
为了更快的定位您的问题,请提供以下信息,谢谢
【详述】
过程描述:
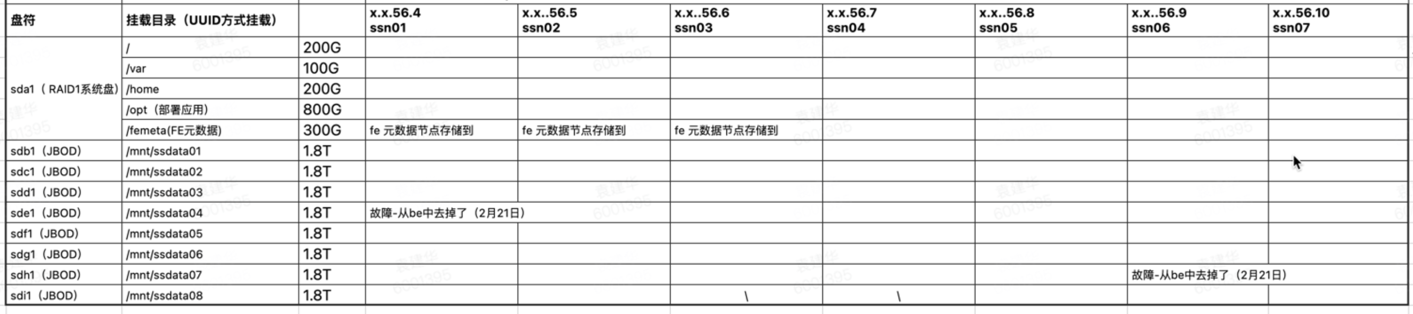
- 春节期间机房断电一次,SR集群是在运行中直接断电的。断电之后平台并未使用,经过大约一周之后上班后发现starrocks访问异常。2月21日找找现场运维去机房查看,发现集群7个节点全部开机状态,但是其中2个节点ssh连不上。分别是xx.xx.56.4和xx.xx.56.8; 推断: 加点之后机器自动开机。两个节点磁盘故障导致开机异常。注释掉fstab中磁盘挂载项(如下面集群配置)。
- 开机之后,启动be,启动fe。
- 运行两天之后发现平台访问不了报错:“SQL 错误 [1064] [42000]: (JE 18.3.16) Could not determine master from helpers at:[/xx.xx.56.6:19010, /xx.xx.56.5:19010]”
- 发现fe尾气动,启动fe,查看fe http页面。查看里面backend中be状态。其中56.9未启动。
- 想起来未从be配置中去掉坏盘。分别停掉56.4 和56.9的be,修噶配置问点重启。之后be一直启动运行正常。
- 运行大概半小时后发现fe再次不能访问。最后一次 启动后ssn02是leader,ssn01、ssn03是follower.详细看0224日志:fe.log。
- 尝试重启过计策ssn01,ssn02,ssn03的fe节点都是运行一段时间就挂掉了。详细请看附件日志。
【背景】做过哪些操作?
