为了更快的定位您的问题,请提供以下信息,谢谢
【详述】突发fe节点异常下线了1h
【背景】什么也没做
【业务影响】1%以内的query error rate
【是否存算分离】否
【StarRocks版本】例如:2.5.6
【集群规模】例如:3fe+4be(fe/be单独部署,报错的是单独后加的be节点)
【机器信息】CPU虚拟核/内存/网卡,例如:32C/64G/万兆
【联系方式】18210052731
【附件】
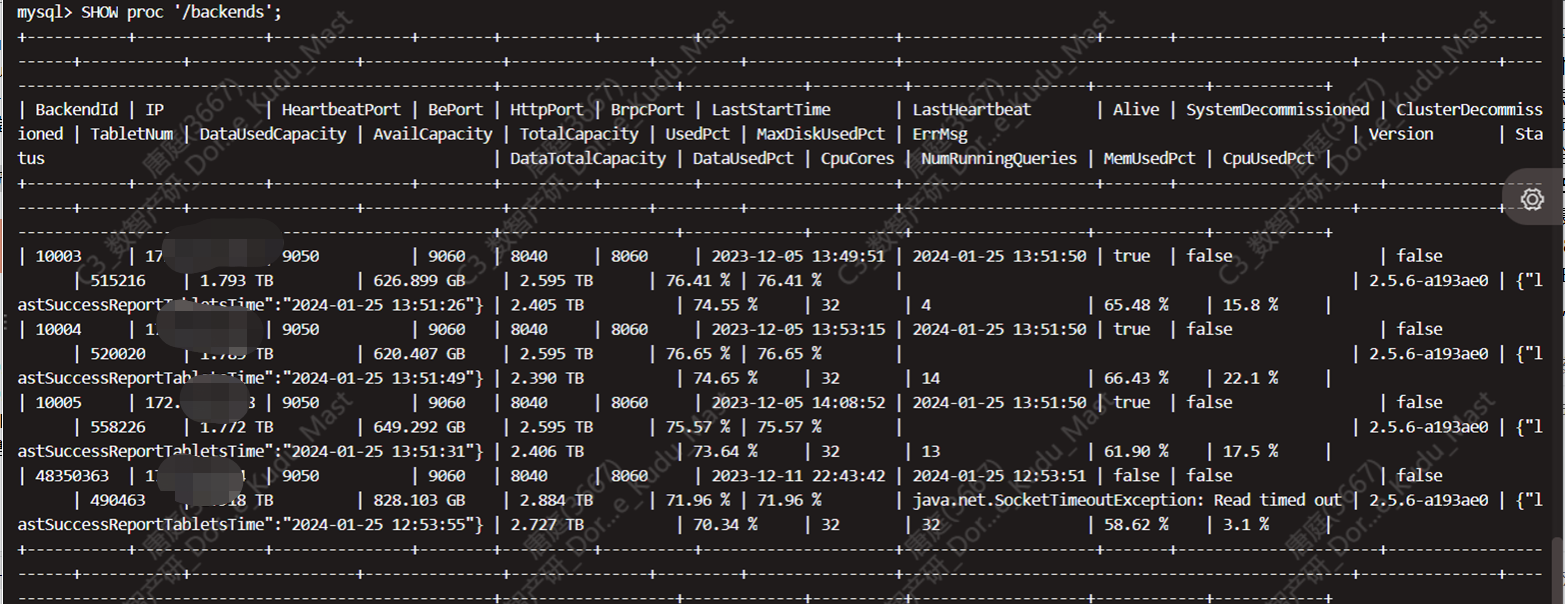
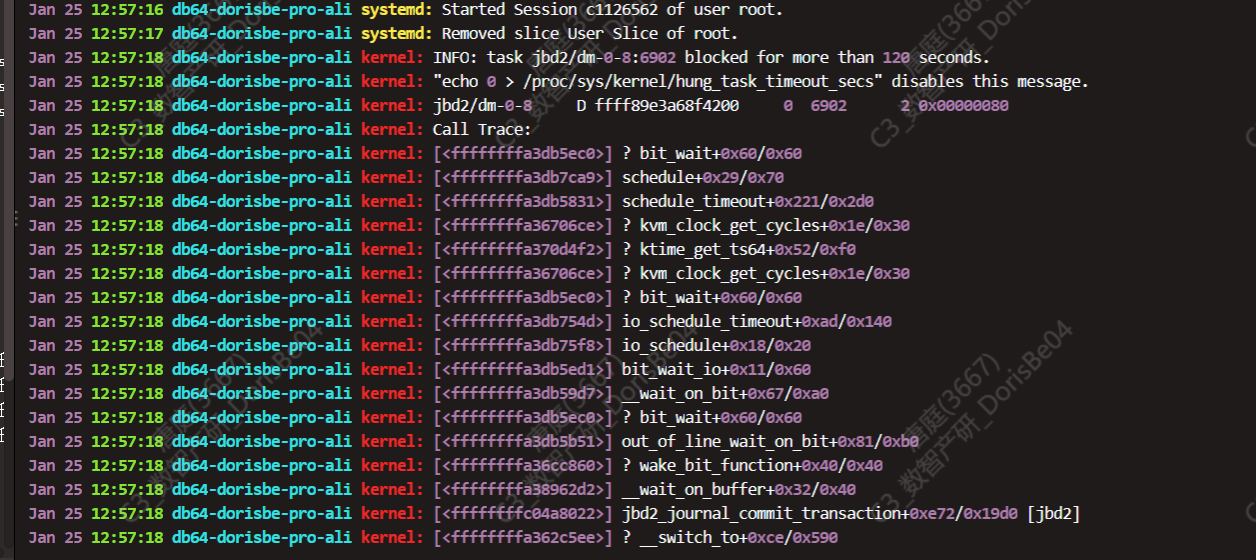
