.999978356s. .
2024-02-26 13:19:05,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [386473] failed. Error: WorkerGroup 0 doesn’t have alive workers. [19136 similar messages omitted]
2024-02-26 13:19:06,291 INFO (grpc-default-executor-1079|37173) [LogRateLimiter.info():45] On-demand schedule [408760, 408761, 408762, 408763, 408764, 408765, 408766, 408767, 408768, 408769] failed. Error: WorkerGroup 0 doesn’t have alive workers. [18855 similar messages omitted]
2024-02-26 13:19:07,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [431224] failed. Error: WorkerGroup 0 doesn’t have alive workers. [19008 similar messages omitted]
2024-02-26 13:19:08,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [450609] failed. Error: WorkerGroup 0 doesn’t have alive workers. [16402 similar messages omitted]
“fe.log” 70757L, 13522106C 70666,1 99%
2024-02-26 13:19:09,856 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():110] sending heartbeat to worker bigdata05:9070 failed, GRPC:DEADLINE_EXCEEDED: Deadline exceeded after 4.999979947s. .
2024-02-26 13:19:10,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [492508] failed. Error: WorkerGroup 0 doesn’t have alive workers. [16667 similar messages omitted]
2024-02-26 13:19:11,291 INFO (grpc-default-executor-1079|37173) [LogRateLimiter.info():45] On-demand schedule [510446, 510447, 510448, 510449, 510450, 510451, 510452, 510453, 510454, 510455] failed. Error: WorkerGroup 0 doesn’t have alive workers. [15176 similar messages omitted]
2024-02-26 13:19:12,191 INFO (starrocks-mysql-nio-pool-39|37309) [Database.checkDataSizeQuota():442] database[mydatabase] data quota: left bytes: 8388608.000 TB / total: 8388608.000 TB
2024-02-26 13:19:12,191 INFO (starrocks-mysql-nio-pool-39|37309) [Database.checkReplicaQuota():453] database[mydatabase] replica quota: left number: 9223372036854775807 / total: 9223372036854775807
2024-02-26 13:19:12,196 WARN (grpc-default-executor-1083|37306) [ShardManager.createShard():437] Fail to schedule new created shards to default workerGroup for service: 521bc6a5-6438-4970-a8ad-8f468ede2eb0, ignore the error for now. Error:WorkerGroup 0 doesn’t have alive workers
2024-02-26 13:19:12,196 INFO (starrocks-mysql-nio-pool-39|37309) [LocalMetastore.buildPartitions():1890] start to build 1 partitions sequentially for table mydatabase.detail_demo with 10 replicas
2024-02-26 13:19:12,196 WARN (starrocks-mysql-nio-pool-39|37309) [StmtExecutor.handleDdlStmt():1583] DDL statement (CREATE TABLE IF NOT EXISTS detail_demo (
recruit_date DATE NOT NULL COMMENT “YYYY-MM-DD”,
region_num TINYINT COMMENT “range [-128, 127]”,
num_plate SMALLINT COMMENT "range [-32768, 32767] ",
tel INT COMMENT “range [-2147483648, 2147483647]”,
id BIGINT COMMENT “range [-2^63 + 1 ~ 2^63 - 1]”,
password LARGEINT COMMENT “range [-2^127 + 1 ~ 2^127 - 1]”,
name CHAR(20) NOT NULL COMMENT "range char(m),m in (1-255) ",
profile VARCHAR(500) NOT NULL COMMENT “upper limit value 65533 bytes”,
ispass BOOLEAN COMMENT “true/false”)
DUPLICATE KEY(recruit_date, region_num)
DISTRIBUTED BY HASH(recruit_date, region_num)
PROPERTIES (
“storage_volume” = “def_volume”,
“datacache.enable” = “true”,
“datacache.partition_duration” = “1 MONTH”,
“enable_async_write_back” = “false”
)) process failed.
com.starrocks.common.DdlException: Failed to get primary backend. shard id: 786963
at com.starrocks.server.LocalMetastore.buildCreateReplicaTasks(LocalMetastore.java:2034) ~[starrocks-fe.jar:?]
at com.starrocks.server.LocalMetastore.buildCreateReplicaTasks(LocalMetastore.java:2014) ~[starrocks-fe.jar:?]
at com.starrocks.server.LocalMetastore.buildCreateReplicaTasks(LocalMetastore.java:2005) ~[starrocks-fe.jar:?]
at com.starrocks.server.LocalMetastore.buildPartitionsSequentially(LocalMetastore.java:1914) ~[starrocks-fe.jar:?]
at com.starrocks.server.LocalMetastore.buildPartitions(LocalMetastore.java:1892) ~[starrocks-fe.jar:?]
at com.starrocks.server.OlapTableFactory.createTable(OlapTableFactory.java:595) ~[starrocks-fe.jar:?]
at com.starrocks.server.LocalMetastore.createTable(LocalMetastore.java:845) ~[starrocks-fe.jar:?]
at com.starrocks.server.MetadataMgr.createTable(MetadataMgr.java:255) ~[starrocks-fe.jar:?]