集群配置:

fe 18030 web页面上be的信息。
ssn01 [id: 10005, host: 89.10.56.4, heart_port: 19050, be_port: 19060, http_port: 18040, brpc_port: 18060, state: using, start_time: 2024-02-24 11:28:15, last_report_tablets_time: 2024-02-24 11:59:24, version: 3.2.1-79ee91d]
ssn02 [id: 10006, host: 89.10.56.5, heart_port: 19050, be_port: 19060, http_port: 18040, brpc_port: 18060, state: using, start_time: 2024-02-21 11:58:55, last_report_tablets_time: 2024-02-24 11:58:56, version: 3.2.1-79ee91d]
ssn03 [id: 10007, host: 89.10.56.6, heart_port: 19050, be_port: 19060, http_port: 18040, brpc_port: 18060, state: using, start_time: 2024-02-21 11:58:55, last_report_tablets_time: 2024-02-24 11:58:57, version: 3.2.1-79ee91d]
ssn04 [id: 10008, host: 89.10.56.7, heart_port: 19050, be_port: 19060, http_port: 18040, brpc_port: 18060, state: using, start_time: 2024-02-23 15:07:11, last_report_tablets_time: 2024-02-24 11:59:08, version: 3.2.1-79ee91d]
ssn05 [id: 10009, host: 89.10.56.8, heart_port: 19050, be_port: 19060, http_port: 18040, brpc_port: 18060, state: using, start_time: 2024-02-23 14:24:03, last_report_tablets_time: 2024-02-24 11:59:16, version: 3.2.1-79ee91d]
ssn06 [id: 10010, host: 89.10.56.9, heart_port: 19050, be_port: 19060, http_port: 18040, brpc_port: 18060, state: using, start_time: 2024-02-23 15:07:11, last_report_tablets_time: 2024-02-24 11:59:05, version: 3.2.1-79ee91d]
ssn07 [id: 10023, host: 89.10.56.10, heart_port: 19050, be_port: 19060, http_port: 18040, brpc_port: 18060, state: using, start_time: 2024-02-21 11:59:17, last_report_tablets_time: 2024-02-24 11:58:58, version: 3.2.1-79ee91d]
【业务影响】现在fe启动一段时间就关闭连接不上。三个节点不在循环作为leader,之后replay日志。每次循环,leader会出现下面错误,然后shutdown。
2024-02-24 11:23:51,755 ERROR (JournalWriter|104) [BDBJEJournal.batchWriteCommit():422] failed to commit journal after retried 3 times!
2024-02-24 11:23:51,757 ERROR (JournalWriter|104) [JournalWriter.abortJournalTask():176] failed to commit journal after retried 3 times! txn。
【是否存算分离】否
【StarRocks版本】例如:3.2.1
【集群规模】共7个节点,3fe(1 leader+2follower)+7be(fe与be混部)
【机器信息】48C/256G/双万兆bond0 mod4
【联系方式】yuan419419@163.com,谢谢
【附件】
fe.ssn01.log (614.6 KB) fe.ssn02.log (1.3 MB) fe.ssn03.log (382.0 KB)
一些关键错误信息:
【ssn01 fe.log:】
2024-02-24 11:23:15,998 WARN (heartbeat-mgr-pool-7|143) [Util.getResultForUrl():363] failed to get result from url: http://89.10.56.6:18030/api/bootstrap?cluster_id=1204856447&token=6b9be8f9-48f4-48d5-b6d1-e0a684db2531. connect timed out
2024-02-24 11:23:15,998 WARN (heartbeat-mgr-pool-4|140) [Util.getResultForUrl():363] failed to get result from url: http://89.10.56.5:18030/api/bootstrap?cluster_id=1204856447&token=6b9be8f9-48f4-48d5-b6d1-e0a684db2531. connect timed out
2024-02-24 11:23:19,001 WARN (heartbeat-mgr-pool-6|142) [HeartbeatMgr$BackendHeartbeatHandler.call():315] backend heartbeat got exception, addr: 89.10.56.5:19050
2024-02-24 11:23:19,001 WARN (heartbeat-mgr-pool-2|138) [HeartbeatMgr$BackendHeartbeatHandler.call():315] backend heartbeat got exception, addr: 89.10.56.6:19050
2024-02-24 11:23:19,001 WARN (heartbeat-mgr-pool-0|136) [HeartbeatMgr$BackendHeartbeatHandler.call():315] backend heartbeat got exception, addr: 89.10.56.9:19050 Read timed out
。。。。。。
2024-02-24 11:23:19,006 WARN (heartbeat mgr|27) [HeartbeatMgr.runAfterCatalogReady():164] get bad heartbeat response: type: FRONTEND, status: BAD, msg: got exception, name: 89.10.56.5_19010_1701405543630, queryPort: 0, rpcPort: 0, replayedJournalId: 0, feStartTime: \N, feVersion: null
2024-02-24 11:23:19,007 WARN (heartbeat mgr|27) [HeartbeatMgr.runAfterCatalogReady():164] get bad heartbeat response: type: FRONTEND, status: BAD, msg: got exception, name: 89.10.56.6_19010_1701405551219, queryPort: 0, rpcPort: 0, replayedJournalId: 0, feStartTime: \N, feVersion: null