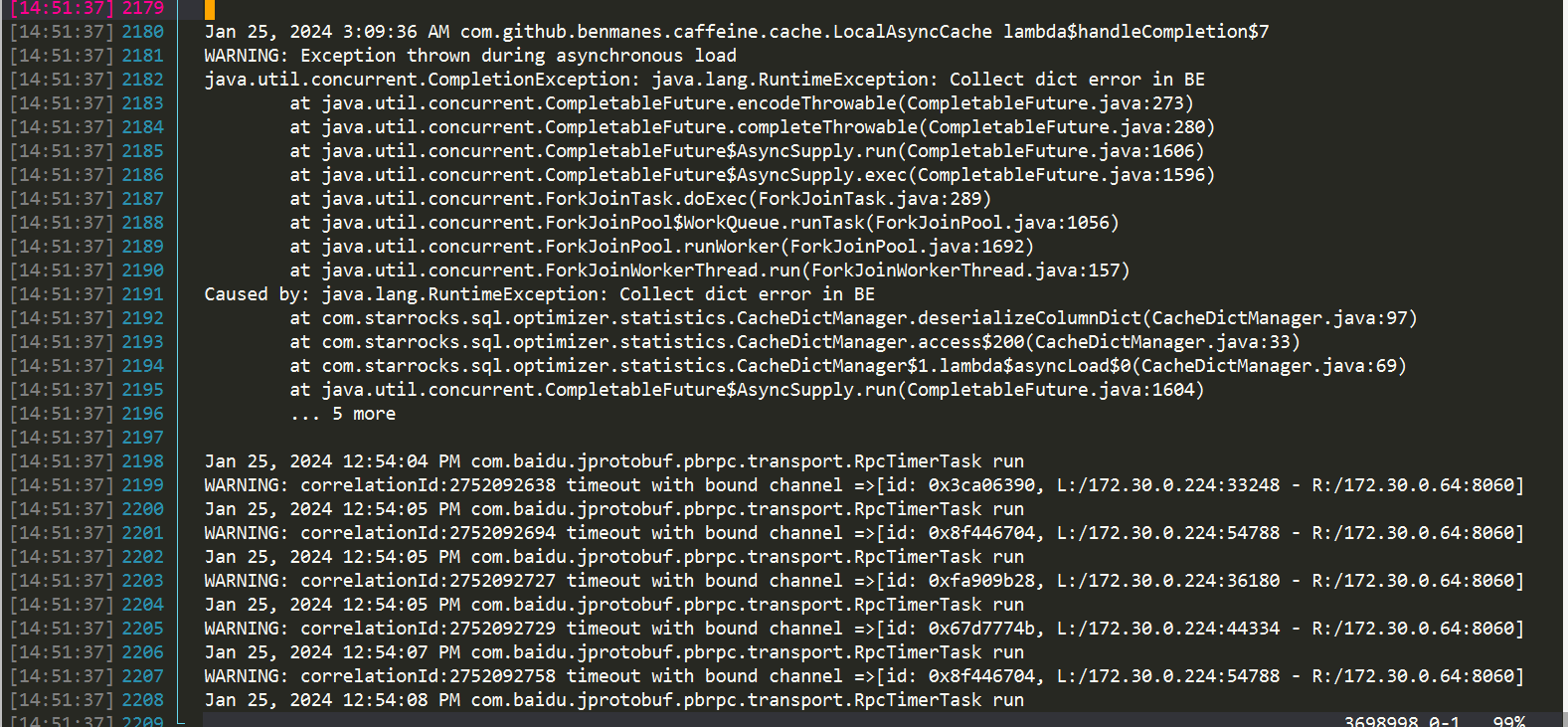
问题持续了1h,正在排查期,自动恢复了。

为了更快的定位您的问题,请提供以下信息,谢谢
【详述】突发fe节点异常下线了1h
【背景】什么也没做
【业务影响】1%以内的query error rate
【是否存算分离】否
【StarRocks版本】例如:2.5.6
【集群规模】例如:3fe+4be(fe/be单独部署,报错的是单独后加的be节点)
【机器信息】CPU虚拟核/内存/网卡,例如:32C/64G/万兆
【联系方式】18210052731
【附件】
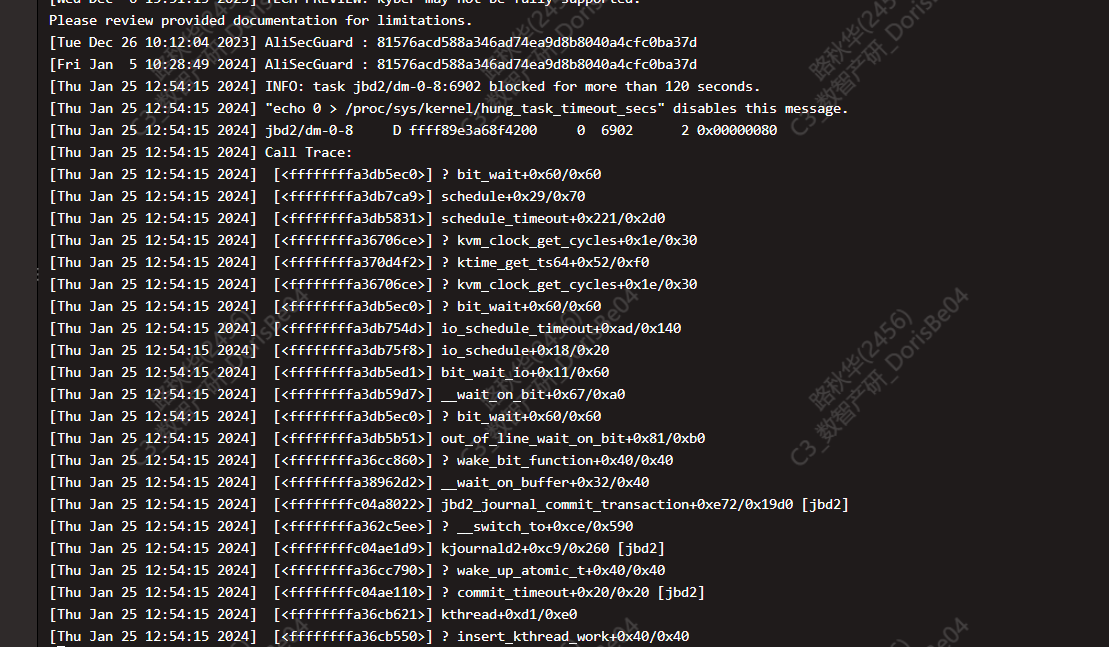
这是be的内核异常了吧,机器重启了?
机器没重启,进程也没重启,就是看到有这么个系统日志。
be进程一直正常,服务器负载也基本正常,单独看下线的be节点没重新加入前也是没任何异常的。
不过看dmesg是内核异常
dmesg的异常时间点不是那么匹配,问题大概在12:54-55,那个信息在12:57了,12:59也出现了同样的信息,然后就没再报任务错误了,但是13:55这个节点才重新加入集群。
dmesg和be.out发下看看
这看起来系统hung住了?可以找阿里云的确认下, be crash一般会在be.out打印信息或者oom会在demsg中显示oom-killer