at com.starrocks.qe.DDLStmtExecutor$StmtExecutorVisitor.lambda$visitCreateTableStatement$4(DDLStmtExecutor.java:248) ~[starrocks-fe.jar:?]
at com.starrocks.common.ErrorReport.wrapWithRuntimeException(ErrorReport.java:112) ~[starrocks-fe.jar:?]
at com.starrocks.qe.DDLStmtExecutor$StmtExecutorVisitor.visitCreateTableStatement(DDLStmtExecutor.java:247) ~[starrocks-fe.jar:?]
at com.starrocks.qe.DDLStmtExecutor$StmtExecutorVisitor.visitCreateTableStatement(DDLStmtExecutor.java:157) ~[starrocks-fe.jar:?]
at com.starrocks.sql.ast.CreateTableStmt.accept(CreateTableStmt.java:308) ~[starrocks-fe.jar:?]
at com.starrocks.qe.DDLStmtExecutor.execute(DDLStmtExecutor.java:143) ~[starrocks-fe.jar:?]
at com.starrocks.qe.StmtExecutor.handleDdlStmt(StmtExecutor.java:1557) ~[starrocks-fe.jar:?]
at com.starrocks.qe.StmtExecutor.execute(StmtExecutor.java:661) ~[starrocks-fe.jar:?]
at com.starrocks.qe.ConnectProcessor.handleQuery(ConnectProcessor.java:379) ~[starrocks-fe.jar:?]
at com.starrocks.qe.ConnectProcessor.dispatch(ConnectProcessor.java:570) ~[starrocks-fe.jar:?]
at com.starrocks.qe.ConnectProcessor.processOnce(ConnectProcessor.java:848) ~[starrocks-fe.jar:?]
at com.starrocks.mysql.nio.ReadListener.lambda$handleEvent$0(ReadListener.java:69) ~[starrocks-fe.jar:?]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_301]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_301]
at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_301]
2024-02-26 13:19:12,291 INFO (grpc-default-executor-1079|37173) [LogRateLimiter.info():45] On-demand schedule [529881, 529882, 529883, 529884, 529885, 529886, 529887, 529888, 529889, 529890] failed. Error: WorkerGroup 0 doesn’t have alive workers. [16445 similar messages omitted]
2024-02-26 13:19:13,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [550109] failed. Error: WorkerGroup 0 doesn’t have alive workers. [17116 similar messages omitted]
2024-02-26 13:19:13,387 INFO (statistics meta manager|36) [StatisticsMetaManager.createSampleStatisticsTable():139] create sample statistics table start
2024-02-26 13:19:13,387 INFO (statistics meta manager|36) [Database.checkDataSizeQuota():442] database[statistics] data quota: left bytes: 8388608.000 TB / total: 8388608.000 TB
2024-02-26 13:19:13,387 INFO (statistics meta manager|36) [Database.checkReplicaQuota():453] database[statistics] replica quota: left number: 9223372036854775807 / total: 9223372036854775807
2024-02-26 13:19:13,391 WARN (grpc-default-executor-1079|37173) [ShardManager.createShard():437] Fail to schedule new created shards to default workerGroup for service: 521bc6a5-6438-4970-a8ad-8f468ede2eb0, ignore the error for now. Error:WorkerGroup 0 doesn’t have alive workers
2024-02-26 13:19:13,391 INFO (statistics meta manager|36) [LocalMetastore.buildPartitions():1890] start to build 1 partitions sequentially for table statistics.table_statistic_v1 with 10 replicas
2024-02-26 13:19:13,391 WARN (statistics meta manager|36) [StatisticsMetaManager.createSampleStatisticsTable():161] Failed to create sample statistics, Failed to get primary backend. shard id: 786976
2024-02-26 13:19:13,392 WARN (statistics meta manager|36) [StatisticsMetaManager.refreshStatisticsTable():338] create statistics table table_statistic_v1 failed
2024-02-26 13:19:14,291 INFO (StarMgrMetaSyncer|57) [LogRateLimiter.info():45] On-demand schedule [569050] failed. Error: WorkerGroup 0 doesn’t have alive workers. [16027 similar messages omitted]
2024-02-26 13:19:14,860 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():94] caught GRPC exception when sending heartbeat to worker bigdata01:9070, io.grpc.StatusRuntimeException: DEADLINE_EXCEEDED: Deadline exceeded after 4.999979303s. .
2024-02-26 13:19:14,861 WARN (pool-28-thread-1|113) [StarletAgent.heartbeat():110] sending heartbeat to worker bigdata01:9070 failed, GRPC:DEADLINE_EXCEEDED: Deadline exceeded after 4.999979303s. .
2024-02-26 13:19:15,291 INFO (grpc-default-executor-1083|37306) [LogRateLimiter.info():45] On-demand schedule [587809, 587810, 587811, 587812, 587813, 587814, 587815, 587816, 587817, 587818] failed. Error: WorkerGroup 0 doesn’t have alive workers. [15871 similar messages omitted]


 对应9070活着,而且Telnet也是通的。fe上也没有开启代理
对应9070活着,而且Telnet也是通的。fe上也没有开启代理