2024-02-24 11:23:21,747 ERROR (JournalWriter|104) [BDBJEJournal.batchWriteCommit():422] failed to commit journal after retried 1 times! txn[] db[CloseSafeDatabase{db=2679028}]
2024-02-24 11:23:41,752 WARN (JournalWriter|104) [BDBJEJournal.rebuildCurrentTransaction():444] transaction is invalid, rebuild the txn with 1 kvs
2024-02-24 11:23:36,751 ERROR (JournalWriter|104) [BDBJEJournal.batchWriteCommit():422] failed to commit journal after retried 2 times! txn[] db[CloseSafeDatabase{db=2679028}]
2024-02-24 11:23:41,752 WARN (JournalWriter|104) [BDBJEJournal.rebuildCurrentTransaction():444] transaction is invalid, rebuild the txn with 1 kvs
2024-02-24 11:23:51,755 ERROR (JournalWriter|104) [BDBJEJournal.batchWriteCommit():422] failed to commit journal after retried 3 times! txn[] db[CloseSafeDatabase{db=2679028}]
2024-02-24 11:23:51,756 WARN (JournalWriter|104) [BDBJEJournal.batchWriteAbort():480] failed to abort transaction because no running transaction, will just ignore and return.
2024-02-24 11:23:51,757 ERROR (JournalWriter|104) [JournalWriter.abortJournalTask():176] failed to commit journal after retried 3 times! txn[] db[CloseSafeDatabase{db=2679028}]
2024-02-24 11:23:51,759 INFO (Thread-100|181) [StarRocksFE.lambda$addShutdownHook$1():390] start to execute shutdown hook
2024-02-24 11:23:51,778 INFO (Thread-100|181) [StarRocksFE.lambda$addShutdownHook$1():415] shutdown hook end
2024-02-24 11:29:06,893 INFO (main|1) [StarRocksFE.start():129] StarRocks FE starting, version: 3.2.1-79ee91d
2024-02-24 11:29:10,794 WARN (replayer|98) [BDBJournalCursor.wrapDatabaseException():85] failed to get DB names for 1 times!Got RestartRequiredException, will exit.
com.sleepycat.je.rep.RollbackException: (JE 18.3.16) Environment must be closed, caused by: com.sleepycat.je.rep.RollbackException: Environment invalid because of previous exception: (JE 18.3.16) 89.10.56.4_19010_1701405127320(1):/femeta/meta/bdb Node 89.10.56.4_19010_1701405127320(1):/femeta/meta/bdb must rollback 2 total commits(1 of which were durable) to the earliest point indicated by transaction id=-5192901 time=2024-02-24 11:23:41.718 vlsn=6,317,716 lsn=0xfb/0x136f68 durable=false in order to rejoin the replication group. All existing ReplicatedEnvironment handles must be closed and reinstantiated. Log files were truncated to file 0x251, offset 0x1273660, vlsn 6,317,715 HARD_RECOVERY: Rolled back past transaction commit or abort. Must run recovery by re-opening Environment handles Environment is invalid and must be closed. Originally thrown by HA thread: REPLICA 89.10.56.4_19010_1701405127320(1) Originally thrown by HA thread: REPLICA 89.10.56.4_19010_1701405127320(1) Environment invalid because of previous exception: (JE 18.3.16) 89.10.56.4_19010_1701405127320(1):/femeta/meta/bdb Node 89.10.56.4_19010_1701405127320(1):/femeta/meta/bdb must rollback 2 total commits(1 of which were durable) to the earliest point indicated by transaction id=-5192901 time=2024-02-24 11:23:41.718 vlsn=6,317,716 lsn=0xfb/0x136f68 durable=false in order to rejoin the replication group. All existing ReplicatedEnvironment handles must be closed and reinstantiated. Log files were truncated to file 0x251, offset 0x1273660, vlsn 6,317,715 HARD_RECOVERY: Rolled back past transaction commit or abort. Must run recovery by re-opening Environment handles Environment is invalid and must be closed. Originally thrown by HA thread: REPLICA 89.10.56.4_19010_1701405127320(1) Originally thrown by HA thread: REPLICA 89.10.56.4_19010_1701405127320(1)
2024-02-24 11:29:10,820 WARN (replayer|98) [GlobalStateMgr$5.runOneCycle():2193] got interrupt exception or inconsistent exception when replay journal 2679028, will exit,
com.starrocks.journal.JournalInconsistentException: failed to get DB names for 1 times!Got RestartRequiredException, will exit.
