
故障触发源:上线了一个 qps为2的sql,其中主表每天2000w数据,bucket数为15。sql查询2天的数据,使用主键过滤以后,只剩6w条数据进行后续计算。该sql手动执行只用了200ms。通过profile分析,在计算的过程耗时也很短,200ms主要在scan 和exchange的IO中。后续用bucket=10获取的profile:验证-profile.txt (172.4 KB)
上线后:整个集群的sql的延迟都开始飚高,FE的connection飚高到单用户上限。
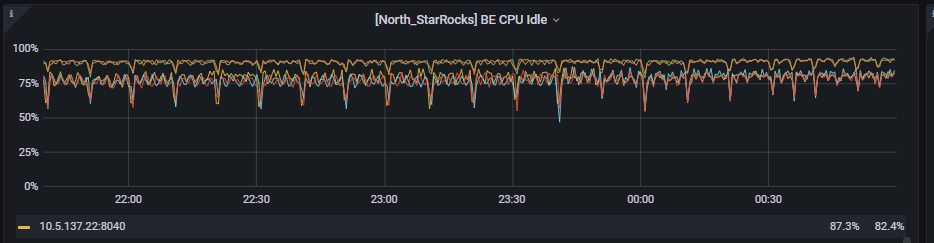
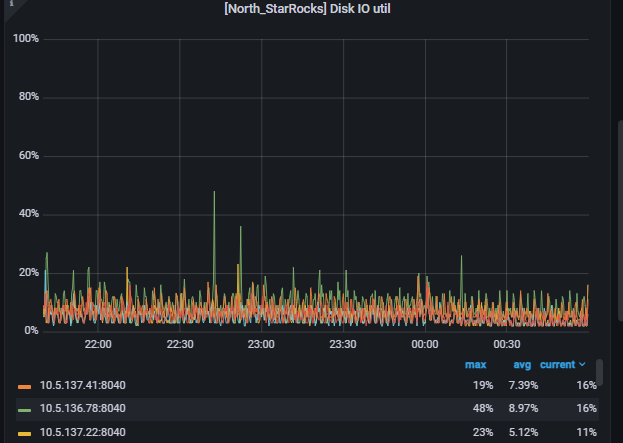
硬件指标却都很空闲:CPU、内存使用率最多40%,IO UTIL也才20%上下。网络也才最多的时候也才20MB/s左右(万兆网卡)。这些指标和正常的时候差别不大,甚至比正常的时候还要良好。
故障的临时解决:将表的bucket数降到10以后,就恢复正常了。
问题:想请教下这个瓶颈在哪里?还有除了分析的硬件外,还有哪些参数会导致上面的情况?想避免下次新需求上线产生的问题。
【是否存算分离】否
【StarRocks版本】2.5.6
【集群规模】
3fe(1 follower+2observer)+5be
FE: 8C 32G
BE: 32C 64G
【监控信息】
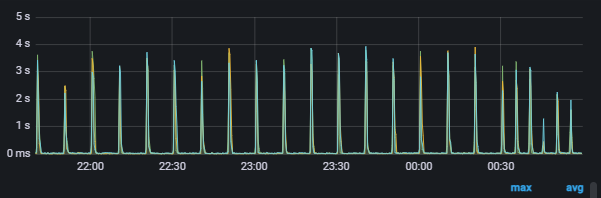
查询延迟快到4s:
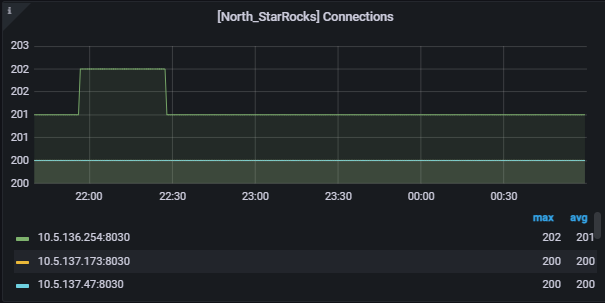
FE connections都到了200:
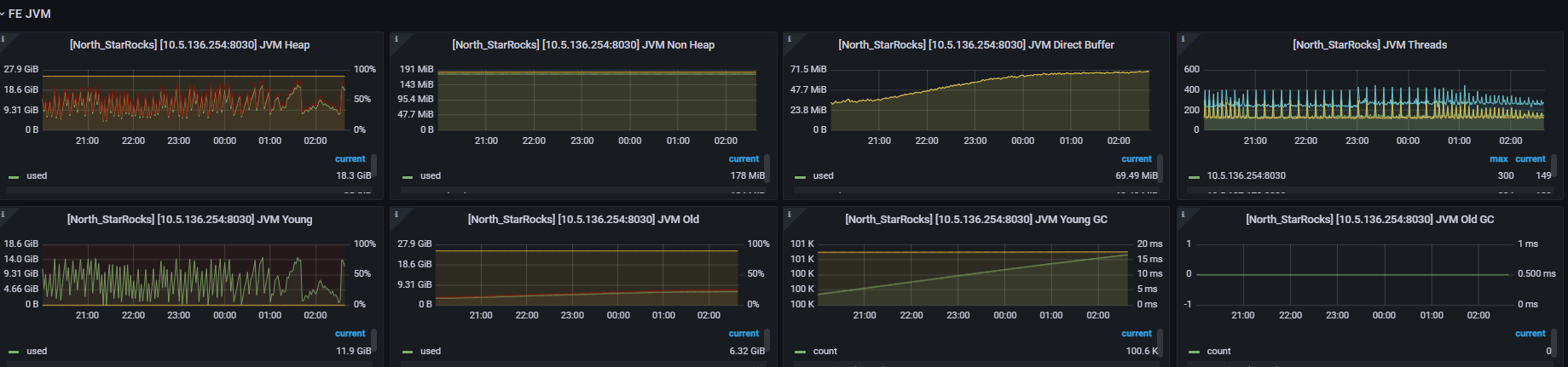
FE jvm监控:
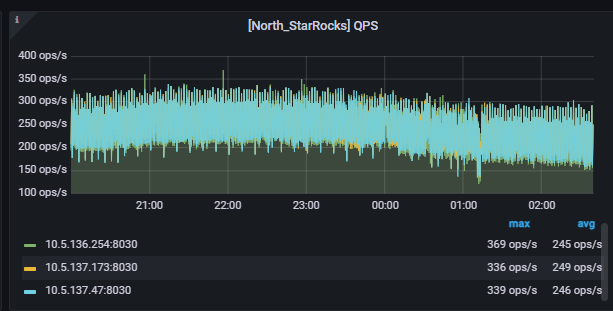
每个FE的QPS(和正常时间差别也不大,新sql只贡献了2qps):
BE内存:

BE cpu的空闲程度:
IO util:
流量:
