【问题咨询】
StarRocks 是因为什么原因导致以下异常?我们上了资源隔离,发现资源隔离有以下几个问题。
1、CPU是软隔离,导致无法更好的分配各个业务系统的资源限制,根据官网资源隔离介绍:如果当前 BE 节点资源非满载,则各个资源组能分配的资源是资源的总资源,但是满载的时候又是分配的是具体设置的资源组限制。
2、每个资源组我理解也是相对独立,互不影响,但是我们在实际使用的时候发现,如果A资源组使用率过大,B资源组会查询不动,有些简单的小查询也会报错SQL超时。
在我们最近的异常发现如下几点,发现业务的一个大查询导致其它业务查询不动的情况,实际CPU内存还有空闲剩余,为什么会发生这种情况?
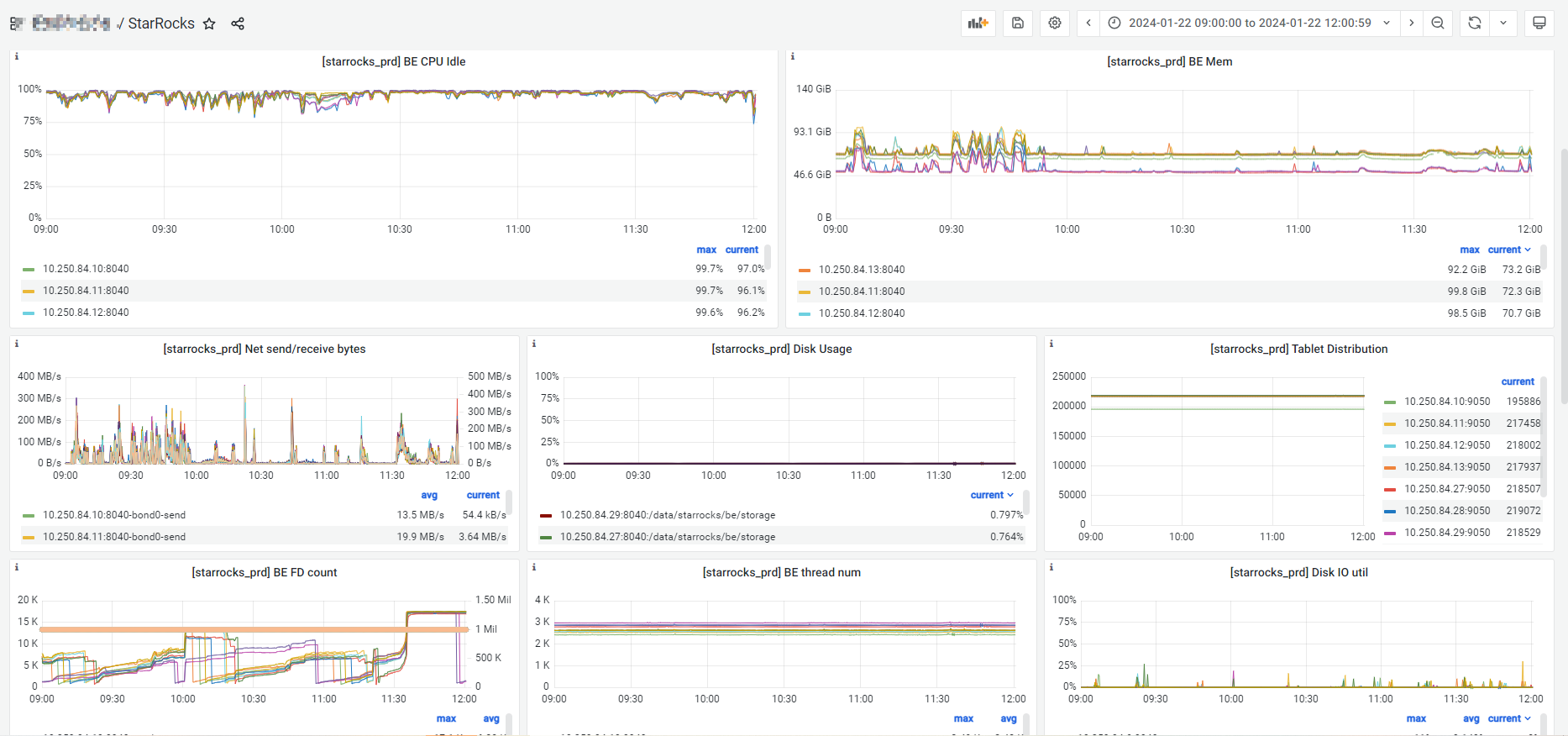
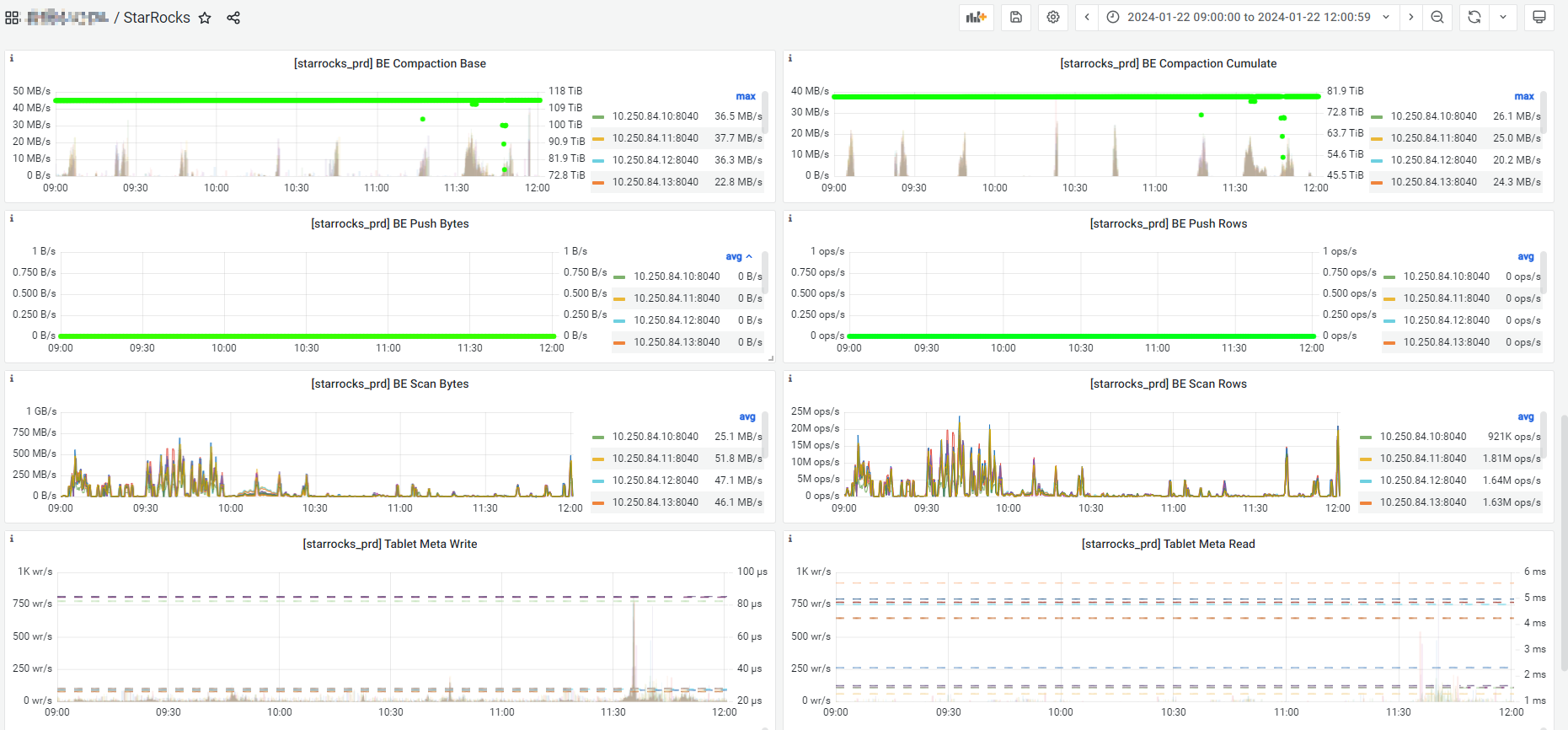