2024-02-24 11:30:15,028 INFO (UNKNOWN 89.10.56.4_19010_1701405127320(-1)|1) [GlobalStateMgr.waitForReady():1206] wait globalStateMgr to be ready. FE type: FOLLOWER. is ready: true
【ssn02 fe.log:】
2024-02-24 11:23:53,758 WARN (REPLICA 89.10.56.5_19010_1701405543630(2)|76) [StateChangeExecutor.notifyNewFETypeTransfer():62] notify new FE type transfer: UNKNOWN
2024-02-24 11:23:53,760 INFO (stateChangeExecutor|87) [StateChangeExecutor.runOneCycle():85] begin to transfer FE type from FOLLOWER to UNKNOWN
2024-02-24 11:23:53,761 WARN (stateChangeExecutor|87) [GlobalStateMgr.transferToNonLeader():1463] FOLLOWER to UNKNOWN, still offer read service
2024-02-24 11:23:53,761 WARN (UNKNOWN 89.10.56.5_19010_1701405543630(2)|76) [StateChangeExecutor.notifyNewFETypeTransfer():62] notify new FE type transfer: LEADER
2024-02-24 11:23:53,761 INFO (stateChangeExecutor|87) [StateChangeExecutor.runOneCycle():179] finished to transfer FE type from FOLLOWER to UNKNOWN
2024-02-24 11:23:53,762 INFO (stateChangeExecutor|87) [StateChangeExecutor.runOneCycle():85] begin to transfer FE type from UNKNOWN to LEADER
2024-02-24 11:23:53,763 ERROR (replayer|102) [Daemon.run():130] daemon thread exits. name=replayer
2024-02-24 11:23:53,764 INFO (replayer|102) [GlobalStateMgr$5.run():2258] quit replay at 2679245
2024-02-24 11:23:53,852 INFO (stateChangeExecutor|87) [BDBHA.fencing():94] start fencing, epoch number is 19
2024-02-24 11:23:56,079 WARN (heartbeat-mgr-pool-3|260) [Util.getResultForUrl():363] failed to get result from url: http://89.10.56.4:18030/api/bootstrap?cluster_id=1204856447&token=6b9be8f9-48f4-48d5-b6d1-e0a684db2531. connect timed out
2024-02-24 11:23:59,002 WARN (heartbeat-mgr-pool-0|257) [HeartbeatMgr$BackendHeartbeatHandler.call():315] backend heartbeat got exception, addr: 89.10.56.4:19050 connect timed out
2024-02-24 11:23:59,006 WARN (heartbeat-mgr-pool-5|262) [HeartbeatMgr$BackendHeartbeatHandler.call():315] backend heartbeat got exception, addr: 89.10.56.8:19050 connect timed out
2024-02-24 11:23:59,006 WARN (heartbeat-mgr-pool-6|263) [HeartbeatMgr$BackendHeartbeatHandler.call():315] backend heartbeat got exception, addr: 89.10.56.9:19050 connect timed out
2024-02-24 11:23:59,005 WARN (heartbeat-mgr-pool-4|261) [HeartbeatMgr$BackendHeartbeatHandler.call():315] backend heartbeat got exception, addr: 89.10.56.7:19050 connect timed out
2024-02-24 11:23:59,027 WARN (heartbeat mgr|27) [HeartbeatMgr.runAfterCatalogReady():164] get bad heartbeat response: type: BACKEND, status: BAD, msg: java.net.SocketTimeoutException: connect timed out
2024-02-24 11:23:59,027 WARN (heartbeat mgr|27) [HeartbeatMgr.runAfterCatalogReady():164] get bad heartbeat response: type: BACKEND, status: BAD, msg: java.net.SocketTimeoutException: connect timed out
2024-02-24 11:23:59,027 WARN (heartbeat mgr|27) [HeartbeatMgr.runAfterCatalogReady():164] get bad heartbeat response: type: BACKEND, status: BAD, msg: java.net.SocketTimeoutException: connect timed out
2024-02-24 11:23:59,029 WARN (heartbeat mgr|27) [HeartbeatMgr.runAfterCatalogReady():164] get bad heartbeat response: type: BACKEND, status: BAD, msg: java.net.SocketTimeoutException: connect timed out
2024-02-24 11:23:59,031 WARN (heartbeat mgr|27) [HeartbeatMgr.runAfterCatalogReady():164] get bad heartbeat response: type: FRONTEND, status: BAD, msg: got exception, name: 89.10.56.4_19010_1701405127320, queryPort: 0, rpcPort: 0, replayedJournalId: 0, feStartTime: \N, feVersion: null
2024-02-24 11:24:06,044 WARN (heartbeat-mgr-pool-3|260) [Util.getResultForUrl():363] failed to get result from url: http://89.10.56.4:18030/api/bootstrap?cluster_id=1204856447&token=6b9be8f9-48f4-48d5-b6d1-e0a684db2531. connect timed out
2024-02-24 11:24:06,145 WARN (PortConnectivityChecker|28) [PortConnectivityChecker.runAfterCatalogReady():110] checking for connectivity of 89.10.56.4:19020 failed, not open
2024-02-24 11:24:06,147 WARN (PortConnectivityChecker|28) [PortConnectivityChecker.runAfterCatalogReady():110] checking for connectivity of 89.10.56.4:19010 failed, not open
2024-02-24 12:06:50,194 WARN (heartbeat-mgr-pool-7|264) [HeartbeatMgr$BackendHeartbeatHandler.call():315] backend heartbeat got exception, addr: 89.10.56.4:19050
2024-02-24 12:07:00,207 WARN (heartbeat-mgr-pool-6|263) [HeartbeatMgr$BackendHeartbeatHandler.call():315] backend heartbeat got exception, addr: 89.10.56.7:19050
2024-02-24 12:07:00,207 WARN (heartbeat-mgr-pool-2|259) [HeartbeatMgr$BackendHeartbeatHandler.call():315] backend heartbeat got exception, addr: 89.10.56.4:19050
2024-02-24 12:07:10,218 WARN (heartbeat-mgr-pool-7|264) [HeartbeatMgr$BackendHeartbeatHandler.call():315] backend heartbeat got exception, addr: 89.10.56.7:19050
2024-02-24 12:07:10,218 WARN (heartbeat-mgr-pool-2|259) [HeartbeatMgr$BackendHeartbeatHandler.call():315] backend heartbeat got exception, addr: 89.10.56.9:19050
2024-02-24 12:07:10,219 WARN (heartbeat-mgr-pool-5|262) [HeartbeatMgr$BackendHeartbeatHandler.call():315] backend heartbeat got exception, addr: 89.10.56.4:19050
2024-02-24 12:07:10,218 WARN (heartbeat-mgr-pool-4|261) [HeartbeatMgr$BackendHeartbeatHandler.call():315] backend heartbeat got exception, addr: 89.10.56.8:19050
2024-02-24 12:10:14,829 ERROR (JournalWriter|226) [BDBJEJournal.batchWriteBegin():322] failed to begin txn after retried 1 times! db = CloseSafeDatabase{db=2679246}
com.sleepycat.je.rep.InsufficientReplicasException: (JE 18.3.16) Commit policy: SIMPLE_MAJORITY required 1 replica. But none were active with this master.
2024-02-24 12:10:29,830 ERROR (JournalWriter|226) [BDBJEJournal.batchWriteBegin():322] failed to begin txn after retried 2 times! db = CloseSafeDatabase{db=2679246}
com.sleepycat.je.rep.InsufficientReplicasException: (JE 18.3.16) Commit policy: SIMPLE_MAJORITY required 1 replica. But none were active with this master.
2024-02-24 12:10:30,389 ERROR (heartbeat mgr|27) [Daemon.run():117] daemon thread got exception. name: heartbeat mgr
com.sleepycat.je.rep.UnknownMasterException: java.lang.Exception: Stacktrace where exception below was rethrown (com.sleepycat.je.rep.UnknownMasterException)
(JE 18.3.16) Node 89.10.56.5_19010_1701405543630(2):/femeta/meta/bdb is not a master anymore Originally thrown by HA thread: MASTER 89.10.56.5_19010_1701405543630(2)
2024-02-24 12:10:30,388 WARN (MASTER 89.10.56.5_19010_1701405543630(2)|76) [StateChangeExecutor.notifyNewFETypeTransfer():62] notify new FE type transfer: UNKNOWN
2024-02-24 12:10:30,389 INFO (stateChangeExecutor|87) [StateChangeExecutor.runOneCycle():85] begin to transfer FE type from LEADER to UNKNOWN
2024-02-24 12:10:30,389 ERROR (heartbeat mgr|27) [Daemon.run():117] daemon thread got exception. name: heartbeat mgr
com.sleepycat.je.rep.UnknownMasterException: java.lang.Exception: Stacktrace where exception below was rethrown (com.sleepycat.je.rep.UnknownMasterException)
(JE 18.3.16) Node 89.10.56.5_19010_1701405543630(2):/femeta/meta/bdb is not a master anymore Originally thrown by HA thread: MASTER 89.10.56.5_19010_1701405543630(2)
2024-02-24 12:10:30,391 ERROR (stateChangeExecutor|87) [StateChangeExecutor.runOneCycle():171] transfer FE type from LEADER to UNKNOWN. exit
2024-02-24 12:10:30,393 INFO (Thread-54|117) [StarRocksFE.lambda$addShutdownHook$1():390] start to execute shutdown hook
2024-02-24 12:10:30,412 WARN (UNKNOWN 89.10.56.5_19010_1701405543630(2)|76) [StateChangeExecutor.notifyNewFETypeTransfer():62] notify new FE type transfer: FOLLOWER
2024-02-24 12:10:30,417 INFO (Thread-54|117) [StarRocksFE.lambda$addShutdownHook$1():415] shutdown hook end
【ssn03 fe.log:】
2024-02-24 11:25:13,571 WARN (port-connectivity-checker-1|101) [PortConnectivityChecker.isPortConnectable():133] socket connection to 89.10.56.4:19010 failed, reason: connect timed out
2024-02-24 11:25:13,571 WARN (port-connectivity-checker-3|103) [PortConnectivityChecker.isPortConnectable():133] socket connection to 89.10.56.4:19020 failed, reason: connect timed out
2024-02-24 11:25:13,572 WARN (PortConnectivityChecker|28) [PortConnectivityChecker.runAfterCatalogReady():110] checking for connectivity of 89.10.56.4:19020 failed, not open
2024-02-24 11:25:13,572 WARN (PortConnectivityChecker|28) [PortConnectivityChecker.runAfterCatalogReady():110] checking for connectivity of 89.10.56.4:19010 failed, not open
。。。 。。。
2024-02-24 12:07:53,570 WARN (tablet stat mgr|42) [TabletStatMgr.updateLocalTabletStat():158] task exec error. backend[10008]
2024-02-24 12:08:25,315 WARN (tablet stat mgr|42) [TabletStatMgr.updateLocalTabletStat():158] task exec error. backend[10009]
2024-02-24 12:08:57,058 WARN (tablet stat mgr|42) [TabletStatMgr.updateLocalTabletStat():158] task exec error. backend[10010]