A、2024年1月22日09:00:00 - 2024年1月22日10:00:00 开始大批量SQL超时报错,查看监控FE、BE内存监控正常。当时是运行一个查询SQL大概是15s左右(以前是正常是3-4s),最后重启整个FE+BE后恢复。
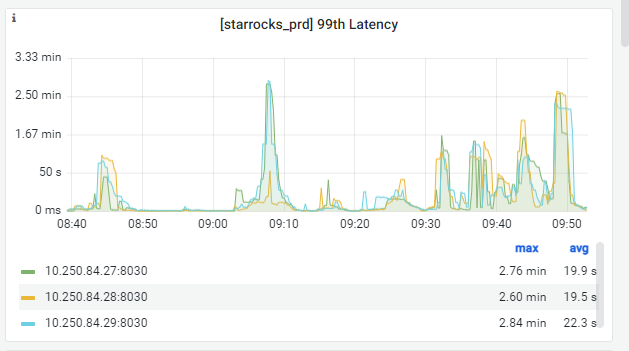
B、2024年1月22日11:37:00 - 2024年1月21日11:40:00 有部分业务报错SQL超时,查看fe.audit.log,发现查询被取消。

C、另外关于StarRocks监控,这两个监控是有问题吗?
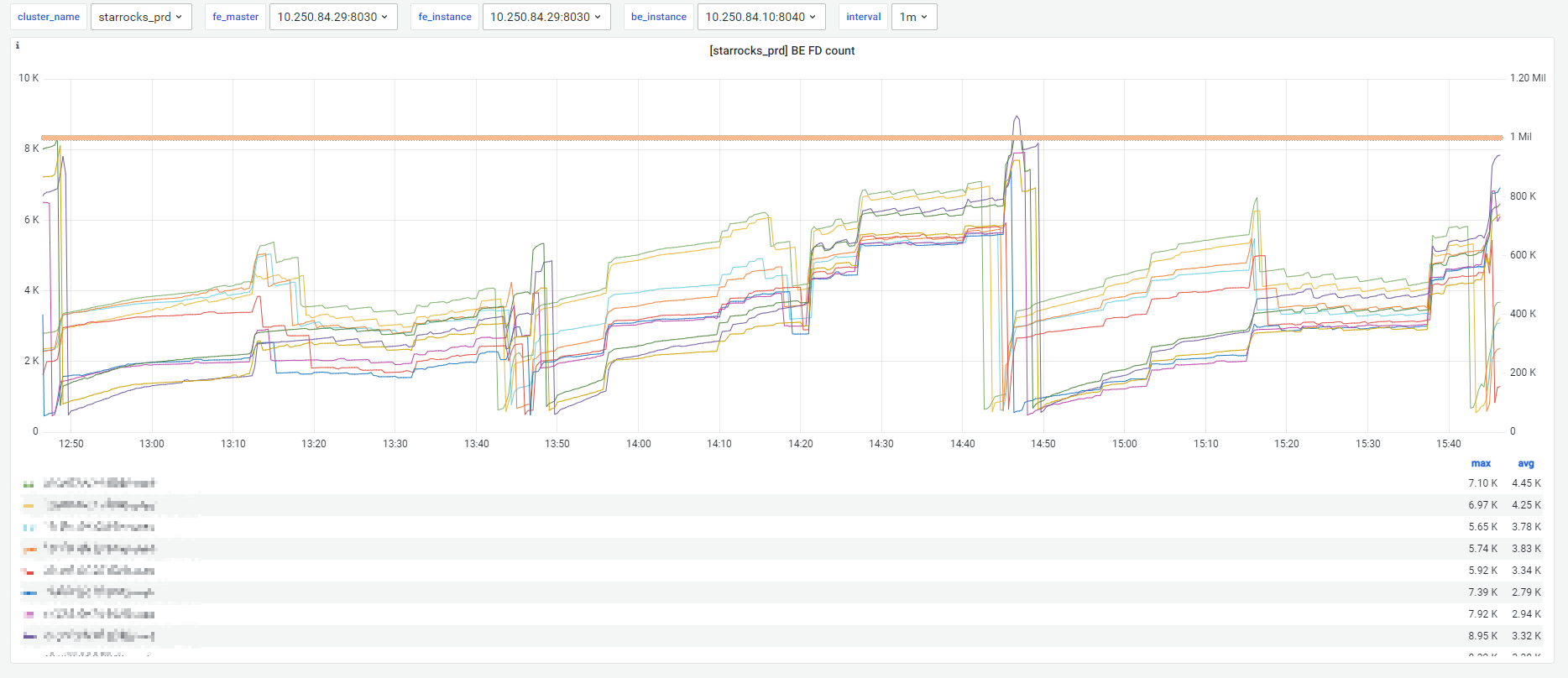
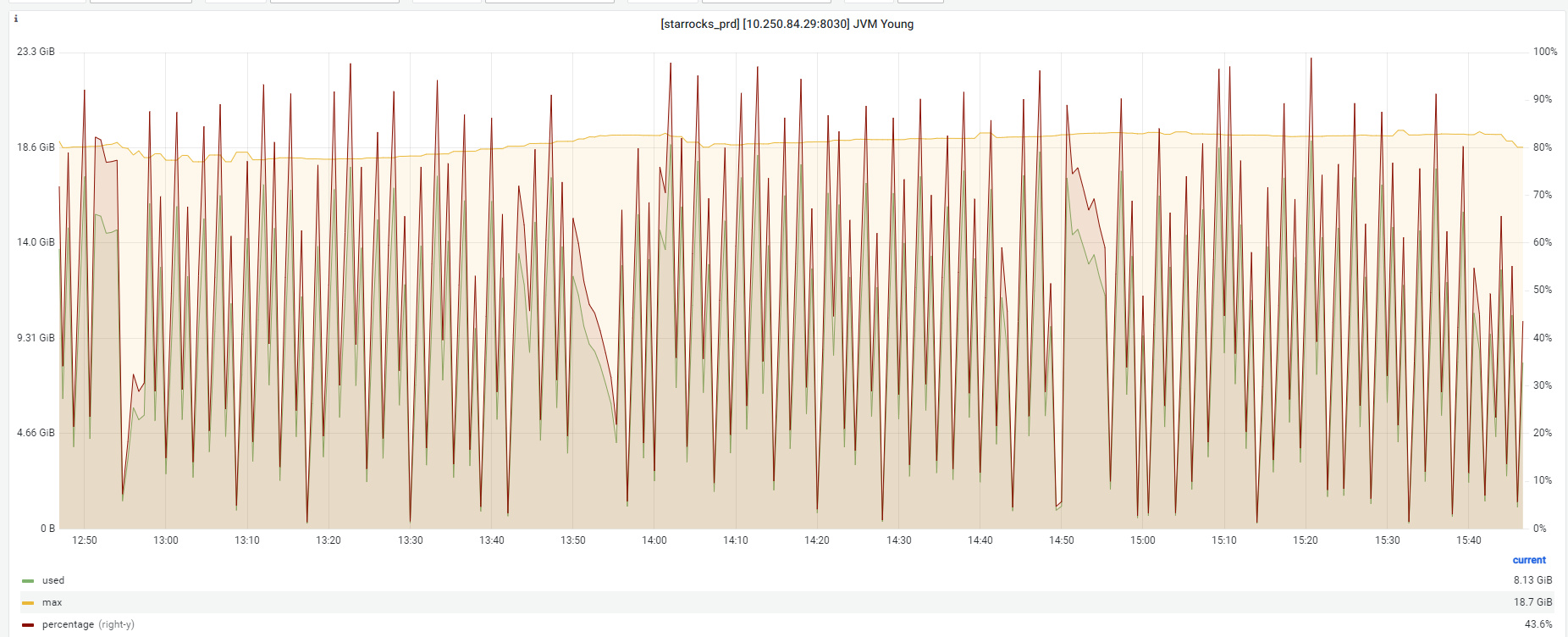
【StarRocks版本】2.5.8
【集群规模】3fe+10be(fe与be混部)
【机器信息】:96C/256G/万兆