2024-02-24 12:09:57,835 WARN (REPLICA 89.10.56.6_19010_1701405551219(3)|76) [StateChangeExecutor.notifyNewFETypeTransfer():62] notify new FE type transfer: UNKNOWN
2024-02-24 12:09:57,836 INFO (stateChangeExecutor|86) [StateChangeExecutor.runOneCycle():85] begin to transfer FE type from FOLLOWER to UNKNOWN
2024-02-24 12:09:57,837 WARN (stateChangeExecutor|86) [GlobalStateMgr.transferToNonLeader():1463] FOLLOWER to UNKNOWN, still offer read service
2024-02-24 12:09:57,837 INFO (stateChangeExecutor|86) [StateChangeExecutor.runOneCycle():179] finished to transfer FE type from FOLLOWER to UNKNOWN
2024-02-24 12:09:57,838 WARN (UNKNOWN 89.10.56.6_19010_1701405551219(3)|76) [StateChangeExecutor.notifyNewFETypeTransfer():62] notify new FE type transfer: LEADER
2024-02-24 12:09:57,838 INFO (stateChangeExecutor|86) [StateChangeExecutor.runOneCycle():85] begin to transfer FE type from UNKNOWN to LEADER
2024-02-24 12:09:57,840 ERROR (replayer|98) [Daemon.run():130] daemon thread exits. name=replayer
2024-02-24 12:10:00,154 ERROR (leaderCheckpointer|345) [Checkpoint.runAfterCatalogReady():138] Exception when pushing image file. url = http://89.10.56.5:18030/put?version=2680036&port=18030&subdir=
java.io.IOException: Server returned HTTP response code: 400 for URL: http://89.10.56.5:18030/put?version=2680036&port=18030&subdir=
2024-02-24 12:10:03,090 WARN (heartbeat-mgr-pool-5|380) [HeartbeatMgr$BackendHeartbeatHandler.call():315] backend heartbeat got exception, addr: 89.10.56.8:19050 connect timed out
2024-02-24 12:10:03,090 WARN (heartbeat-mgr-pool-4|379) [HeartbeatMgr$BackendHeartbeatHandler.call():315] backend heartbeat got exception, addr: 89.10.56.7:19050 connect timed out
2024-02-24 12:10:03,090 WARN (heartbeat-mgr-pool-6|381) [HeartbeatMgr$BackendHeartbeatHandler.call():315] backend heartbeat got exception, addr: 89.10.56.9:19050 connect timed out
2024-02-24 12:10:13,105 ERROR (JournalWriter|344) [BDBJEJournal.batchWriteCommit():422] failed to commit journal after retried 1 times! txn[] db[CloseSafeDatabase{db=2680037}]
2024-02-24 12:10:28,109 ERROR (JournalWriter|344) [BDBJEJournal.batchWriteCommit():422] failed to commit journal after retried 2 times! txn[] db[CloseSafeDatabase{db=2680037}]
2024-02-24 12:10:43,113 WARN (JournalWriter|344) [BDBJEJournal.batchWriteCommit():404] failed to commit journal after retried 3 times! failed to rebuild txn
Caused by: com.sleepycat.je.rep.InsufficientReplicasException: (JE 18.3.16) Commit policy: SIMPLE_MAJORITY required 1 replica. But none were active with this master.
2024-02-24 12:10:43,114 WARN (JournalWriter|344) [BDBJEJournal.batchWriteAbort():480] failed to abort transaction because no running transaction, will just ignore and return.
2024-02-24 12:10:43,114 ERROR (JournalWriter|344) [JournalWriter.abortJournalTask():176] failed to rebuild txn! txn[] db[CloseSafeDatabase{db=2680037}]
2024-02-24 12:10:43,116 INFO (Thread-54|113) [StarRocksFE.lambda$addShutdownHook$1():390] start to execute shutdown hook
2024-02-24 12:10:43,132 INFO (Thread-54|113) [StarRocksFE.lambda$addShutdownHook$1():415] shutdown hook end